

截取字符串中最后一个中文词语(MS SQL)
有朋友需求一个问题,就是处理一张表中某一字段,从这个字段中去截取内容中最后一个中文词语。


ID SourceText Result 1 张达:U:1杨英苹:U:1,周忱:U:1,;苗桥:U:1,章玮:U:1,; 2 gaoying,高颖:U; 3 gaoying,高颖:U; 4 mq,苗桥;dingjian,丁健:U;zhangwei,章玮;zc,周忱; 5 xwj,向文杰; 6 dingjian,丁健; 7 mq;chendeyong; 8 gy,郭颖; 9 houwenjun,侯文君;lj,李军;sunle,孙乐; 10 dingjian,丁健:U; 11 dingjian,丁健:U;zhangwei,章玮; 12 wwm,王文明;zkl,张康亮;jiangyuan,蒋远;fyj,范云军; 13 dingjian,丁健; 14 fyj,范云军;wwm,王文明;zkl,张康亮; 15 lww,陆维巍;
创建一个张来存储上面的数据:
SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO CREATE TABLE [dbo].[DataSource]( [ID] [int] IDENTITY(1,1) NOT NULL, [SourceText] [nvarchar](100) NULL, --原始值 [Result] [nvarchar](100) NULL --处理结果 ) ON [PRIMARY] GO
另外,你还要创建另外一张表,用来存储所有字符串中,分隔符号:
SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO CREATE TABLE [dbo].[Punctuation]( [ID] [int] IDENTITY(1,1) NOT NULL, [Name] [nvarchar](2) NULL ) ON [PRIMARY] GO
把所有分隔的标点符号,添加入此表中:
处理数据,我们需要分好次来进行,先去除字母和数字: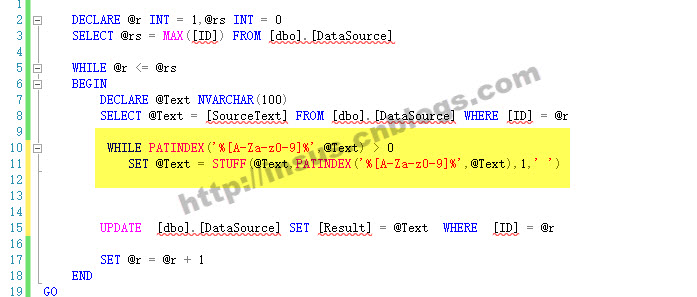
得到的结果:
接下来,我们去除字符串的标点字符:
这一步,运行的结果如下:
越来越接近我们需求的结果了:
此时,我需要对处理的结果,再次处理,得需要了解下面二个函数:
《使用XQuery的nodes()方法实现字符拆分》http://www.cnblogs.com/insus/archive/2012/02/26/2368283.html
或
《MS SQL Server字符拆分函数》http://www.cnblogs.com/insus/p/3163564.html
其实二个函数,最终处理结果是一样的。就是分割字符串,然后放在一张表中
回到刚才的代码中,我们只管添加一行代码即可实现了我们的要求:
DECLARE @r INT = 1,@rs INT = 0 SELECT @rs = MAX([ID]) FROM [dbo].[DataSource] WHILE @r <= @rs BEGIN DECLARE @Text NVARCHAR(100) SELECT @Text = [SourceText] FROM [dbo].[DataSource] WHERE [ID] = @r WHILE PATINDEX('%[A-Za-z0-9]%',@Text) > 0 SET @Text = STUFF(@Text,PATINDEX('%[A-Za-z0-9]%',@Text),1,' ') DECLARE @x INT = 1,@xs INT = 0 SELECT @xs = MAX([ID]) FROM [dbo].[Punctuation] WHILE @x <= @xs BEGIN DECLARE @p NVARCHAR(2) SELECT @p = [Name] FROM [dbo].[Punctuation] WHERE [ID] = @x SET @Text = RTRIM(LTRIM(REPLACE(@Text,@p,' '))) SET @x = @x + 1 END SELECT TOP 1 @Text = [WORD] FROM [dbo].[udf_Split](@Text,' ') WHERE LEN(ISNULL([WORD],''))> 0 ORDER BY [ID] DESC UPDATE [dbo].[DataSource] SET [Result] = @Text WHERE [ID] = @r SET @r = @r + 1 END GO
结果如下:
OK,这就是实现的全部过程。但是,我们应该不满足上面的代码。既然都使用正则来去除字母,数字,那标点符号可以使用正则来去除对吧。
所以说,我们不必再创建一个表来存储标点符号了。
DECLARE @r INT = 1,@rs INT = 0 SELECT @rs = MAX([ID]) FROM [dbo].[DataSource] WHILE @r <= @rs BEGIN DECLARE @Text NVARCHAR(100) SELECT @Text = [SourceText] FROM [dbo].[DataSource] WHERE [ID] = @r WHILE PATINDEX('%[A-Za-z0-9:,;]%',@Text) > 0 SET @Text = STUFF(@Text,PATINDEX('%[A-Za-z0-9:,;]%',@Text),1,' ') SET @Text = LTRIM(RTRIM(@Text)) SELECT TOP 1 @Text = [WORD] FROM [dbo].[udf_Split](@Text,' ') WHERE LEN(ISNULL([WORD],''))> 0 ORDER BY [ID] DESC UPDATE [dbo].[DataSource] SET [Result] = @Text WHERE [ID] = @r SET @r = @r + 1 END
最终的结果一样,代码很了不少!!!

