
sqoop关系型数据迁移原理以及map端内存为何不会爆掉窥探
序:map客户端使用jdbc向数据库发送查询语句,将会拿到所有数据到map的客户端,安装jdbc的原理,数据全部缓存在内存中,但是内存没有出现爆掉情况,这是因为1.3以后,对jdbc进行了优化,改进jdbc内部原理,将数据写入磁盘存储了。

Sqoop是apache旗下一款“Hadoop和关系数据库服务器之间传送数据”的工具。Sqoop架构非常简单,其整合了Hive、Hbase和Oozie,通过map-reduce任务来传输数据,从而提供并发特性和容错。
导入数据:MySQL,Oracle导入数据到Hadoop的HDFS、HIVE、HBASE等数据存储系统。
导出数据:从Hadoop的文件系统中导出数据到关系数据库mysql等。
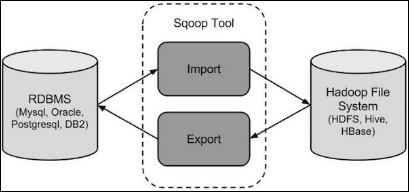
工作机制
将导入或导出命令翻译成mapreduce程序来实现,在翻译出的mapreduce中主要是对inputformat和outputformat进行定制。
Sqoop的数据导入
从RDBMS导入单个表到HDFS。表中的每一行被视为HDFS的记录。所有记录都存储为文本文件的文本数据(或者Avro、sequence文件等二进制数据)
表数据:在mysql中有一个库test中intsmaze表。
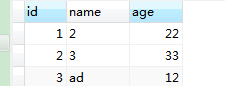
导入intsmaze表数据到HDFS
bin/sqoop import \
--connect jdbc:mysql://192.168.19.131:3306/test \
--username root \
--password hadoop \
--table intsmaze \
--m 1
如果成功执行,那么会得到下面的输出。
17/04/25 03:15:06 INFO mapreduce.Job: Running job: job_1490356790522_0018 17/04/25 03:15:52 INFO mapreduce.Job: Job job_1490356790522_0018 running in uber mode : false 17/04/25 03:15:52 INFO mapreduce.Job: map 0% reduce 0% 17/04/25 03:16:13 INFO mapreduce.Job: map 100% reduce 0% 17/04/25 03:16:14 INFO mapreduce.Job: Job job_1490356790522_0018 completed successfully 17/04/25 03:16:15 INFO mapreduce.Job: Counters: 30 File System Counters...... Job Counters ...... Map-Reduce Framework...... File Input Format Counters Bytes Read=0 File Output Format Counters Bytes Written=22 17/04/25 03:16:15 INFO mapreduce.ImportJobBase: Transferred 22 bytes in 98.332 seconds (0.2237 bytes/sec) 17/04/25 03:16:15 INFO mapreduce.ImportJobBase: Retrieved 3 records.
原理解析:
查看HDFS导入的数据,intsmaze表的数据和字段之间用逗号(,)表示。
1,2,22 2,3,33 3,ad,12
默认情况下,Sqoop会将我们导入的数据保存为逗号分隔的文本文件。如果导入数据的字段内容存在逗号分隔符,我们可以另外指定分隔符,字段包围字符和转义字符。使用命令行参数可以指定分隔符,文件格式,压缩等。支持文本文件(--as-textfile)、avro(--as-avrodatafile)、SequenceFiles(--as-sequencefile)。默认为文本。
Sqoop启动的mapreduce作业会用到一个InputFormat,它可以通过JDBC从一个数据库表中读取部分内容。Hadoop提供的DataDrivenDBInputFormat能够为几个map任务对查询结果进行划分。
使用一个简单的查询通常就可以读取一张表的内容
select col1,col2,... form tablename
但是为了更好的导入性能,可以将查询划分到多个节点上执行。查询时根据一个划分列(确定根据哪一个列划分)来进行划分。根据表中的元数据,Sqoop会选择一个合适的列作为划分列(通常是表的主键)。主键列中的最小值和最大值会被读出,与目标任务数一起来确定每个map任务要执行的查询。当然用户也可以使用split-by参数自己指定一个列作为划分列。
例如:person表中有10000条记录,其id列值为0~9999。在导入这张表时,Sqoop会判断出id是表的主键列。启动MapReduce作业时,用来执行导入的DataDrivenDBInputFormat便会发出一条类似于select min(id),max(id) form intsmaze的查询语句。假设我们制定运行5个map任务(使用-m 5),这样便可以确认每个map任务要执行的查询分别为select id,name,... form intsmaze where id>=0 and id<2000,select id,name,... form intsmaze where id>=2000 and id<4000,...,依次类推。
注意:划分列的选择是影响并行执行效率的重要因素。如果id列的值不是均匀分布的(比如id值从2000到4000的范围是没有记录的),那么有一部分map任务可能只有很少或没有工作要做,而其他任务则有很多工作要做。
严重注意:在1.3之前,map的并行度一定要设置好,因为map客户端会向数据库发送查询语句,将会拿到所有数据到map的客户端缓存到,然后在执行map()方法一条一条处理,所有如果设置不好,一个map拿到的表数据过大就会内存溢出,毕竟里面是用jdbc去获取的,所有数据都装在jdbc的对象中,爆是必然的。在1.3以后改写jdbc的内部原理,拿到一条数据就写入硬盘中,就没有内存溢出了。
增量导入
Sqoop不需要每次都导入整张表。例如,可以指定仅导入表的部分列。用户也可以在查询中加入where子句,来限定需要导入的记录。例如,如果上个月已经将id为0~9999的记录导入,而本月新增了1000条记录,那么在导入时的查询语句中加入子句where id>=10000,来实现只导入所有新增的记录。
它需要添加incremental,check-column,和last-value选项来执行增量导入。
下面的语法用于Sqoop导入命令增量选项。
--incremental <mode> --check-column <column name> --last value <last check column value>
假设新添加的数据转换成intsmaze表如下:
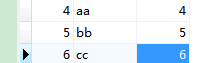
下面的命令用于在intsmaze表执行增量导入。
bin/sqoop import --connect jdbc:mysql://192.168.19.131:3306/test --username root --password hadoop \ --table person \ --m 1 \ --incremental append \ --check-column id \ --last-value 3
执行增量导入时,则会在hdfs上默认路径下新增一个文件来存储导入的新增数据,如上面的part-m-00001。
part-m-00001文件的数据内容为:
4,aa,4 5,bb,5 6,cc,6
导入到HDFS指定目录
在使用Sqoop导入表数据到HDFS,我们可以指定目标目录。
--target-dir <new or exist directory in HDFS>
下面的命令是用来导入emp_add表数据到'/queryresult'目录。
bin/sqoop import \ --connect jdbc:mysql://192.168.19.131:3306/test \ --username root \ --password hadoop \ --target-dir /queryresult \ --table intsmaze \ --m 1
实际场景的分析:我一开始担心在导入增量数据时,数据文件的位置等问题,想过通过每次执行增量导入时来根据时间作为文件名来指定每一次导入时文件存储在hdfs上的路径来解决。现在看来不需要担心这个问题了。但是考虑这样一种情况:关系库中的某张表每天增量导入到hdfs上,然后使用hive对导入的数据加载进hive表时,我们不应该每次都情况hive表再进行全局导入hive,这样太耗费效率了。当然可以根据文件的生成时间来确定每次把那个文件导入到hive中,但是不便于维护,可以直接根据目录名来导入该目录下的数据到hive中,且导入到hive中的数据可以按天设置分区,每次导入的数据进入一个新的分区。
有些业务场景只需要对hive表中每天新增的那些数据进行etl即可,完全没有必要每次都是将整个hive表进行清理,那么可以结合hive的分区,按天进行分区,这样每次进行etl处理就处理那一个分区数据即可。当然有些数据比如两表的join操作,则必须对全表进行处理,那么在join时不限制分区即可,数据倒入时仍然时间分区装载数据。
导入关系表到HIVE
bin/sqoop import --connect jdbc:mysql://192.168.19.131:3306/test --username root --password root --table intsmaze --hive-import --m 1
sqoop import --connect jdbc:mysql://192.168.19.131:3306/hive --username root --password admin --table intsmaze --fields-terminated-by '\t' --null-string '**' -m 1 --append --hive-import --check-column 'TBL_ID' --incremental append --last-value 6
导入表数据子集
Sqoop导入"where"子句的一个子集。它执行在各自的数据库服务器相应的SQL查询,并将结果存储在HDFS的目标目录。
where子句的语法如下。
--where <condition>
导入intsmaze表数据的子集。子集查询检所有列但是居住城市为:sec-bad
bin/sqoop import \ --connect jdbc:mysql://192.168.19.131:3306/test \ --username root \ --password root \ --where "city ='sec-bad'" \ --target-dir /wherequery \ --table intsmaze --m 1
按需导入
bin/sqoop import \ --connect jdbc:mysql://192.168.19.131:3306/test \ --username root \ --password root \ --target-dir /wherequery2 \ --query 'select id,name,deg from intsmaze WHERE id>1207 and $CONDITIONS' \ --split-by id \ --fields-terminated-by '\t' \ --m 1
$CONDITIONS参数是固定的,必须要写上。
支持将关系数据库中的数据导入到Hive(--hive-import)、HBase(--hbase-table)
数据导入Hive分三步:1)导入数据到HDFS 2)Hive建表 3)使用“LOAD DATA INPAHT”将数据LOAD到表中
数据导入HBase分二部:1)导入数据到HDFS 2)调用HBase put操作逐行将数据写入表
导入表数据由于字段存在空字符串或null导致的问题
bin/sqoop import --connect jdbc:mysql://192.168.19.131:3306/test --username root --password hadoop \ --table intsmaze \ --m 1 \ --incremental append \ --check-column id \ --last-value 6
我们查看hdfs上的数据
7,null,7 8,null,8
MySQL(或者别的RDBMS)导入数据到hdfs后会发现原来在mysql中字段值明明是NULL, 到Hive查询后 where field is null 会没有结果呢,然后通过检查一看,NULL值都变成了字段串'null'。其实你在导入的时候加上以下两个参数就可以解决了,
--null-string '\\N' --null-non-string '\\N'
这里要注意一点。在hive里面。NULL是用\N来表示的。你可以自己做个实验 insert overwrite table tb select NULL from tb1 limit 1;然后在去查看原文件就可以发现了。多提一点,如果在导入后发现数据错位了,或者有好多原来有值的字段都变成了NULL, 这是因为你原表varchar类型的字段中可能含有\n\r等一些特殊字符。可以加上 --hive-drop-import-delims

