

综述阅读:Salient Object Detection in the Deep Learning Era: An In-Depth Survey
这篇文章主要介绍深度学习下的显著目标检测算法及数据集,对比各类算法探究形成综述。
原文地址:https://arxiv.org/pdf/1904.09146.pdf 若有个人误区及翻译错误,恳请及时评论指正。
目录
前言
作为一个重要的计算机视觉研究问题,近年显著目标检测(Salient Object Detection,SOD)吸引了越来越多研究者的关注。意料之中的是,显著目标检测的最新研究已经由深度学习方法所主导(deep SOD),多百篇该领域文章的发表予以了印证。为了促进对深度显著目标检测的理解,本文提供一个全面详尽的调查,涵盖多个算法的分类以及一些未解决的开放问题。首先,我们从不同的角度审视了SOD算法,从网络架构,监督级别,学习范式以及针对对象/实例的检测来分类。之后,我们总结了现有的SOD评估数据集及评估标准。然后,我们根据他人已有的工作编制了一个覆盖主流SOD方法的benchmark,提供详细的结果分析。并且我们研究了不同SOD算法在各类数据集上的表现。最后,我们讨论了几个SOD未解决的问题的挑战,并且指出今后的潜在研究方向。所有的显著性预测图、构建的带注释的数据集,以及评估方法的代码都在https://github.com/wenguanwang/SODsurvey获取。
第一章:介绍
显著性检测通常分为眼动点检测和显著目标检测。显著目标检测(SOD)的目的是突出图像中的显著目标区域。而显著性检测的另一个任务凝视点检测(fixation prediction)则起源于认知和心理学研究,与眼动点检测不同的是,显著目标检测更多的受不同领域的应用驱动:比如,在CV研究中,SOD可以应用于图像理解,图像描述,目标检测,无监督的视频目标分割,语义分割,行人重识别,等等;在计算机图形学中,SOD可以应用于非真实性渲染,图像自动裁剪,图像重定位,视频摘要等;在机器人领域中,可用于人机交互和目标发现等等。
得益于深度学习技术,显著目标检测得到飞速发展。从2015年首次被介绍,深度的SOD算法一直有着比传统算法更卓越的表现,并且在各类基准测试排行中霸榜。
第一节:History and Scope
与计算机视觉的其他任务相比,SOD的历史相对短暂。传统SOD模型主要依赖于低级特征并且受到如颜色对比、背景先验的启发。为了获得显著对象和清晰的对象区域,区域生成、超像素、OP算法(Object Proposals)经常集成于过分割过程。如下图Fig.1所示。
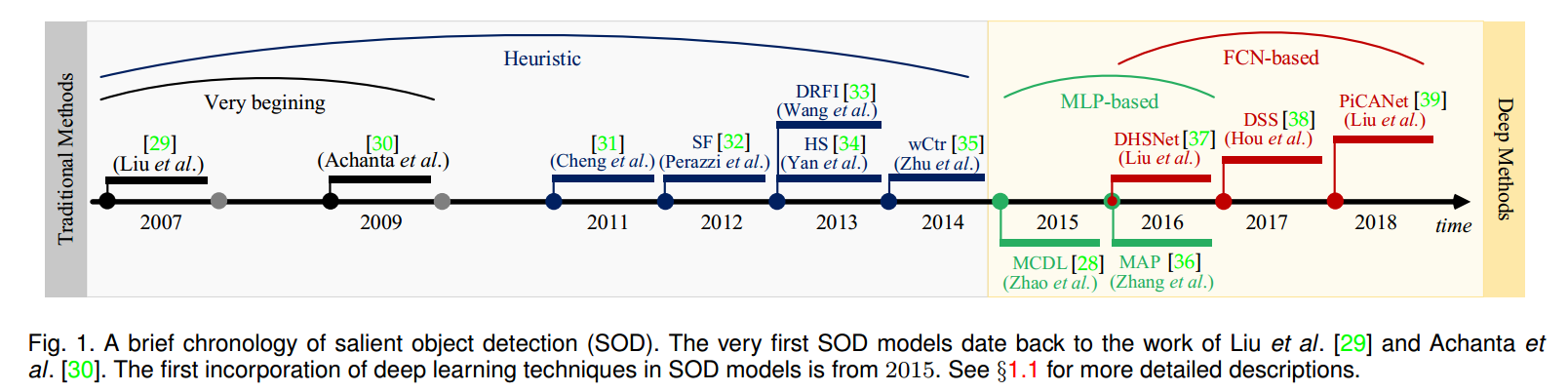
2015年以来,各类深度学习SOD相继提出。早期的SOD深度模型主要利用多层感知机分类器来预测从图像的每个处理单元提取的深度特征的显著性得分。之后,全卷积网络(FCN)成为了更主流的SOD架构。简要的SOD发展年表图如Fig.1。本文主要涵盖过去5年的研究进展,也为了完整性的需要,还包括了一些早期的相关工作。需要注意的是,本文主要注重单图像级别的显著性检测,将实例级SOD、RGB-D SOD、co-saliency detection、video SOD、FP、social gaze prediction 当做其它topic。
第二节:Related Previous Reviews and Surveys
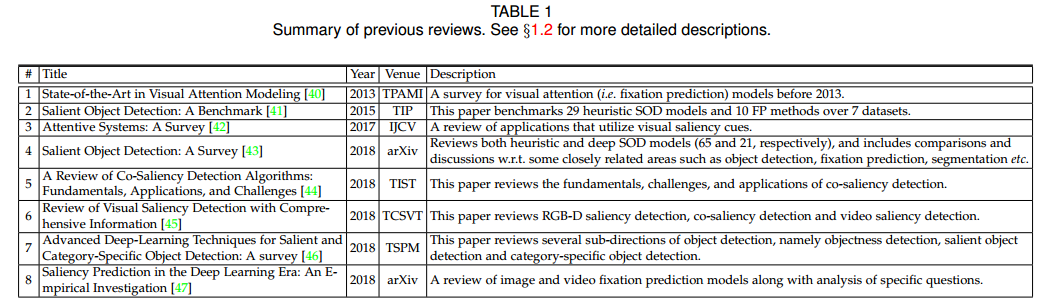
Table 1 列出了已有综述。在文章2中,Borji等人审视了2015年之前的SOD方法,因此不涉及深度学习解决方案。最近,如文章4,综述研究已经扩展到传统非深度学习方法与深度学习方法的研究。文章5中,对协同分割(co-segmentation)的方法进行了分析,这是视觉显著性的一个分支,可以检测并分割来自多个相关图像的显著位置。文章6对几个SOD的扩展任务,如RGB-D SOD、co-salency detection 和 视频SOD进行了综述。文章7研究了目标检测的几个子方向,并总结了目标检测,显著目标检测,指定物品检测(COD)等研究。在文章1和文章8中,还是Borji等人总结了凝聚点检测的模型,并分析了几个特殊问题。文章3主要侧重于在不同应用领域内对视觉显著性(包括SOD和FP)进行分类。
不同于之前的综述文章,我们的文章系统、全面的对深度学习方法的SOD算法进行分析。特别地,我们几种基于分类法(based on proposed taxonomies)的深度学习方法,通过属性评估深入分析输入扰动的影响,讨论了深度SOD模型的对对抗攻击的鲁棒性,概括了现有数据集,为重要的开放性问题,挑战和未来方向提供见解,以促进读者对深度SOD模型的理解,并激发对诸如对SOD的对抗性攻击等公开问题的研究。
第三节:Our Contributions
本文的主要贡献可以概括为如下几点:
1)多角度(网络结构、监督级别、学习方式、对象/实例级)评价不同的深度SOD模型。
2)提出基于属性的深度SOD模型评估方法
3)讨论了输入扰动的影响
4)首次探讨对SOD模型的对抗性攻击分析,深度神经网络(DNNs)一些典型任务如识别已被证明易受视觉上难以察觉的对抗性攻击,这种攻击对深度SOD模型的影响尚未被探索。就此我们提出了精心设计的对抗性问题的baseline attack及评估,可作为未来深度SOD模型鲁棒性及可迁移性研究的baseline。
5)因为现有数据集都会包含一些偏差,我们使用了代表性的深度SOD算法对现有的SOD数据集进行跨数据集泛化研究。
6)对公开问题和未来的研究方向进行讨论。
第二章:深度显著目标检测模型
在分析最近所有的深度SOD模型前,我们将显著目标检测的任务定义如下:即将 input image(通常为三通道图像,经过SOD算法 F 后,获得二值显著目标,即binary salient object mask。那么在接下来的部分,我们将以下从4种分类方式介绍不同类别的深度SOD算法:1、经典网络结构 2、监督级别 3、学习范式 4、对象级和实例级
第一节 具有代表性的SOD网络结构
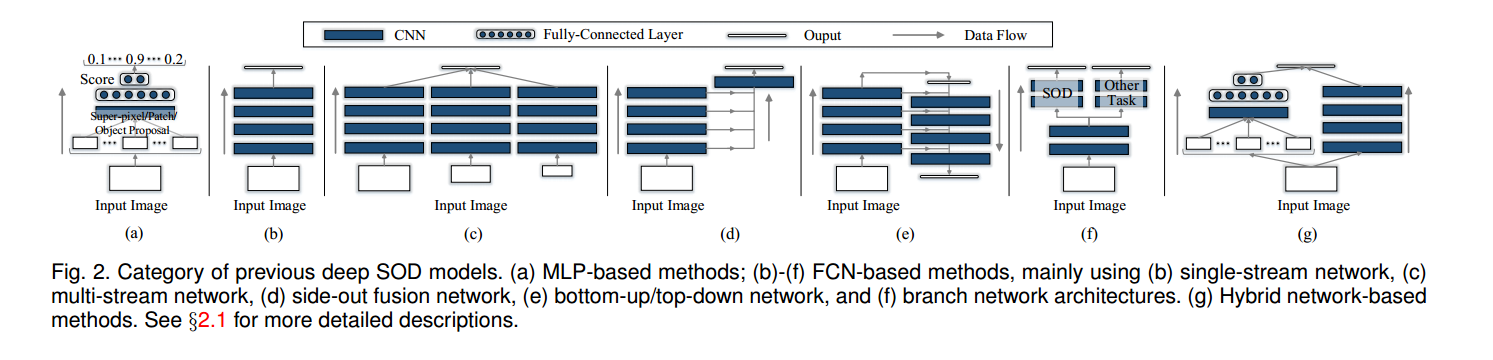
(1) 基于多层感知机(MLP)的模型
1)Super-pixel/patch based methods
基于MLP的模型通常为图像的每个处理单元提取深度特征,以训练显著性得分预测的MLP分类器,如图 Fig.2(a)所示,常用的处理单元包括 super-pixels/patches,或者 generic object proposals。
• MACL(Saliency Detection by Multi-Context Deep Learning) 传统SOD方法对于背景对比度低并且容易造成视觉混淆的图像不能产生好的显著性划分。针对此问题,这篇文章使用两个路径从两个超像素中兴不同的窗口提取局部和全局上下文,随后在同一的混合文本深度学习框架中联合建模。
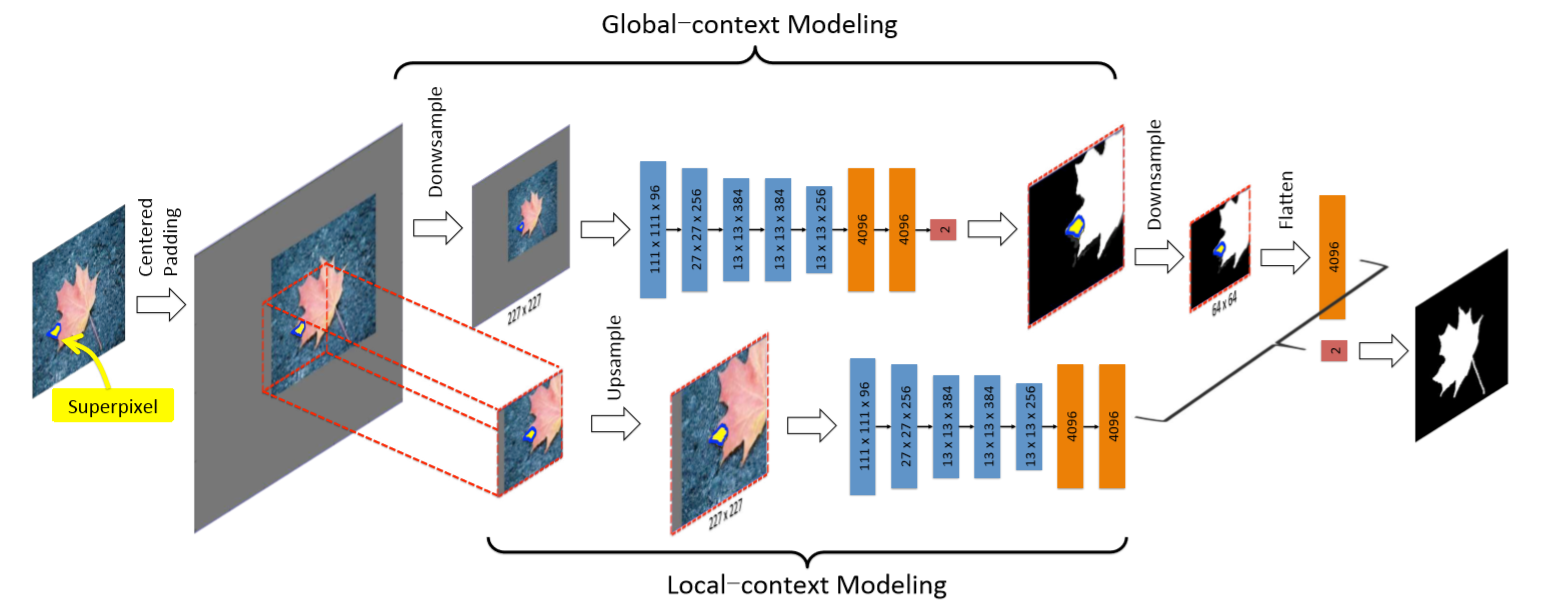
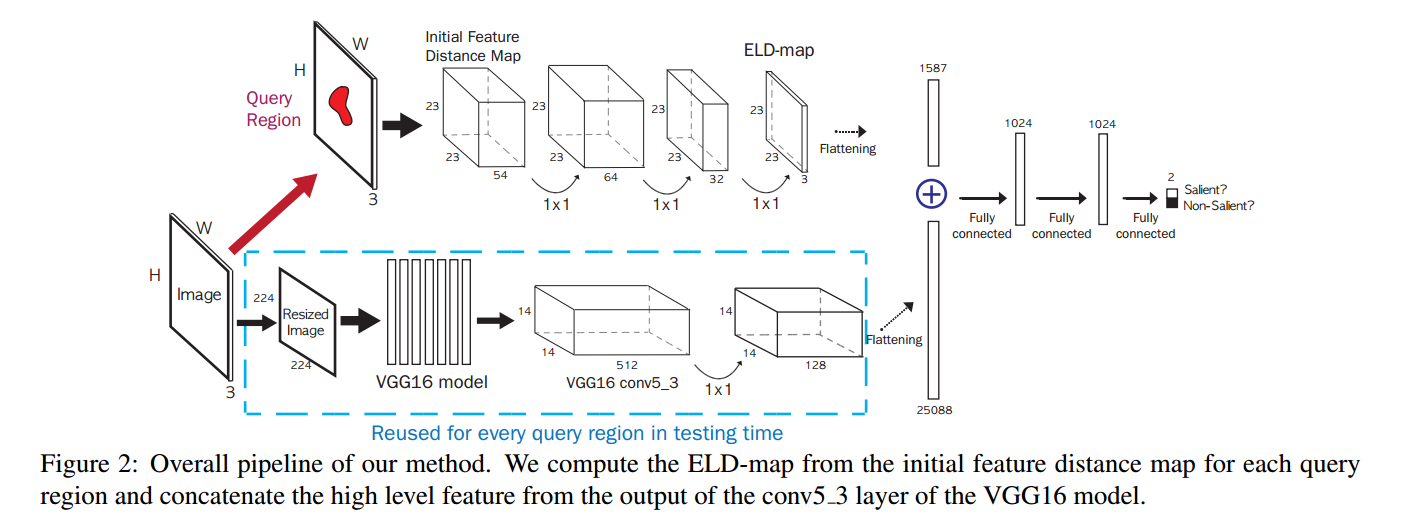
• ELD (Deep saliency with encoded low level distance map and high level features) 使用VGG-net提取高级特征,低级特征与图像的其他部分进行比较生成低级距离图。然后使用具有多个1×1卷积和ReLU层的卷积神经网络(CNN)对低级距离图进行编码。我们将编码过的低级距离图和高级特征连接,并将它们送入全卷积网络分类器去评估显著区域。
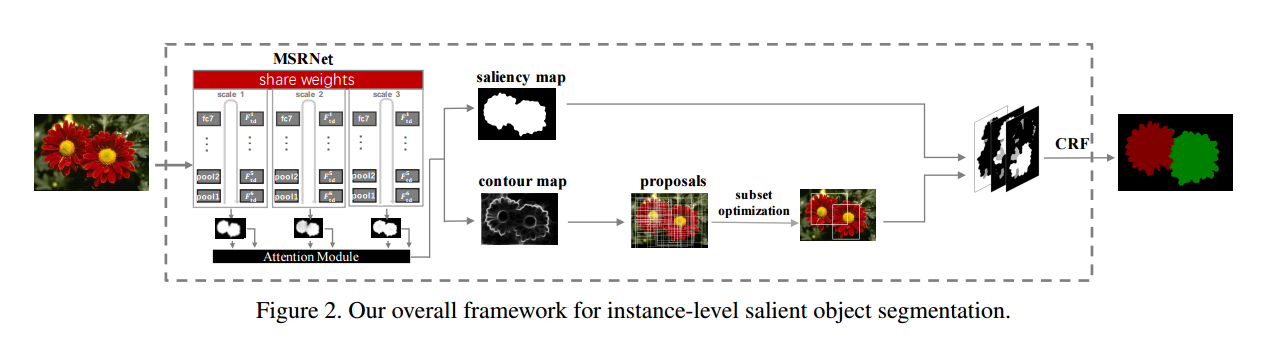
• SuperCNN(Instance-Level Salient Object Segmentation) 本文提出MSRNet,首次进行显著实例分割。一共分三个步骤,一是估计显著性图,二是检测显著对象轮廓,三是识别显著对象实例,针对前两个步骤,此文提出多尺度细化网络,用于生成高质量的显著区域和显著轮廓。
2)Object Proposal based Methods
基于OP的模型利用Obejct Proposal(翻译:OP到底怎么翻译,目标建议?),或 bounding-boxes(框出目标区域),作为基本处理单元,自然而然的编码目标信息。
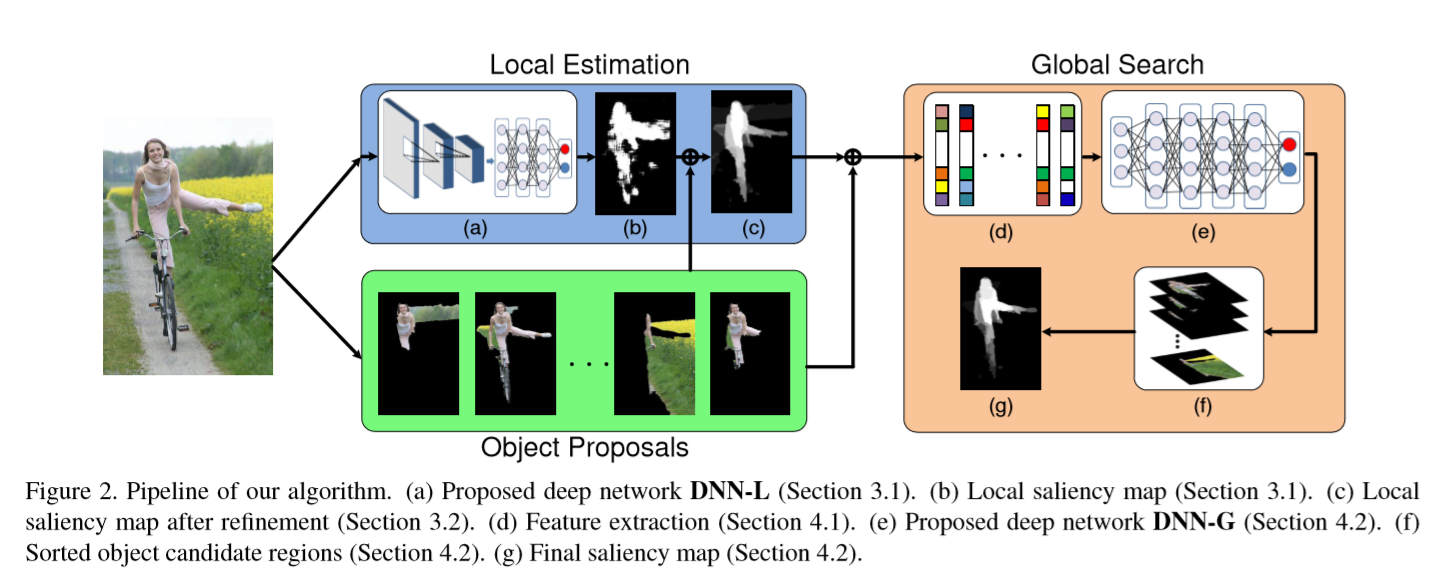
• LEGS(Deep Networks for Saliency Detection via Local Estimation and Global Search) 提出一种局部估计和全局搜索结合的SOD算法。在局部估计阶段,我们通过使用深度神经网络(DNN-L)来检测局部显著性,该神经网络学习局部块特征以确定每个像素的显著性值。通过探索高级目标概念,进一步确定估计的局部显著性图。在全局搜索阶段,将局部显著性图与全局对比度和几何信息一起用作描述一组对象候选区域的全局特征。
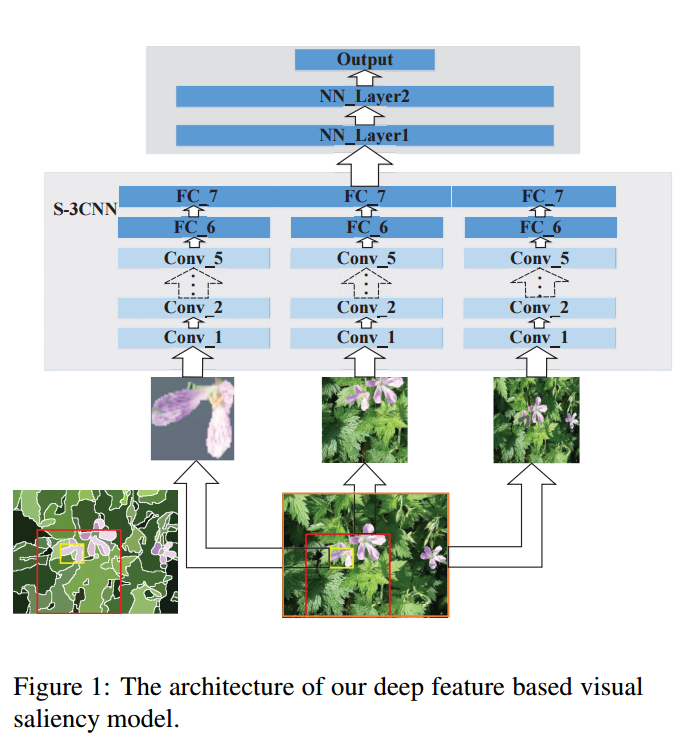
• MDF(Visual saliency based on multiscale deep features) 本文利用深度卷积神经网络(CNN)提取的多尺度特征可以获得高质量的视觉显着性模型。为了学习这类显着性模型,我们引入了一种神经网络体系结构,它在CNN上有完全连接的层,负责三个不同尺度的特征提取。然后,我们提出了一种改进方法,以提高我们的显着性结果的空间一致性。最后,为不同层次的图像分割而计算的多个显着性映射的聚合可以进一步提高图像分割的性能,从而产生比单一分割生成的显着性映射更好的显着性映射。
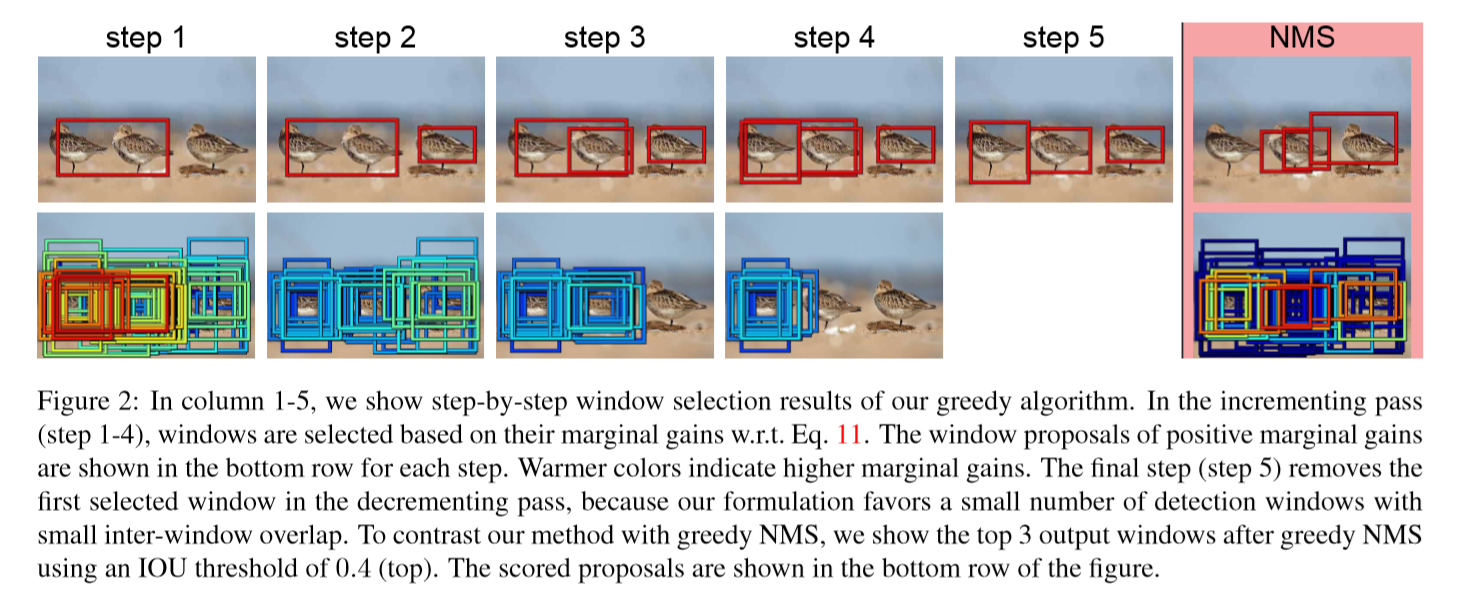
• MAP (Unconstrained Salient Object Detection via Proposal Subset Optimization) 我们的目的是在无约束图像中的检测显著性目标。 在无约束的图像中,显著目标的数量(如果有的话)因图像而异,没有给出。 我们提出了一个显著性目标检测系统,直接为输入图像输出一组紧凑的检测窗口。 我们的系统利用CNN来生成显著对象的位置建议。 位置建议往往是高度重叠和嘈杂的。 基于最大后验准则,我们提出了一种新的子集优化框架来从杂乱建议中生成一组紧凑的检测窗口。
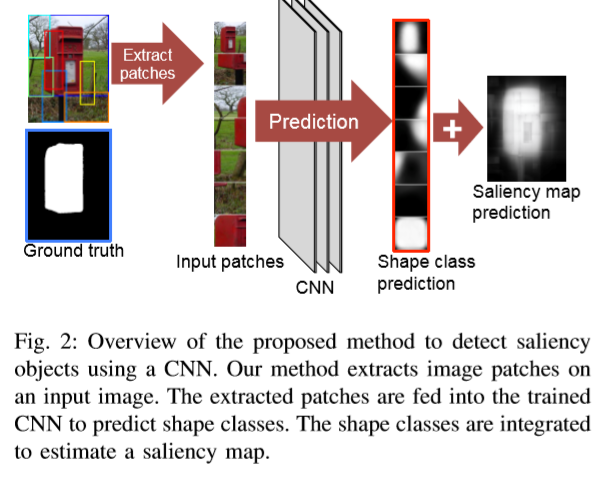
• SSD (A shape-based approach for salient object detection using deep learning) 首先生成区域建议,然后用CNN对每个区域建议分类为具有标准二值图的预定义形状类。
(2) 基于全卷积网络(FCN)的模型
虽然优于以前的非深度学习SOD模型和具有深度学习特征的启发式模型,但基于MLP的SOD模型无法捕获显而易见的空间信息并且非常耗时。受全卷积网络在语义分割有着优越表现的影响,最新的深度SOD模型将流行的分类模型(例如VGGNet和ResNet)调整为全卷积模型,以直接输出spatial map而不是分类得分。这样,深度SOD模型可以在单个前馈传播过程中受益于端到端的空间显著表示并有效预测显著性图。典型的体系结构可以分为几类:单流网络(Single-stream network),多流网络(Multi-stream network),侧融合网络(Side-fusion network),自下而上/自上而下网络(Bottomup/top-down network)和分支网络(Branched network)。
1)Single-stream network 单流网络是标准的卷积层、池化层、激活层级联的序贯结构。可在Fig.2(b)中看到。
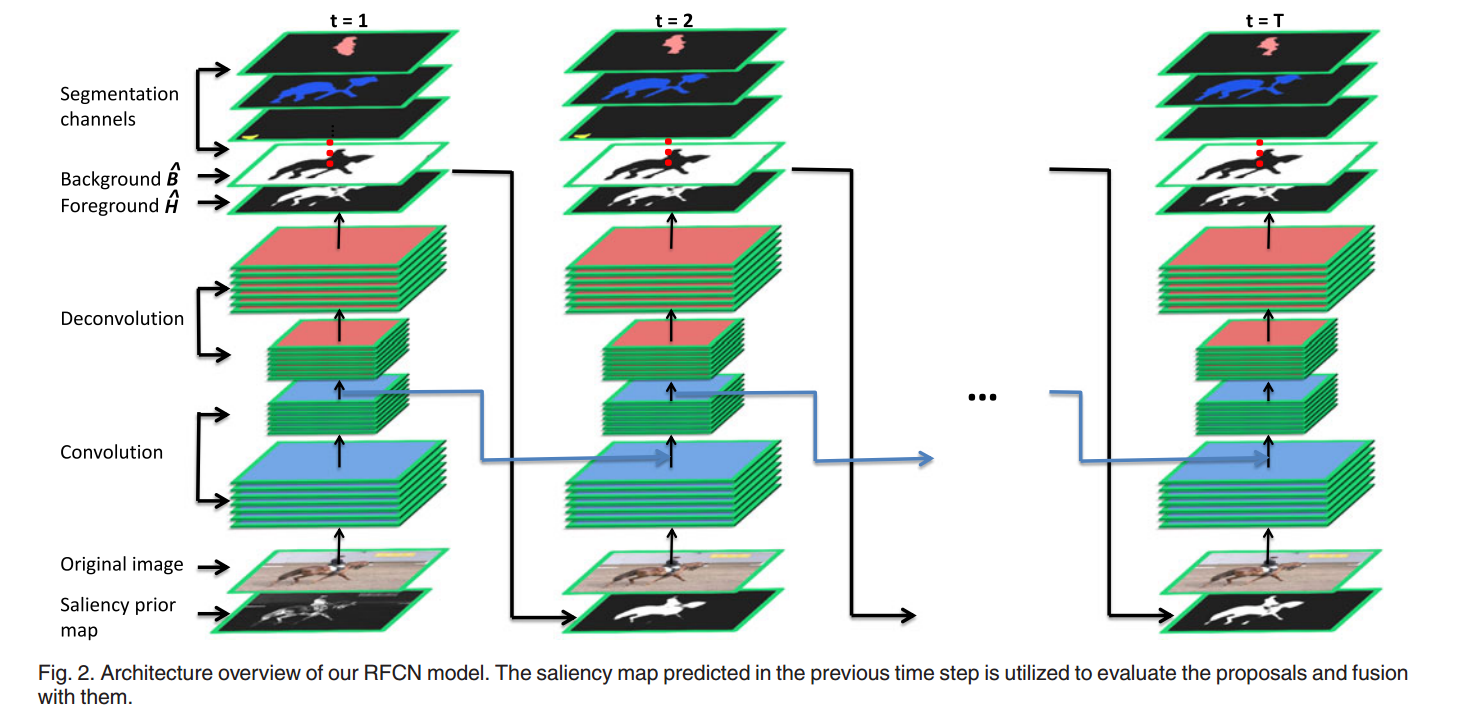
• RFCN (Saliency detection with recurrent fully convolutional networks) RFCN目前在PASCAL VOC2010分段数据集上进行了预训练,以学习语义信息,然后调整到SOD数据集以预测前景和背景。 显著性图是前景和背景分数的softmax组合。在本文中,我们通过使用循环完全卷积网络(RFCN)开发新的显着性模型更进一步。此外,循环体系结构使我们的方法能够通过纠正其先前的错误自动学习优化显着性映射。 为了训练具有多个参数的这样的网络,我们提出了使用语义分割数据的预训练策略,其同时利用对分割任务的强有力的监督以进行更好的训练,并使网络能够捕获对象的通用表示以用于显著性检测。
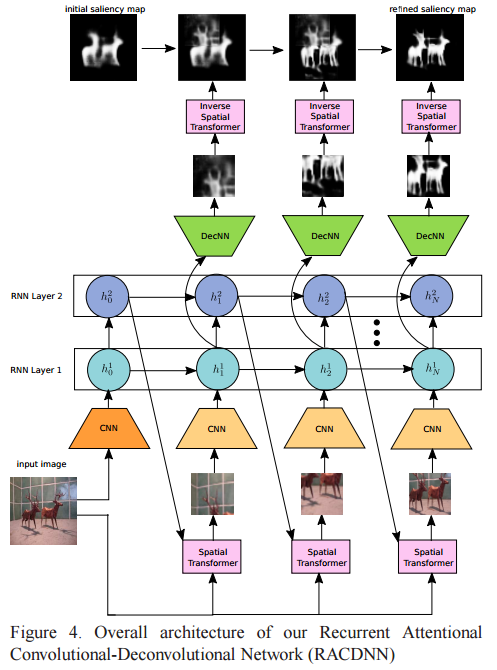
• RACDNN (Recurrent Attentional Networks for Saliency Detection)卷积 - 反卷积网络可用于执行端到端显着性检测。 但是,它们不适用于多尺度的物体。 为了克服这种限制,在这项工作中,我们提出了一种循环注意卷积 - 反卷积网络(RACDNN)。使用编码器 - 解码器流产生粗略显着图,并逐步确定不同的局部对象区域。 它利用空间变换器在每次迭代时处理图像区域以进行改进。
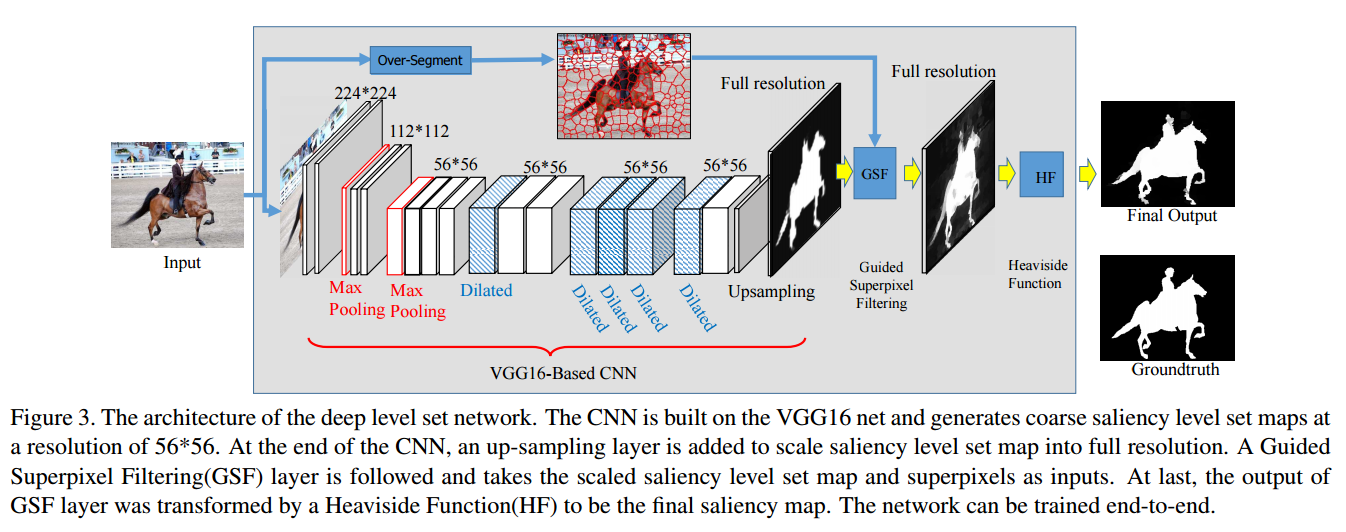
• DLS(Deep Level Sets for Salient Object Detection)深度网络难以区分对象边界内的像素,因此深度网络可能输出具有模糊显着性和不准确边界的映射。为了解决搜索问题,在这项工作中,我们提出了一个深层次的网络集来生成紧凑和统一的显着性图。利用一系列卷积层初始化显著图,然后在超像素级别对其进行细化。 水平集损失函数用于帮助学习二进制分割图。
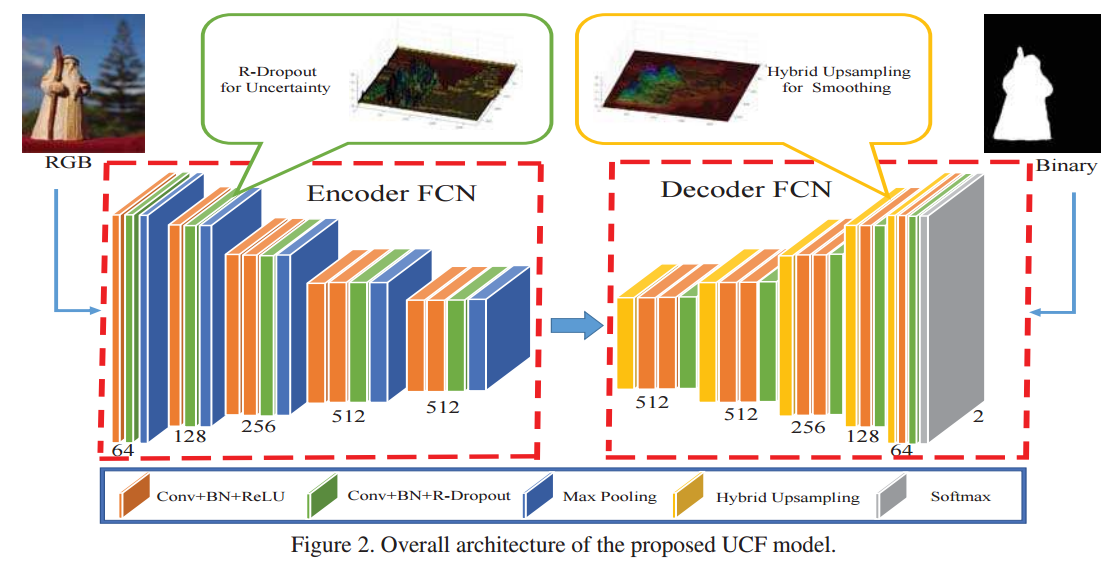
• UCF(Learning Uncertain Convolutional Features for Accurate Saliency Detection)在本文中,我们提出了一种新的深度卷积模型,用于精确的显著目标检测。 这项工作的关键贡献是学习深度不确定的卷积特征(UCF),这可以提高显着性检测的鲁棒性和准确性。这个算法基于Deeplab算法,该算法位于具有扩张卷积层的FCN的顶部。 它通过几种启发式显著性方法的像素监督方法来学习潜在的显着性和噪声模式。
• LICNN(Lateral inhibition-inspired convolutional neural network for visual attention and saliency detection 没查到有此文,作者笔误了么,找到的请评论一下)
2)Muilti-stream network 单流网络如Fig.2(c)所示,通常具有多个网络流,每个网络流是多通道显著特征。 然后将来自不同流的输出组合在一起以进行最终预测。
• MSRNet(Instance-level salient object segmentation)由三个自底向上/自顶向下网络结构流组成,以处理输入图像的三个缩放版本。 这三个输出通过可学习的注意力模块最终融合。
• SRM(A stagewise refinement model for detecting salient objects in images)通过将它们从较粗糙的流中逐步传递到较为简单的流来逐步确定显著特征。 每个流的最顶层特征是使用地面实况显著性掩码进行监督。 金字塔池模块进一步促进了多阶段显着性融合和改进。
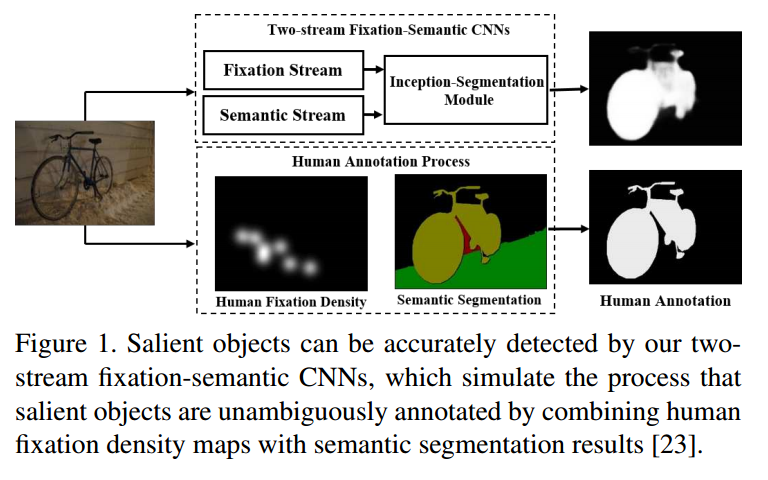
• FSN (Look, Perceive and Segment: Finding the Salient Objects in Images via Two-stream Fixation-Semantic CNNs) 受到人类观察事物的启发,显着的物体通常会获得人们的视觉关注,将眼睛注视流和语义流的输出融合到初始分割模块中以预测显著性。
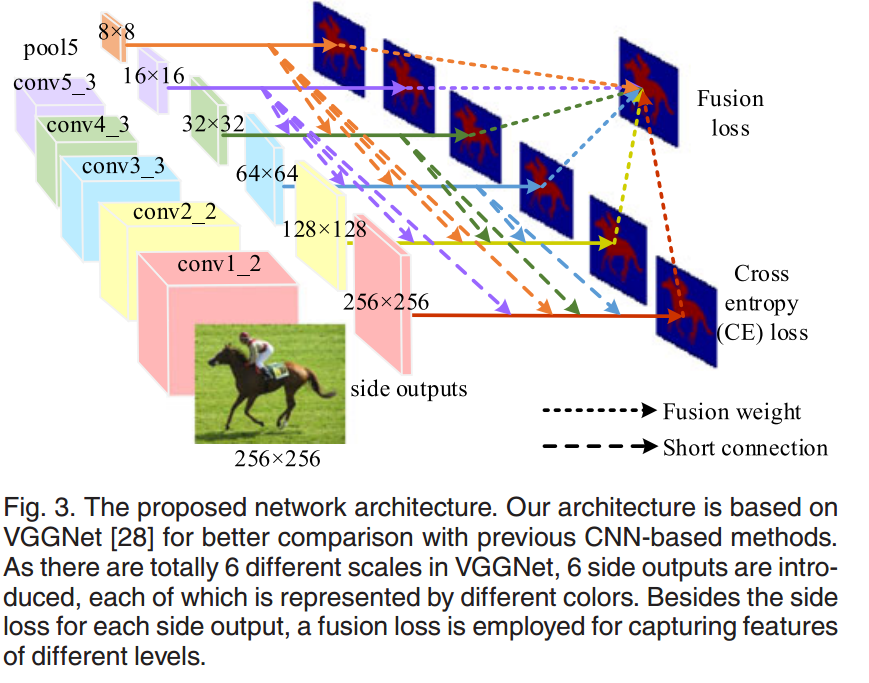
3) Side-fusion network 侧融合网络将骨干网络的多层响应融合在一起用于SOD预测,利用CNN层次结构的固有多尺度表示,如Fig.2 (d)。 侧网络输出通常由GT监督,是深监督策略。
• DSS (Deeply Supervised Salient Object Detection with Short Connections) 增加了从较深侧输出到较浅侧输出的几个短连接。 通过这种方式,更高级别的功能可以帮助降低侧面输出以更好地定位显着区域,而较低级别的功能可以帮助丰富更高级别的侧面输出和更精细的细节。
• NLDF (Non-Local Deep Features for Salient Object Detection) 通过以自上而下的方式融合多级特征和对比度特征来生成局部显著性图,然后将局部地图与由顶层产生的全局图集成以产生最终预测。 通过从平均池中减去特征来获得对比度特征。
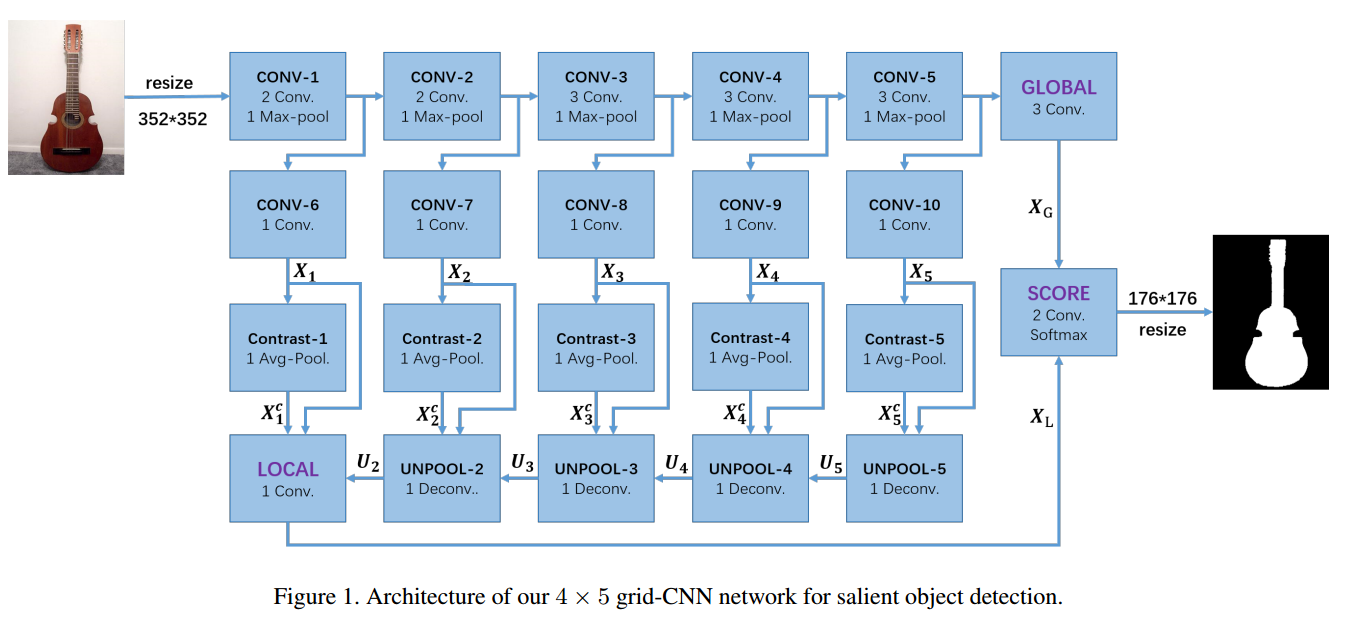
• Amulet (Amulet: Aggregating Multi-level Convolutional Features for Salient Object Detection) 如何更好地聚合多级卷积特征图以进行显著对象检测尚未得到充分研究。我们的框架首先将多级特征映射集成到多个分辨率中,同时包含粗略语义和精细细节。多个聚合特征以自上而下的方式进一步确定。 在最终融合之前,在每个聚合特征处引入边界改进。多个聚合特征以自上而下的方式进一步确定。在最终融合之前,在每个聚合特征处引入边界改进。
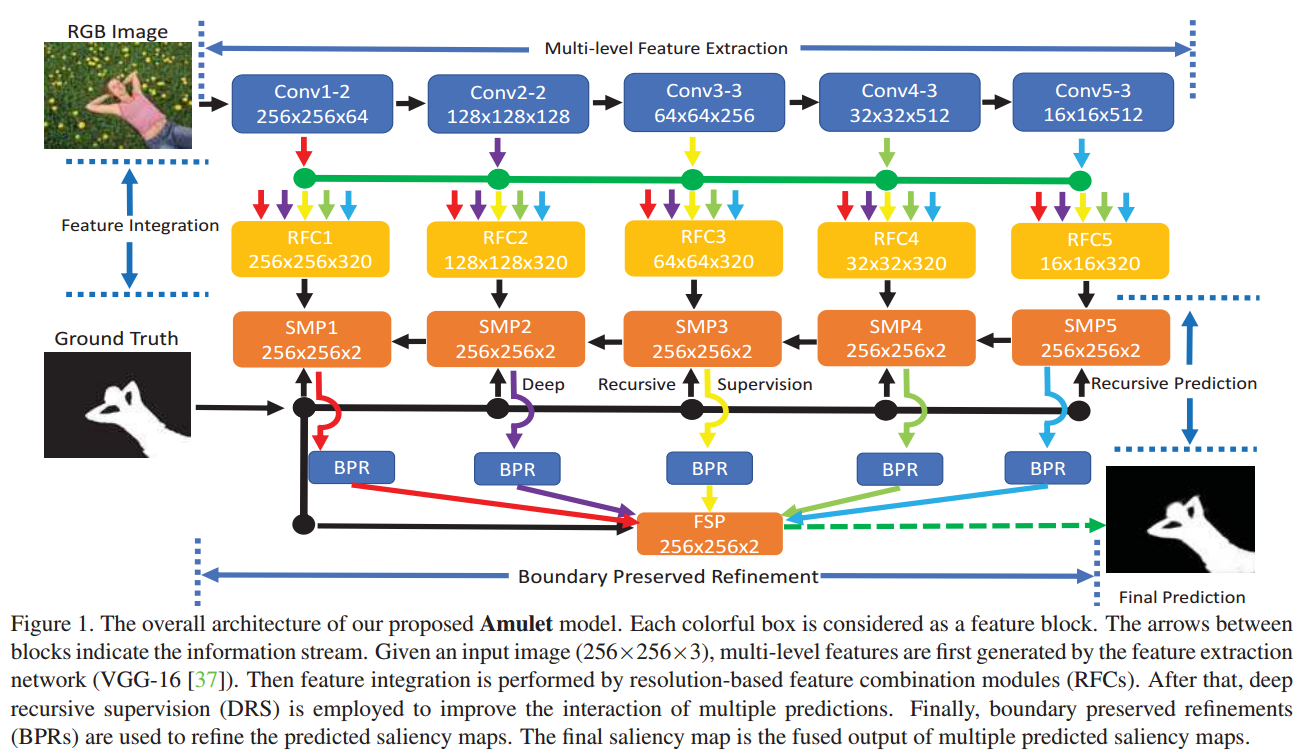
• DSOS (Delving into salient object subitizing and detection) 在本文中,我们探讨了数值之间的相互作用。 为了从不同的角度解决多任务问题,我们提出了一种多任务深度神经网络,通过使用动态权重预测来增加子资源来检测显着对象。大量实验表明,subtizing knowledge(数学感知能力)为显着对象检测提供了强有力的指导。
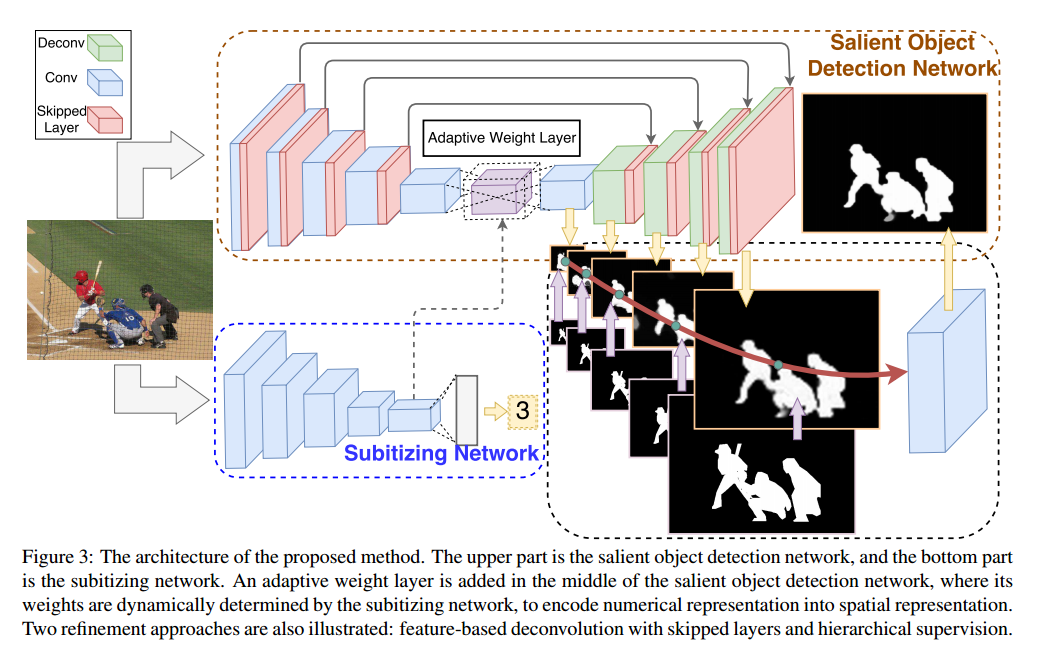
• RADF (Recurrently aggregating deep features for salient object detection,未找到此文资源,如果有发一下链接) 利用综合的侧面特征来自我修复,并且重复这样的过程以逐渐产生明确的显着性预测。
• RSDNet-R (Revisiting salient object detection: Simultaneous detection, ranking, and subitizingofmultiplesalientobjects) 在门控机制下将早期层的初始粗略表示与细节特征相结合,以逐步地重新定义侧输出。 融合所有阶段的地图以获得整体显著性图。
4) Side-fusion network 侧面融合通过逐步合并来自较低层的空间细节丰富的特征来确定前馈过程中的粗略显著性估计,并在最顶层产生最终映射(见Fig2. e)。
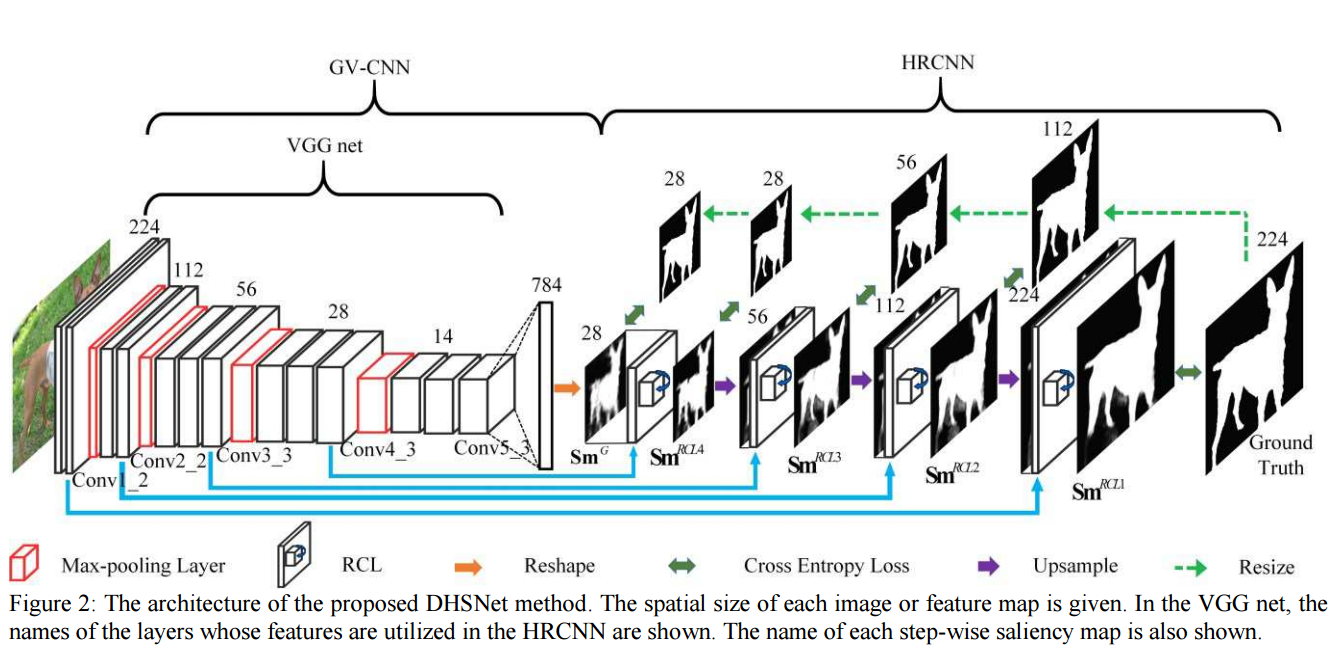
• DHSNet (DHSNet: Deep Hierarchical Saliency Network for Salient Object Detection) 通过使用递归层逐渐组合较浅的特征来重新确定粗略显着图,其中所有中间图由GT显著图监督。
• SBF (Supervision by fusion:Towards unsupervised learning of deep salient object detector) 借用了DHSNet的网络架构,但是在几个未受监督的启发式SOD方法提供的弱基础事实下进行了训练。
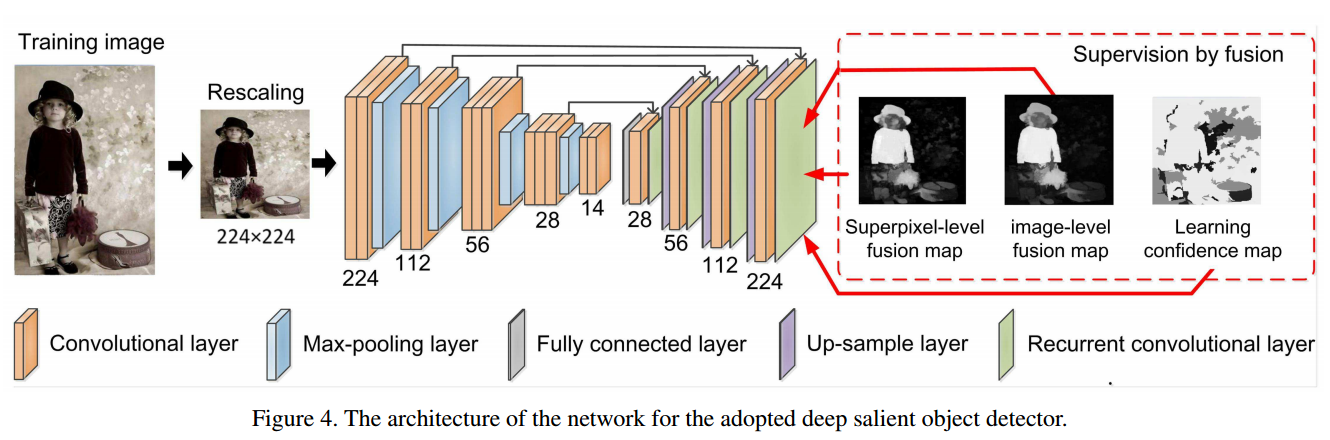
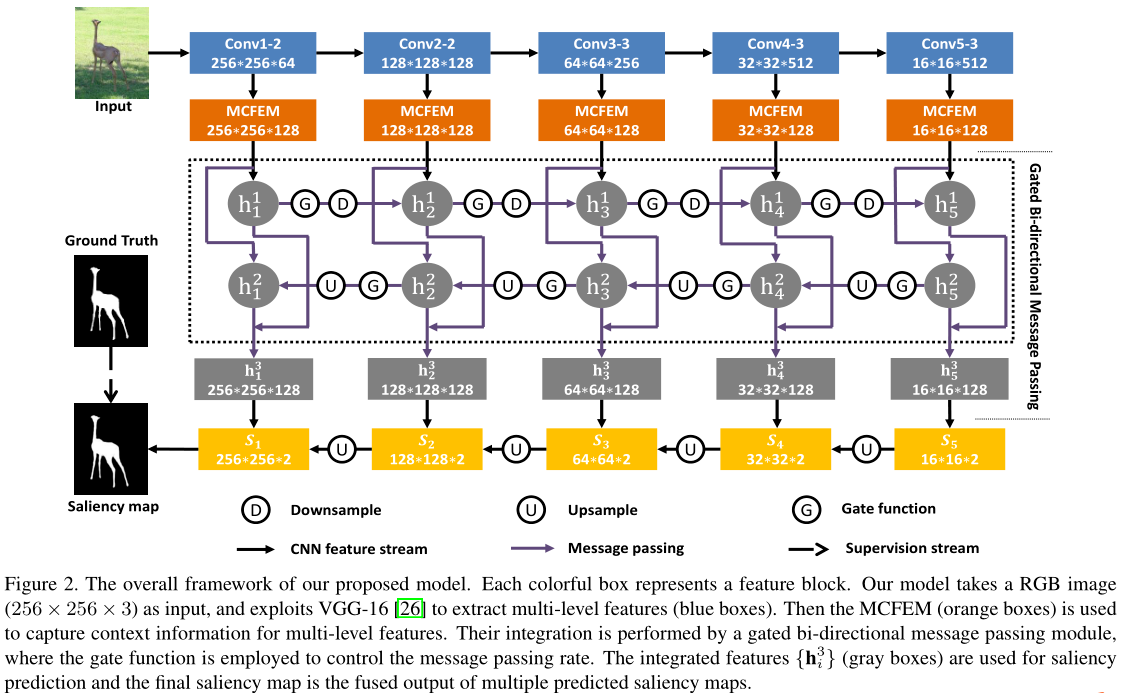
• BDMP (A bi-directional message passing model for salient object detection) 使用具有各种接收场的卷积层来确定多级特征,并通过门控双向路径实现层间交换。 重新定义的功能以自上而下的方式融合。
• RLN (Detect globally, refine locally: A novel approach to saliency detection) 使用类似inception的模块来净化低级功能。自上而下路径中的循环机制进一步改善了组合特征。边界改善网络增强了显著性输出。
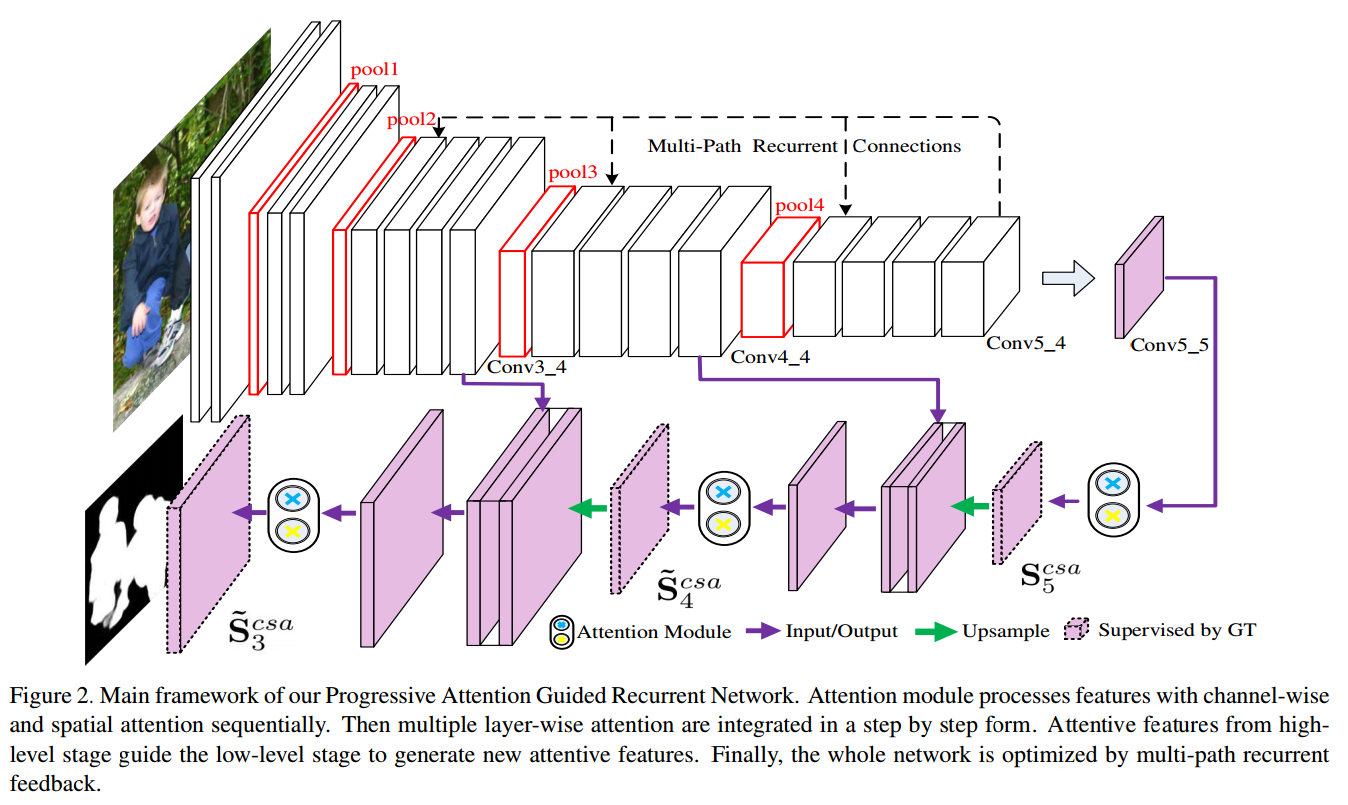
• PAGR (Progressive attention guided recurrent network for salient object detection) 通过合并多路径循环连接以将更高级别的语义转移到更低层,增强了特征提取路径的学习能力。 自上而下的路径嵌入了几个通道空间注意模块,用于重新定义功能。
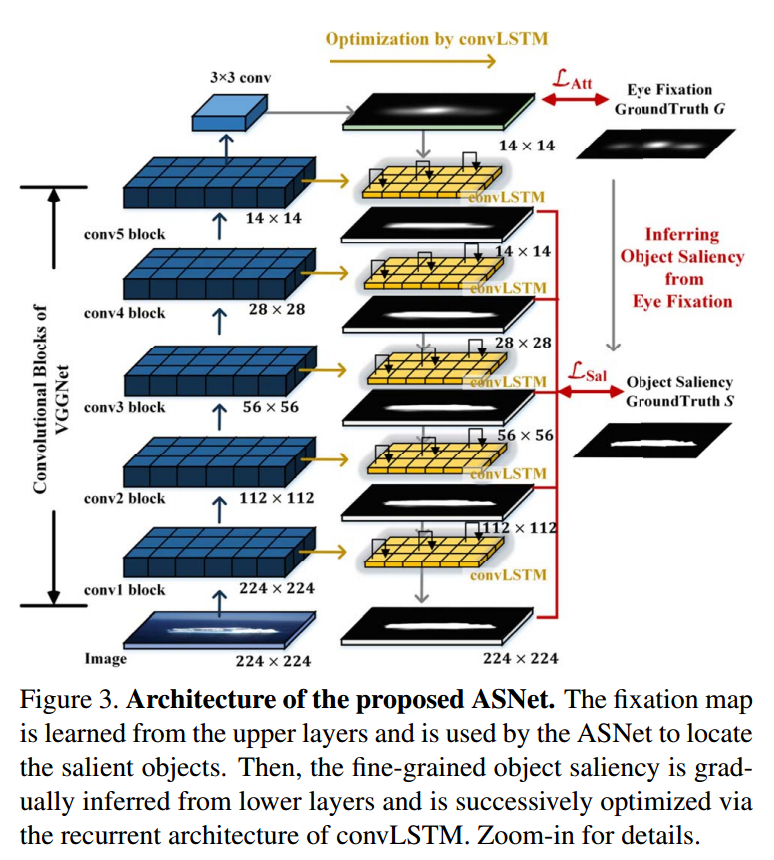
• ASNet (Salient Object Detection Driven by Fixation Prediction) 我们建立了一个名为Attentive Saliency Network(ASNet)的新型神经网络,该网络学习从fixation map 中检测显着对象。在前馈传递中学习粗糙的fixation map,然后利用一堆convLSTM通过从连续的较浅层中结合多级特征逐个像素来迭代地推断显著对象。
• PiCANet (PiCANet: Learning Pixel-wise Contextual Attention for Saliency Detection) 将全局和局部像素级上下文关注模块分层嵌入到U-Net结构的自上而下路径中。
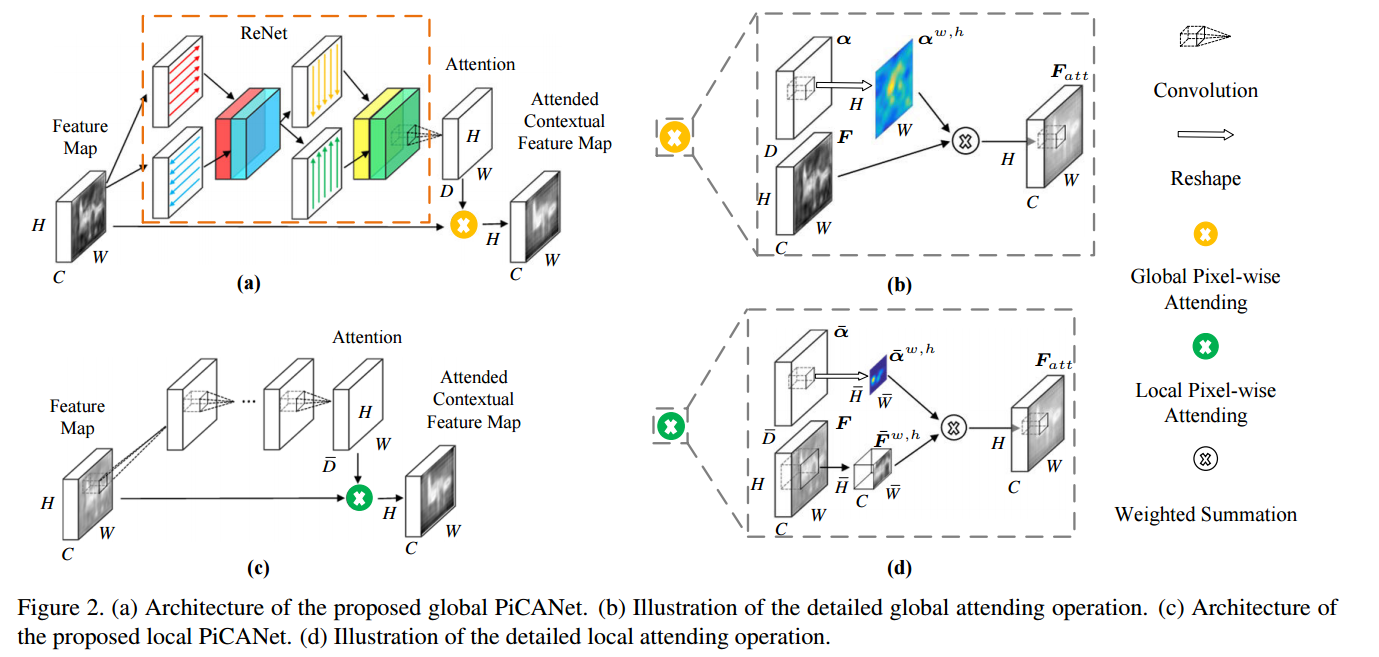
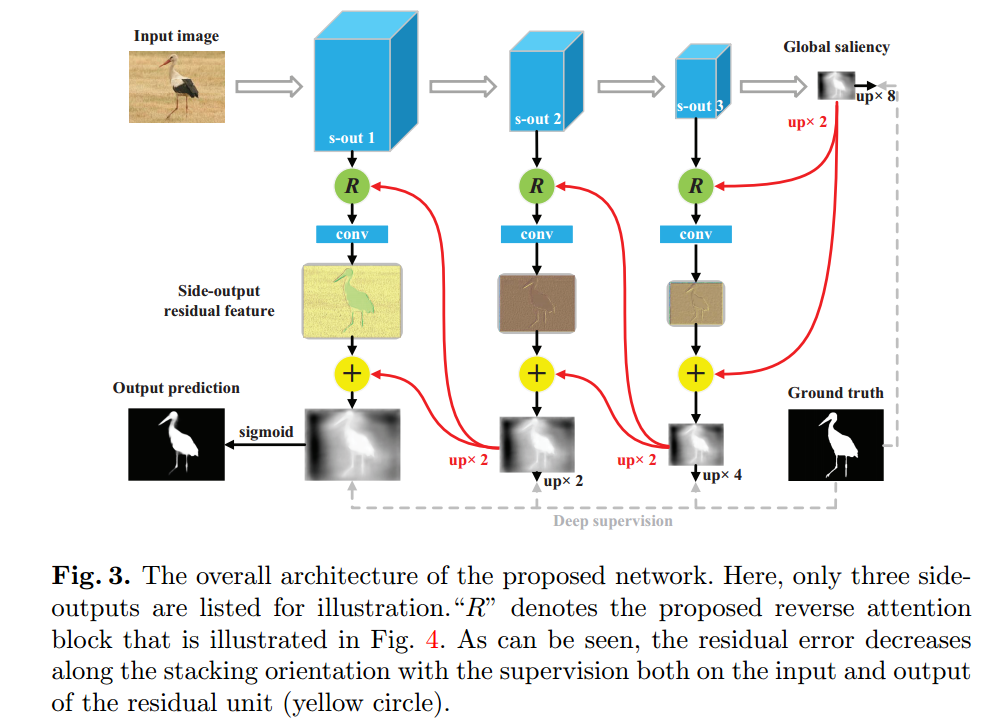
• RAS (Reverse Attention for Salient Object Detection) 在自上而下的途径中嵌入反向注意(RA)块以指导残差显著性学习。 RA块使用更深层次输出的补充来强调非目标区域。
5) Branched network 分支网络是单输入多输出结构,其中底层共享以处理公共输入,顶层专用于不同输出。 其核心方案如fig.2(f)所示。
• SU (Saliency unified: A deep architecture for simultaneous eye fixation prediction and salient object segmentation,找不到此文资源) 在分支网络中执行眼动点检测(FP)和SOD。 共享层捕获语义和全局上下文显著特征。 FP分支学习从顶部特征推断出fixations,而SOD分支聚合侧面特征以更好地保留空间线索。
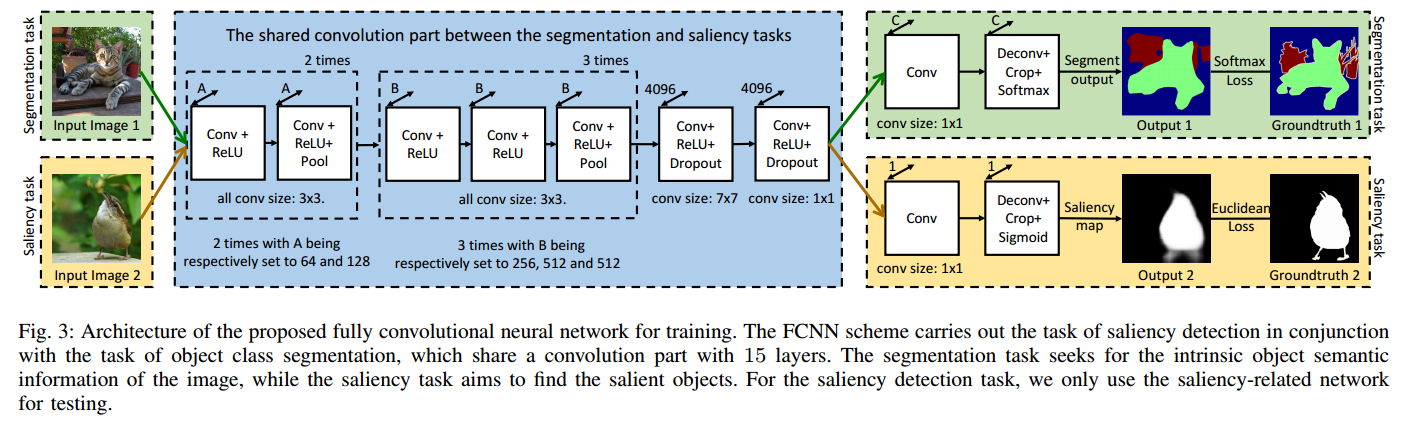
• DS (Deepsaliency: Multi-task deep neural network model for salient object detection) 由SOD分支和语义分段分支组成,共享底层以提取语义丰富的特征。 每个分支由一系列卷积和反卷积层组成,以产生像素预测。
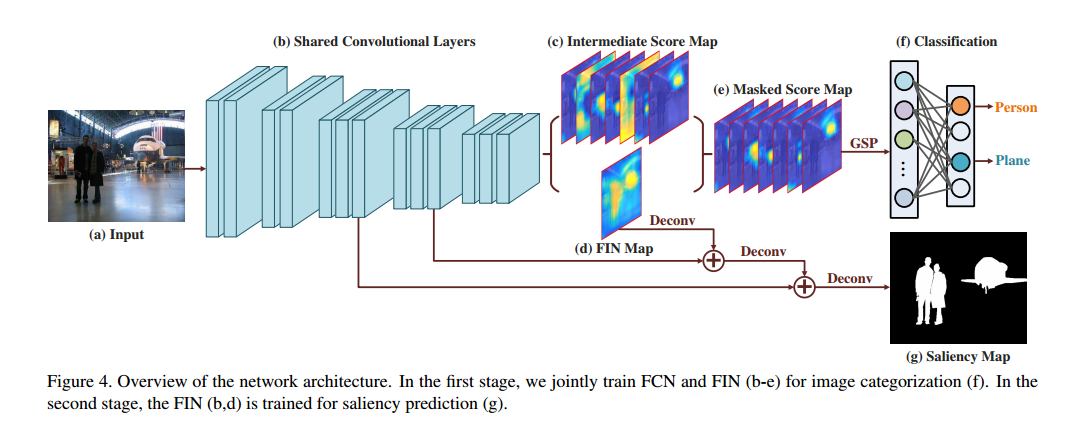
• WSS (Learning to detect salient objects with image-level supervision) 由图像分类分支和SOD分支组成。 SOD分支受益于在图像级监督下训练的特征,并以自上而下的方案产生初始显着性图,其进一步由迭代条件随机场(CRF)重新定义并用于微调SOD分支。
• ASMO (Weakly supervised salient object detection using image labels) 与WSS执行相同的任务,并在弱监督下接受培训。 主要区别在于ASMO中的共享网络使用多流结构来处理不同尺度的输入图像。
• C2S-Net (Contour knowledge transfer for salient object detection) (1)通过将训练过的轮廓检测模型自动转换为显著性分割模型;(2)提出了一种基于已训练轮廓检测网络的新型轮廓到显著网络(C2S-Net);(3)介绍了一种简单而有效的contour-to-saliency transferring 方法,以减小轮廓和显着对象区域之间的误差(即mask标记方法)
(3) 基于混合网络(Hybrid-Network)的模型 一些深度SOD方法结合了基于MLP和FCN的子网,旨在利用多尺度上下文产生边缘保留检测(见fig.2(g))。
• DCL (Deep contrast learning for salient object detection) 网络包括两个部分,一个pixel-level fully convolutional stream和一个segment-wise spatial pooling stream。第一步产生一个显著图,第二步产生 segment-wise features和显著性间断点。最后一个全连接CFR模型可以合并改善。
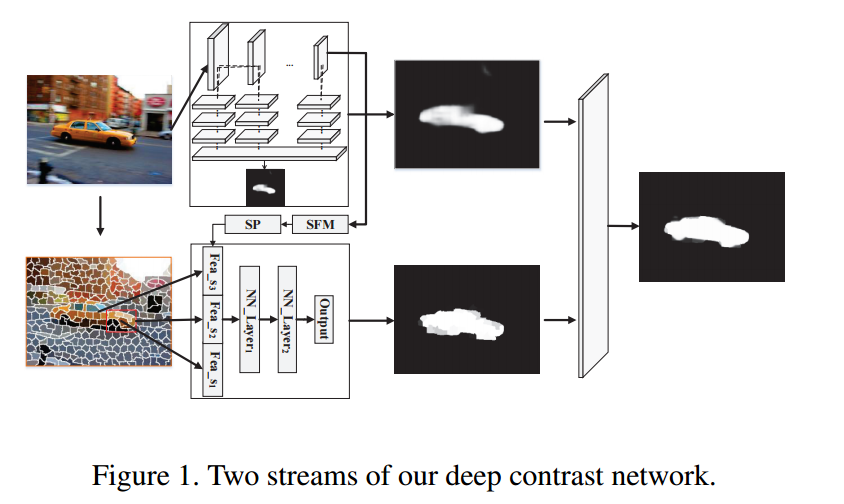
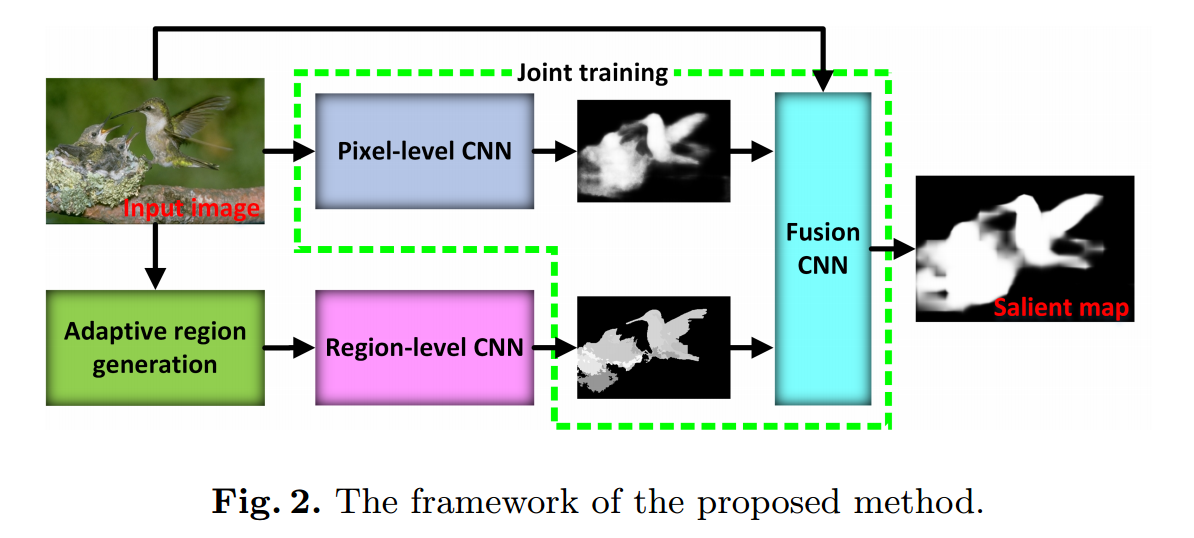
• CRPSD (Saliency detection via combining regionlevel and pixel-level predictions with cnns) 结合了像素级和超级像素级别显着性。前者是通过融合FCN的最后和倒数第二侧输出特征生成的,而后者是通过将MCDL应用于自适应生成区域而获得的。 只有FCN和融合层是可训练的
第二节:监督级别
根据人类注释的显著性masks是否用于训练,深度SOD方法可以分为完全监督方法和无/弱监督方法。
(1) 基于完全监督方法的模型
大多数深度SOD模型都使用大规模的逐像素(pixelwise:不知道 这个怎么翻译最准确)人工注释进行训练。这些完全监督的方法的成功在很大程度上受益于大量的手动注释数据。然而,对于SOD任务,获得大规模像素级注释是耗时的并且需要大量且密集的人类标记。此外,在精细标记的数据集上训练的模型往往过度,并且通常很难概括为现实生活中的图像。因此,如何用较少的人类注释训练SOD成为越来越受欢迎的研究方向。
(2) 基于无/弱监督方法的模型、
非/弱监督学习是指没有任务特定的真值监督的学习。为了摆脱费力的手动标记,一些SOD方法努力使用图像级分类标签或由启发式非监督SOD方法或其他应用程序生成的伪像素明显注释来预测显着性。实验表明这些方法与现有技术具有可比性。
1) 类级别监督(Category-level supervision) 已经表明,用图像级标签训练的分层深度特征具有定位包含目标区域的能力,这有望提供用于检测场景中的显著对象的有用提示。 因此,当前的大规模图像分类数据集也可用于训练深度SOD模型以定位显著对象。
• WSS (Learning to detect salient objects with image-level supervision) 首先使用ImageNet预先训练双分支网络以预测一个分支处的图像标签,同时估计另一个分支处的显著图。 估计的地图由CRF重新定义并用于调整SOD分支。
• LICNN (Learning to detect salient objects with image-level supervision) 它依赖于ImageNet预训练的图像分类网络,以生成“post-hoc”显著图。 由于横向抑制机制(lateral inhibition mechanism),它不需要与任何其他SOD注释进行明确训练。
2) 伪像素级别监督(Pseudo pixel-level supervision) 虽然提供信息,但图像级标签很稀疏,无法产生精确的像素显著性分割。 一些研究人员提出利用传统的非监督SOD方法或轮廓信息来自动生成噪声显著图,这些显著图逐步被重新定义并用于提供精确的像素级监督,以训练更有效的深度SOD模型。
• SBF (Supervisionbyfusion:Towards unsupervised learning of deep salient object detector) 通过融合过程生成显著性预测,该融合过程整合了由几个经典的非监督的显著物体检测器,在图像内和图像间水平产生的弱显著图。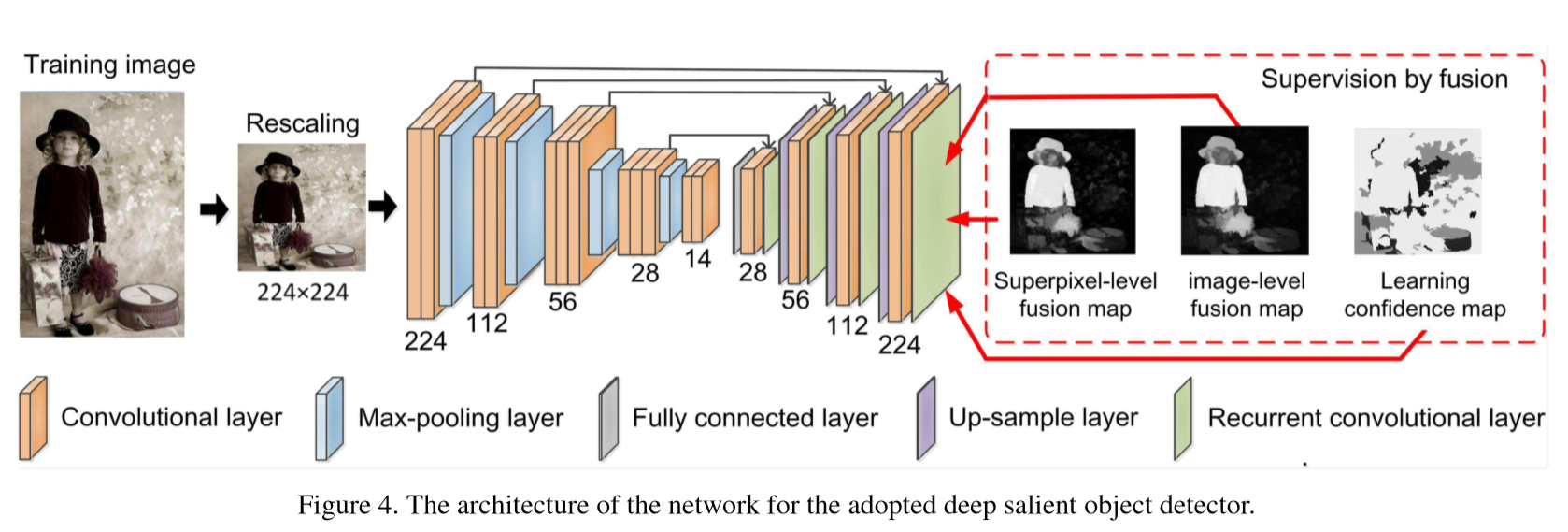
• ASMO (Supervisionbyfusion:Towards unsupervised learning of deep salient object detector) 训练具有图像分类标签的多任务FCN和启发式非监督SOD方法的噪声图。 前三级激活图的粗略显著性和平均图被馈送到CRF模型中以获得用于微调SOD子网的精细图。
• DUS (Deep unsupervised saliency detection: A multiple noisy labeling perspective) 受几种传统的非监督SOD方法启发,生成的噪声显著图中的潜在显著性和噪声模式,并为下一次训练迭代产生精确显著性图。
• C2S-Net (Contour knowledge transfer for salient object detection) 使用CEDN从轮廓生成像素方式的显著性掩模并训练SOD分支。 轮廓和SOD分支交替地相互更新并逐步输出更精确的SOD预测。
第三节:学习范式
从不同学习范式的角度来看,SOD网络可以分为单任务学习(STL)和多任务学习(MTL)。
(1) 基于单任务学习(STL)的方法
在机器学习中,标准方法是一次学习一个任务,即单任务学习。大多数深度SOD方法都属于这种学习范式。他们利用来自单一知识领域的监督来训练SOD模型,使用SOD域或其他相关域,例如图像分类。受人类学习过程的启发,从相关任务中学到的知识可用于帮助学习新任务,多任务学习(MTL)旨在同时学习多个相关任务。通过合并来自相关任务的额外训练信号的领域特定信息,模型的泛化能力得到改善。在任务之间共享样本也减轻了用于训练重参数模型(例如深度学习模型)的数据缺乏,特别是在任务相关注释有限的非/弱监督学范式下。
一些基于MTL的SOD方法在同一架构上串联训练不同的任务; 一些人通过将不同的客观索引项纳入损失函数来同时学习多领域知识;同时利用分支网络结构,其中底层是共享的,而顶层是任务特定的。
当前基于MTL的SOD模型通常训练有诸如显著对象子化,眼动点检测,图像分类,噪声模式学习,语义分割和轮廓检测之类的任务。 协作特征表示的学习提高了泛化能力以及所有(原文用both,疑笔误)任务的表现。
1) 显著目标计数(Salient object subitizing) 人类快速计算少量物品数量的能力被称为数感(记数)。 一些SOD方法同时学习显著对象的数量和检测。
• MAP (Unconstrained salient object detection via proposal subset optimization) 首先输出一组与显著目标的数量和位置匹配的得分边界框,然后基于最大后验执行子集优化公式,以共同优化显著对象提议的数量和位置。
• DSOS (Delving into salient object subitizing and detection) 使用辅助网络来学习显著目标计数,这通过交替其自适应权重层的参数来影响SOD子网。
• RSDNet (Delving into salient object subitizing and detection) 重新审视显着对象检测:多个显着对象的同时检测,排序和子图化
2) 眼动点检测(Fixation prediction) 旨在预测人眼注视位置。 由于其与SOD的密切关系,从这两个相关任务中学习共享知识有望改善两者的性能。
• SU (Saliency unified: A deep architecture for simultaneous eye fixation prediction and salient object segmentation) 在分支网络中执行眼动点检测和SOD。 共享层学习捕获语义和全局上下文显著性特征。 分支层经过特殊训练,可以处理任务特定问题。
• ASNet (Salient object detection driven by fixation prediction) 通过联合训练自下而上的途径来获得眼动图来学习SOD。 自上而下的路径通过在生物相关的视觉知识指导下结合多层次特征,逐步确定目标级显著估计。
3) 图像分类( Image classification) 图像类别标签可以帮助定位区分区域,区域通常包含显著目标候选区域。 因此,一些方法利用图像类别分类来辅助SOD任务
• WSS (Learning t odetect salient objects with image-level supervision) 学习前景推断网络(FIN)以预测图像类别以及估计所有类别的前景图。 FIN进一步调整以在CRF重新定义的前景图的监督下通过若干反卷积层预测显著图。
• ASMO (Weakly supervised salient object detection using image labels) 学习在传统的非监督SOD方法下的类别,在标签和伪真值显著图的监督下同时预测显著性图和图像类别。
4) 噪声模式模型 (Noise pattern modeling ) 从现有的启发式非监督SOD方法生成的带噪声显著图中学习噪声模式,旨在提取“纯”显着性图以监督SOD训练。
• DUS (Deep unsupervised saliency detection: A multiple noisy labeling perspective) 建议用传统的非监督SOD方法模拟噪声监测的噪声模式,而不是去噪。将 SOD和噪声模式建模任务在单一损失下联合优化。
5) 语义分割( Semantic segmentation ) 是为每个图像像素分配一组预定类别的标签。可以将视图视为类不可知的语义分割,其中每个像素被分类为属于显著目标或不属于显著目标。 在两者具有相似视觉外观的情况下,高级语义在区分显着对象和背景方面起着重要作用。
• RFCN (Saliency detection with recurrent fully convolutional networks) 首先在PASCAL VOC2010分割数据集上进行预训练,以学习语义信息,然后在SOD数据集上进行调整,以预测前景和背景图。 显着性图是前景和背景分数的softmax组合。
• DS (Deepsaliency: Multi-task deep neural network model for salient object detection) 它在分支网络中执行SOD和语义分割,其中共享层学习协作特征表示。 在训练期间,一个分支在每次训练迭代时更新另一个分支。
6) 轮廓检测( Contour detection) 响应属于对象的边而不考虑背景边界。 虽然看起来本质上不同,但轮廓可以为识别图像中的显着区域提供有用的先验。
• C2S-Net (Saliency detection with recurrent fully convolutional networks) 首先在PASCAL VOC2010分割数据集上进行预训练,以学习语义信息,然后在SOD数据集上进行调整,以预测前景和背景图。 显着性图是前景和背景分数的softmax组合。
第四节:学习范式
SOD的目标是定位和分割图像中最引人注目的对象区域。 如果输出掩码仅表示每个像素的显著而不区分不同的对象,则该方法属于对象级SOD方法; 否则,它是一个实例级SOD方法。
(1) 对象级的方法
大多数SOD方法是对象级方法,即被设计为在不知道各个实例的情况下检测属于显著对象的像素。
(2) 实例级的方法
实例级SOD方法产生具有不同对象标签的显著性掩码,其对检测到的显著区域执行更详细的解析。 实例级信息对于需要细微差别的许多实际应用至关重要。
• MAP (Unconstrained salient object detection via proposal subset optimization) 强调无约束图像中的实例级SOD。 它首先生成大量候选对象,然后选择排名靠前的对象作为输出。
• MSRNet (Instance-LevelSalientObjectSegmentation) 将显著实例检测分解为三个子任务,即像素级显著性预测,显著对象轮廓检测和显著实例识别。
第三章:显著目标检测数据集
随着SOD的快速发展,产生了大批相关数据集,这些数据集在SOD模型训练和Performance Benchmarking中都发挥着重要作用。Table.3总结了具有代表性的17个数据集。
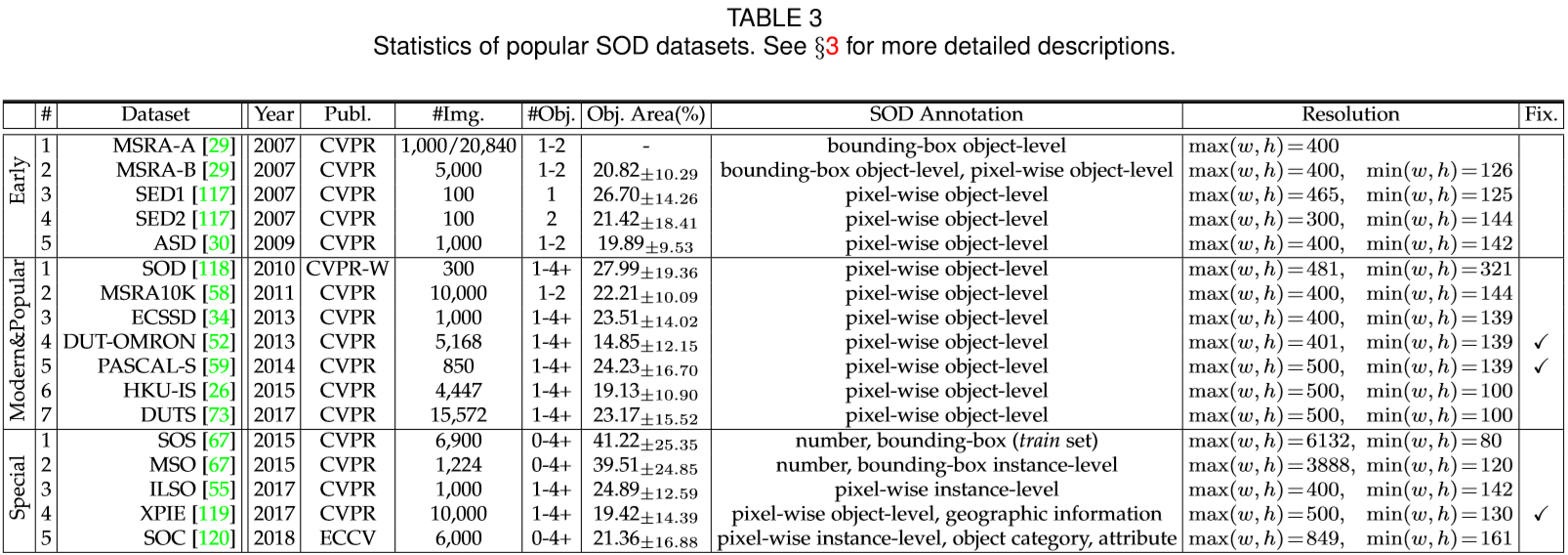
早期的SOD数据集通常收集通常只有一个显著目标的图像,提供的边界框注释被认为并不足以进行可靠评估。之后,出现了带有像素方式掩模的大型数据集,其中包含非常有限数量的对象和简单背景的图像。最近,在复杂混乱背景下且单幅图有多个显著目标的显著数据集被收集。特别是,一些数据集提供了额外的注释,如数字或实例级信息,便于其他相关任务或应用。图3显示了16个可用数据集的注释分布。

第一节:早期SOD数据集
早期的SOD数据集通常包含简单的场景,其中1~2个显著对象从简单背景中脱颖而出。
• MSRA-A (Learning to detect a salient object) 包含从各种图像论坛和图像搜索引擎收集的20,840张图像。 每个图像都有一个清晰,明确的对象,相应的注释是三个用户提供的边界框由“少数服从多数”选择制定。
• MSRA-B (Learning to detect a salient object) 作为MSRA-A的一个子集,有由9个用户使用边界框重新标记的5000个图像。与MSRA-A相比,MSRA-B的模糊度较低。 突出的对象。 MSRA-A和MSRA-B的性能变得饱和,因为大多数图像仅包括围绕中心位置的单个且清晰的显着物体。
• SED(Image Segmentation by Probabilistic Bottom-Up Aggregation and Cue Integration) 包括单个对象子集SED1和双个对象子集SED2,每个子集包含100个图像并具有逐像素注释。 图像中的物体通过各种低级线索(例如强度,纹理等)与周围环境不同。每个图像由三个主体分割。,如果至少两个主体同意,则将像素视为前景。
• ASD(Frequency-tuned Salient Region Detection) 包含1,000个逐像素真值。 从MSRA-A数据集中选择图像,其中仅提供显着区域周围的边界框。 ASD中的精确突出掩模是基于对象轮廓创建的。
1. http://www.wisdom.weizmann.ac.il/∼vision/Seg Evaluation DB/dl.html
2. https://ivrlwww.epfl.ch/supplementary material/RK CVPR09/
3. http://elderlab.yorku.ca/SOD/
4. https://mmcheng.net/zh/msra10k/
第二节:最近流行的SOD数据集
最近出现的更具挑战性的数据集往往含有相对复杂的背景且包含多显著对象的场景图像。 在本节中,我们将回顾七种最受欢迎且广泛使用的数据集。 它们的受欢迎程度大致归因于高难度和改进的注释质量。
• SOD (Design and perceptual validation of performance measures for salient object segmentation) 包含来自伯克利分割数据集的120张图像。每个图像由七个主题标记。许多图像具有多个与背景或与图像边界形成低色彩对比度的显著对象。提供像素注释。
• MSRA10K(Frequency-tuned Salient Region Detection) 也称为THUS10K,包含从MSRA中选择的10,000张图像,涵盖了ASD中的所有1,000张图像。 图像具有一致的边界框标记,并且进一步使用像素级注释进行扩充。 由于其大规模和精确的注释,它被广泛用于训练深SOD模型(见表2)。
• ECSSD(Hierarchical saliency detection) 由1000个图像组成,具有语义上有意义但结构复杂的自然上下文。 真值由5名参与者注释。
• DUT-OMRON(Saliency detection via graph-based manifold ranking) 包含5,168张背景相对复杂和内容多样性的图像。 每个图像都伴有像素级真值注释。
• PASCAL-S(The secrets of salient object segmentation) 由从PASCALVO 2010的VAL集合中选择的850个具有挑战性的图像。除了眼动点记录外,还提供了粗略的像素和非二值显著目标注释。
• HKU-IS(Visual saliency based on multiscale deep features) 包含4,447个复杂场景,其通常包含具有相对不同空间分布的多个断开连接的对象,即,至少一个显著对象接触图像边界。 此外,类似的前/后地面外观使这个数据集更加困难。
• DUTS(Learning to detect salient objects with image-levels supervision) 最大的SOD数据集,包含10,553个训练和5,019个测试图像。 训练图像选自ImageNet DET 训练集/值集,以及来自ImageNet测试集和SUN数据集的测试图像。 自2017年以来,许多深度SOD模型都使用了DUTS训练集训练(见表2)。
第三节:其他特殊的SOD数据集
除了上面提到的“标准”SOD数据集之外,最近提出了一些特殊的数据集,这些数据集有助于追踪SOD中的不同方面并产生相关的研究方向。 例如,其中一些使用实例级注释构建数据集; 一些包括没有显著物体的图像; 等等。
• SOS(Salient object subitizing) 为SOD计数,即,在没有昂贵的检测过程的情况下预测显著对象的数量。 它包含6,900个图像。 每个图像都标记为包含0,1,2,3或4+个显着对象。 SOS被随机分成训练(5,520张图像)和测试集(1,380张图像)。
• MSO(Salient object subitizing) 是SOS测试集的子集,包含1,224个图像。 它具有关于显着对象数量的更均衡的分布,并且每个对象都用边界框注释。
• ILSO(Instance-level salient object segmentation) 具有像素级实例级显著性注释和粗略轮廓标记的1,000个图像,其中基准测试结果使用MSRNet生成。 ILSO中的大多数图像都是从[26],[34],[52],[67]中选择的,以减少对显着对象区域的模糊性。
• XPIE(What is and what is not a salient object? learning salient object detector by ensembling linear exemplar regressors) 包含10,000个具有明确,显著目标的图像,这些图像用像素方式的基础事实进行注释。 它涵盖了简单和复杂的场景,并包含不同数量,大小和位置的显著对象。 它有三个子集:Set-P包含625个具有地理信息的感兴趣的地方图像; Set-I包含8,799个带有对象标签的图像; 和Set-E包括576个带有眼动点注释的图像。
• SOC(Salient objects in clutter: Bringing salient object detection to the foreground) 有6,000张图片,共有80个常见类别。 一半图像包含显著对象,其他图像不包含任何内容。 每个包含显著对象的图像都使用实例级SOD真值,对象类别(例如,狗,书)和具有挑战性的因素(例如,大/小对象)进行注释。非显著对象子集具有783个纹理图像和2,217个 真实场景图像(例如,极光,天空)。
第四章:评估指标
有几种方法可以衡量模型预测和人类注释之间的一致性。 在本节中,我们将回顾四种被普遍认可和广泛采用的SOD模型评估方法。
• Precision-Recall (PR) 根据二值化显著mask和真值来计算:
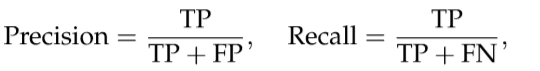
其中TP,TN,FP,FN分别表示真阳性,真阴性,假阳性和假阴性。 为了获得二进制掩码,应用一组范围从0到255的阈值,每个阈值产生一对精确/召回率以形成用于描述模型性能的PR曲线。
• F-measure 通过计算加权调和平均值来全面考虑精度和召回:
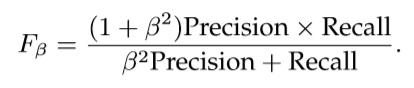
![]() 根据经验设定为0.3,以更加强调精度。 但很多方法并不是通告整个F-measure plot(不知道怎么翻译),而是直接使用plot中的最大Fβ值,而另一些方法使用自适应阈值,即预测显著图的平均值的两倍,以生成二元显著性映射并报告相应的平均F-measure值。
根据经验设定为0.3,以更加强调精度。 但很多方法并不是通告整个F-measure plot(不知道怎么翻译),而是直接使用plot中的最大Fβ值,而另一些方法使用自适应阈值,即预测显著图的平均值的两倍,以生成二元显著性映射并报告相应的平均F-measure值。
• Mean Absolute Error (MAE) 尽管它们很受欢迎,但上述两个指标未能考虑真正的负像素。 MAE用于通过测量归一化映射 ![]()
和真值掩码![]() 之间平均像素方向得绝对误差来解决这个问题:
之间平均像素方向得绝对误差来解决这个问题:
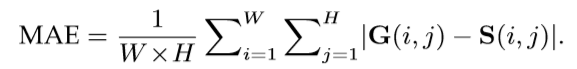
• Weighted Fβ measure (Fbw) 通过交替地计算精度和召回的方式直观地推广了F-measure。它将四个基本量TP,TN,FP和FN扩展为真实值,并根据邻域信息为不同位置的不同误差分配不同的权重(ω),定义为:

• Structural measure (S-measure) 与上述仅解决逐像素错误的评估方式不同,评估实值显著性映射与真实值之间的结构相似性。S-measure(S)考虑两个术语,So和Sr,分别指对象感知和区域感知结构的相似性:(下式α通常设为0.5)
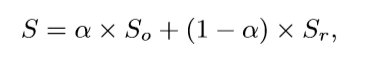
• Enhanced-alignment measure (E-measure) 同时考虑图像的全局均值和局部像素匹配:
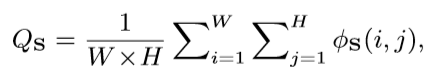
其中φS是增强的对齐矩阵,它分别在减去它们的全局均值后反映S和G之间的相关性。
• Salient Object Ranking (SOR) 是用于显著对象计数任务的评估方法,其值反映在同一图像中多个显著对象的的真值order(groud truth order ,不知怎么翻译好)rgG 与预测排序order(predictedrand order) rgS 之间的标准化Spearman的秩次相关性:
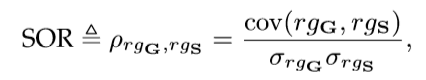
其中cov(·)计算协方差,σ{·}表示标准差。
第五章:基准
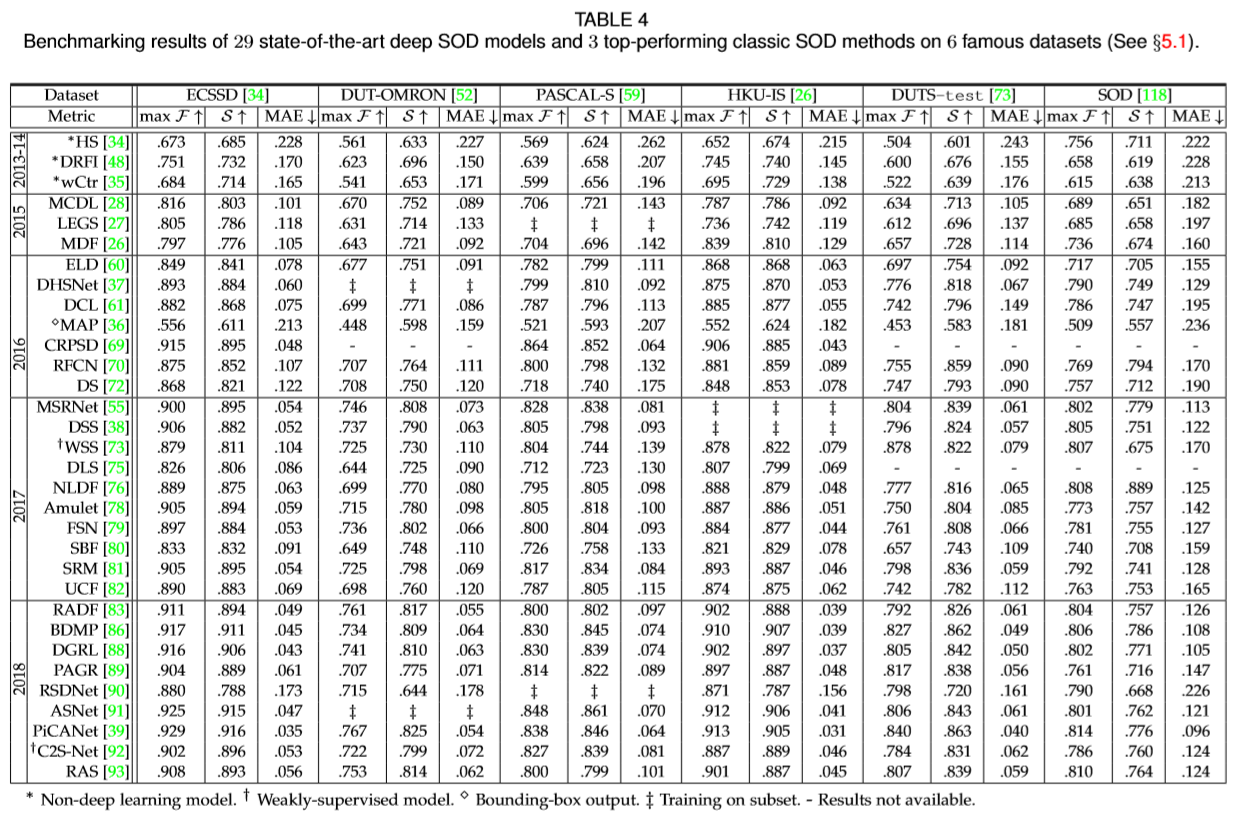
第一节:总体的基准表现
表4展示了在SOD研究中广泛使用和测试的6个流行数据集中29种最先进的深SOD模型和3种表现最佳的经典SOD方法的性能。三个评估度量,即最大Fβ,Smeasure和MAE,用于评估逐像素显著性预测精度和显著区域的结构相似性。
• Deep v.s. Non-deep learning 将表4中的3种表现良好的启发式SOD方法与深度方法进行比较,我们发现深度模型能够大大提高预测性能。这印证了基于大量训练数据的深度神经网络的强大学习能力。
• Performance evolution of deep SOD 自2015年第一次引入深度SOD模型以来,性能逐渐提高,证明了视觉显著性计算模型的飞速进展。在深度模型中,2016年提出的 MAP 表现最平凡普通,因为它只输出边界框 突出的对象。 这表明需要准确的注释以进行更有效的训练和更可靠的评估。
第二节:基于属性的评估
在SOD上应用DNN带来了显着的性能提升,但与前景和背景属性相关的挑战仍有待攻克。一个鲁棒性好的SOD网络应被期望处理各种复杂情况。在本节中,我们分析了混合基准测试中的三个性能最好的启发式SOD方法和三个性能最好深度方法的性能,并对所选SOD方法的性能进行了详细的基于属性的分析。

(1) 模型、基准与属性 Models, benchmark and attributes
我们选择三个表现最好的启发式模型,即HS [34],DRFI [48]和wCtr [35],以及三种最新的深度学习方法,即DGRL [88],PAGR [89]和PiCANet [39]来执行基于属性的分析。 所有深度模型都在同一数据集上进行训练,即DUTS [73]。 我们构建了一个混合基准,包括从6个数据集(每个300个)中随机选择的1,800个独特图像,即SOD [118],ECSSD [34],DUT-OMRON [52],PASCAL-S [59],HKU-IS [26] ]和DUTS [73]的测试集。 请注意,此基准测试也将用于§5.3和§5.4。
受[59],[120],[130]的启发,我们使用丰富的属性集注释每个图像,考虑显著的对象类别,挑战和场景类别。显著牧宝分为人类,动物,人造物品和NatObj(自然物体),其中NatObj包括各类自然物体,如水果,植物,山脉,冰山,水(如湖泊,条纹)等。这些挑战描述了一些经常使SOD方法陷入困难的因素,例如遮挡,背景聚类,复杂形状和物体尺度,如Table.5所示。
图像场景包括室内,城市和自然,其中最后两个表示不同的室外环境。 请注意,属性不是互斥的,即可以同时为图像分配多个属性。 一些样本图像如Fig.4所示。
(2) 分析 Analysis
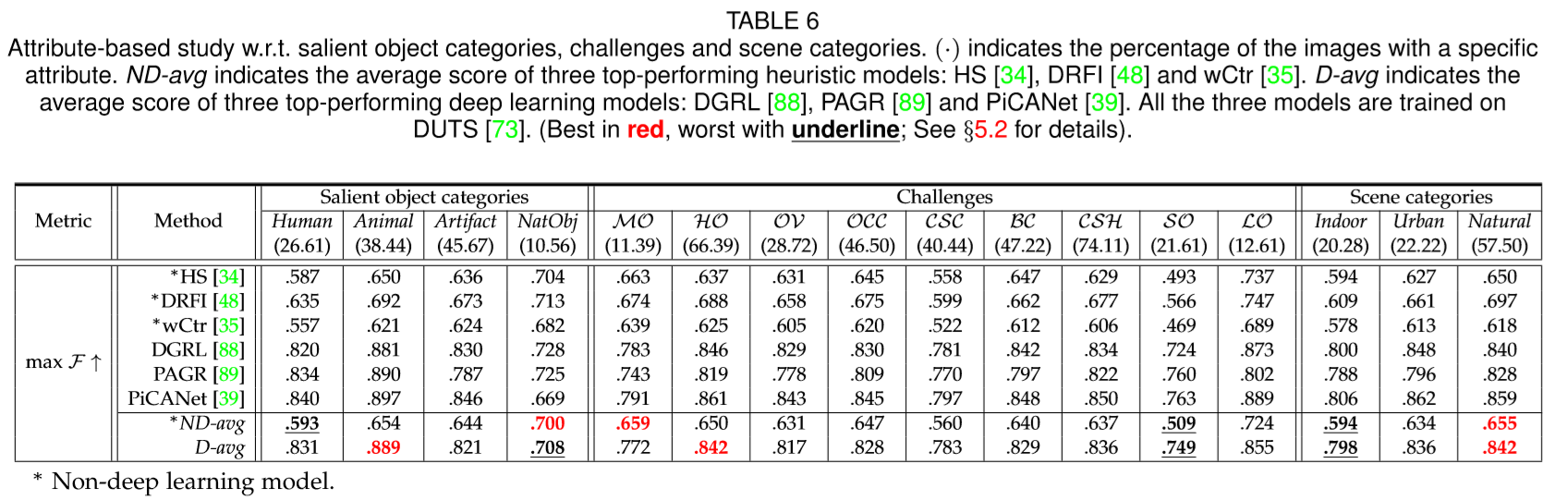
• 数据集中容易和困难的两个图像类别 ‘Easy’ and ‘Hard’ object categories. 深度与非深度SOD方法以不同方式审视对象类别(见 Table.6)。对于基于深度学习的方法,NatObj显然是各种显着对象类别中最具挑战性的类别,这可能是由于可用训练数据相对较少的缘故。动物类别似乎是最容易的,即使该部分的训练数据量不是最多的,这主要是由于其特定的语义含义。相比之下,启发式方法通常擅长分割显性NatObj类别的牧目标,而人类类别目标较难,这可能是由于缺乏高级语义学习。
• 最具和最不具挑战性的因素 Most and least challenging factors. Table.6 显示,由于DNN提取高级语义的强大能力,深度方法可以更高精度地预测HO。 启发式方法对MO表现良好,因为手工制作的局部特征有助于区分不同对象的边界。 由于精确标记小尺寸物体的固有困难,深度和非深度方法都表现出较低的SO性能。
• 最困难与最不困难的场景 Most and least difficult scenes. 当面对不同的场景时,深度和启发式方法的表现相似(表6)。 对于这两种类型的方法,自然场景是最简单的,这是合理的,因为它占据了超过一半的样本。 室内场景比城市场景更难,因为前者通常在有限的空间内包含一些物体,并且经常伴随严重的照明分布不均匀。
• 深度学习的其他优势 Additional advantages of deep models. 首先,如表6所示,深度模型在两个一般对象类别Animal和Artifact上实现了很大的改进,显示了它从大量示例中学习的能力。 其次,深度模型也对不完整的对象形状(HO和OV)不太敏感,因为它们学习高级语义。 第三,深度模型缩小了不同场景类别(Indoor v.s.Natural)之间的性能差距,显示出对各种背景设置的鲁棒性。
• 顶部与底部预测 Top and Bottom predictions. 从表7中,启发式方法对于多种自然对象(NatObj)比对人类目标表现更好。 相反,深度学习方法似乎对自然对象NatObj表现不好,而对动物目标表现不错。 对于挑战因素,深度学习方法和启发式方法都在处理复杂场景(CSC)和小对象(SO)遇到老问题。 最后,启发式方法在室外场景(即城市和自然场景)上表现最差,而深度方法在预测室内场景的显着性方面相对较差。
第三节:输入扰动的影响 Influences of Input Perturbations
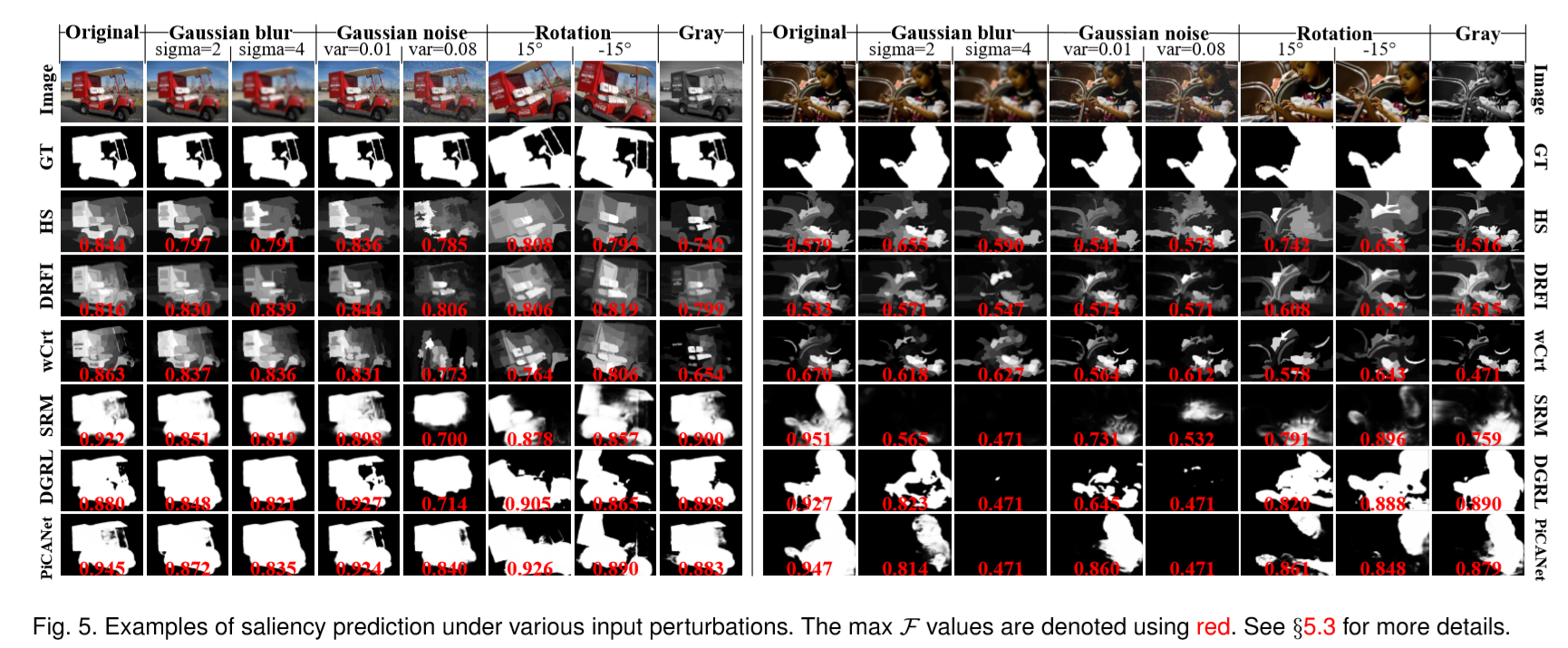
诸如噪声和模糊之类的输入扰动经常在现实世界的应用中引起麻烦。 在本节中,我们通过三种典型的启发式方法和三种深度方法研究了几种典型输入扰动的影响,并对混合基准进行了详细分析(见§5.2)。
实验输入扰动包括高斯模糊,高斯噪声,旋转和灰度。 更具体地说,为了研究不同程度模糊的影响,我们使用高斯核将sigma设置为2或4来模糊图像。对于噪声,我们选择两个方差值,即0.01和0.08,覆盖微小和中等幅度。 对于旋转,我们分别将图像旋转+ 15°和-15°,并剪切出具有原始高宽比的最大框。 使用Matlab rgb2gray函数生成灰度图像。
如§5.2所述,我们选择三种表现最佳的启发式模型,即HS [34],DRFI [48]和wCtr [35],以及三种在DUTS [73]上训练的开源深度方法,即SRM [81],DGRL [88]和PiCANet [39]用于研究输入扰动的影响。
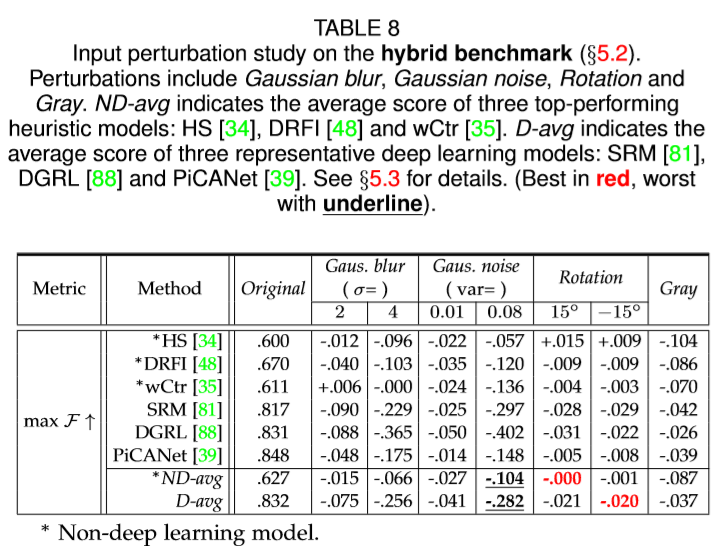
扰动结果如Table.8所示。总体而言,与深度方法相比,启发式方法对输入扰动的敏感度较低,主要是由于手工超像素级特征的鲁棒性。 具体来说,启发式方法几乎不受旋转的影响,但是面对强高斯模糊,强高斯噪声和灰色效应会有更明显对的性能下降。 在所有的输入扰动中,深度方法受到高斯模糊和强高斯噪声的影响最大,这极大地降低了在浅层接收领域中的局部信息的丰富性(which greatly reduce the richness of local information in the reception fields of shallow layers)。 由于空间池化的特征架构(Deep methods are relatively robust against Rotation due to spatial pooling in feature hierarchy),深度方法对于图像“旋转”相对鲁棒。
第四节:对抗性攻击分析 Adversarial Attacks Analysis
深度神经网络(DNN)模型已经在包括SOD在内的各种计算机视觉任务上取得了优越的效果。 然而,DNN却令人惊讶地容易受到对抗性攻击,其中输入图像中的一些视觉上难以察觉的扰动将导致完全不同的预测[131]。 尽管在分类任务中进行了深入研究,但SOD中的对抗性攻击显然未被充分探索。
在本节中,我们通过对三个有代表性的深度SOD模型进行对抗攻击来研究深度SOD方法的鲁棒性。 我们还分析了针对不同SOD模型的对抗性数据的可迁移性。 我们希望通过我们的观察能够揭示SOD的对抗性攻击和防御,并且可以更好地观测模型的漏洞。
(1)SOD模型对对抗攻击的鲁棒性 Robustness of SOD against Adversarial Attacks
我们选择三个有代表性的深度SOD模型,即SRM [81],DGRL [88]和PiCANet [39]来研究SOD模型对对抗攻击的鲁棒性。 所有这三个模型都在DUTS数据集上进行训练[73]。 我们试验了三种模型的ResNet [96]骨干版本。 该实验是在§5.2中引入的混合基准进行的。
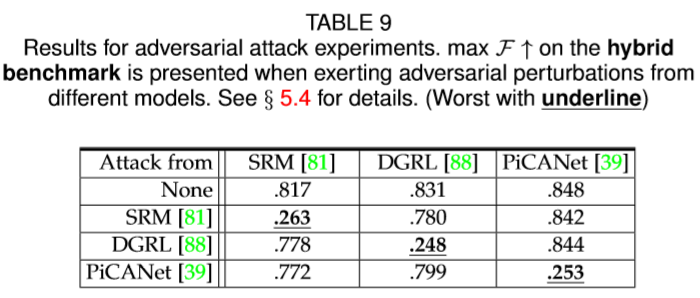
由于SOD可以被视为具有两个预定义类别的语义分割的特例,我们采用针对语义分割的对抗性攻击算法,Dense Adversary Generation(DAG)[132],用于测量深度SOD模型的鲁棒性。 DAG扰动在视觉上是不可察觉的,其每个通道中的最大绝对强度小于20。

对抗性示例如图6所示。定量结果列于表9中。可以看出,小的对抗性扰动会导致所有三种模型的性能急剧下降。 与随机施加的噪声相比,这种对抗性的例子往往导致更糟糕的预测(参见表8和9)。
(2)跨网络的可迁移性 Transferability across Networks
可转移性是指针对一个模型生成的对抗性示例在没有任何修改的情况下误导另一个模型的能力[133],其广泛用于针对现实世界系统的黑盒攻击。 鉴于此属性,我们通过使用为另一个生成的对抗性扰动攻击一个模型来分析SOD任务中可转移性是否存在。
3个研究模型(SRM [81],DGRL [88]和PiCANet [39])的可转移性评估见表9。 它表明DAG攻击基本在不同的SOD网络之间并没有很好的迁移。 三种模型中的每一种都在其他两种模型产生的攻击下实现了与无攻击相差不多的性能。 这可能是因为攻击的空间分布在不同的SOD模型中非常独立的缘故。
第五节:跨数据集泛化评估 Cross-dataset Generalization Evaluation
数据集在训练和评估不同深度模型方面发挥着重要作用。 在本节中,我们通过执行交叉数据集分析[134]来研究几个主流SOD数据集的泛华能力和硬度(hardness),即在一个数据集上训练代表性的简单SOD模型,并在另一个数据集上进行测试。
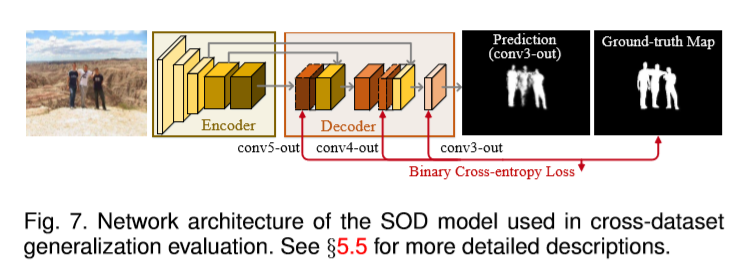
简单的SOD模型基本上是比较流行的自下而上/自上而下的编码器 - 解码器架构,其中编码器部分由VGG16 [95]的卷积层组成,解码器部分由三个卷积层组成,用于逐步更精确 像素显著性预测。 为了增加输出分辨率,第4个块中最大池化层的步幅减小到1,第5个卷积块的扩张速率被修改为2,并且移除了pool5层。 每个注意特征的侧输出通过具有Sigmoid激活的Conv(1×1,1)层获得,并由真值显著性分割图监督。 最终预测来自第3个解码器层。 网络架构的图示如图7所示。
表10总结了使用max F的跨数据集泛化的结果数据。每列显示在一个数据集上测试的所有训练模型的性能,预示测试数据集的硬度(hardness)。每行显示在所有数据集上测试的一个训练模型的性能,预示训练数据集的泛化能力。值得注意的是,由于各种训练/测试的标准,这些数字与前面部分中显示的基准值无法比较。什么是相对差异(怎么加了这句话,笔误?)。我们发现SOC [120]是最难的数据集(lowest column Mean others 0.619)。这可能是因为SOC [120]与其他数据集相比具有独特的位置分布,并且可能包含极大或小的显著对象。 MSRA10K [58]似乎是最简单的数据集(highest column Mean others 0.811,疑笔误,应为0.821),但是也有最差的泛化能力 (highest row Percent drop 17%)。 DUTS [73]则可认为是具有最佳的泛化能力的数据集((lowest row Percent drop−16%))。
第六章:讨论
第一节 模型设计
在下文中,我们将讨论对SOD模型设计几个很重要的因素和方向。
• 特征融合 Feature Aggregation. 分层深度特征的有效融合对于逐像素标记任务是很重要的,因为集成“多尺度”抽象信息是被认为有益的。现有的SOD方法的各种策略都是围绕着特征聚合,例如多流/多分辨率融合[55],自上而下自下而上融合[37]或侧输出融合[38],[78],[83]。与其他域的功能融合,例如眼动点预测,也可以增强特征表示[79]。此外,可以去学习其他密切相关的研究任务,如语义分割[135] - [137],看看它们进行特征融合的方法,这些语义分割方法从语义上有意义的特征学习用于预测像素级标签。
• 损失函数 Loss Function. 精心设计的损失函数在训练更有效的模型中也起着重要作用。 在[91]中,从SOD评估度量导出的损失函数用于捕获质量因子,并且已经凭经验显示以提高显着性预测性能。 最近的另一项工作[138]提出 直接优化the mean intersection-over-union loss (directly optimize the mean intersection-over-union loss),这会对语义分割及其二元情况(即前景 - 背景分割)产生影响。 为SOD设计合适的损失函数是进一步提高模型性能的重要考虑因素。
• 网络拓扑 Network Topology. 对于一个典型的例子,在ResNet [96]中,块输入通过跳连接直接添加到块输出,从而可以训练非常深的网络。 DenseNet [139]进一步将每一层与其所有后续层链接起来,极大地减轻了梯度消失并促进了特征重用。 CliqueNet [140]在块内的两个任意层之间添加双向连接,最大化通过层的信息流并多次重用层参数。
除了手动确定网络拓扑外,一个有前景的方向是采用自动机器学习(AutoML),旨在找到性能最佳的算法,尽可能减少人为干预。 有一个很有前景的例子,比如神经架构搜索(NAS)[141]能够从头开始生成用于图像分类和语言建模的有竞争力的模型。 它使用强化学习(RL)去训练controller RNN生成网络超参数[142]。 通过迁移学习[143],[144]可以减轻AutoML的计算成本,这使得它更有效地受益于更广泛的更复杂的任务。现有精心设计的网络拓扑和AutoML技术都为未来构建新颖有效的SOD架构提供了方向。
• 动态推理 Dynamic Inference. DNN丰富的冗余特征有助于增加其抵抗输入扰动的鲁棒性,同时在推理期间不可避免地引入额外的计算成本。除了使用一些静态方法(如内核分解[145]或参数修剪[146])提高DNN的计算效率外,一些工作还研究了在测试过程中动态地改变计算量。Bengio等人 [147] 建议在预测期间选择性地激活多感知器(MLP)网络中的部分神经元。 一旦添加的中间分类分支的分类熵低于阈值,BranchyNet [148]就会提前停止计算。最近提出的ConvNet-AIG [149]根据输入图像自适应地更新其推理图,并且仅运行与某些类相关的层的子集。 与静态方法相比,这些动态方法在不降低网络参数的情况下提高了效率,因此很容易抵抗基本的对抗性攻击(例如ConvNet-AIG [149])。对于SOD模型设计,合并合理有效的动态网络结构有望提高效率和性能。 例如,有些层的特殊部分可以用作处理具有各种属性的输入图像。
第二节 数据集收集
基于之前的观察,我们建议将来应考虑数据选择偏差,注释不一致性,注释质量和领域知识来构建SOD数据集。
• 数据选择偏差 Data selection bias. 大多数现有的SOD数据集都会收集包含背景相对清晰中的显著对象的图像,同时丢弃不包含任何显著对象或背景过于聚集的图像。 但是,实际应用程序通常面临更复杂的情况,这会对在这些数据集上训练的SOD模型造成严重挑战。 因此,以真实地反映现实世界去创建数据集的挑战对于提高SOD的泛化能力至关重要[41]。最近已经有一些用于解决选择偏差尝试。 例如,SOC数据集[120]收集一些非显著图像以更好地模仿真实世界场景。 鼓励更多此类努力去进一步提高针对现实生活中显著性预测性能的挑战。
• 注释不一致 Annotation Inconsistency. 虽然现有的SOD数据集在最新SOD模型的训练和评估中发挥着重要作用,但不应忽视和忽略不同SOD数据集之间的不一致性。 内部数据集不一致是不可避免的,因为数据可能不会被相同的主题和相同的规则/条件注释。

图8显示了一些典型的例子。 顶行中的两个案例表示实例级注释不一致,其中存在多个可比较的实例,但是其中的全部或几个将被注释为显着对象。中间行的左侧案例显示了阴影的不一致性。 中间行中的右侧情况描述了某些类别的显著对象选择的不一致性,例如两幅图像中的图像并不一致地标记为显著或非显著。左下方的箱子以不同的精度呈现自行车的注释。 右下方的情况显示了在标记湖面镜面反射的显著性时的不一致性。
• 粗糙的 vs. 精细注释 Coarse v.s. Fine Annotation. 对于数据驱动学习,标签质量对于训练可靠的SOD模型和真实地评估它们至关重要。SOD注释质量的第一个改进是用像素方式掩码替换边界框来表示显著对象[30],[121],这极大地提高了SOD模型的性能。鉴于此,几乎所有最新的SOD数据集都使用像素级标签进行了注释。 然而,不同样品的标记精度可能不同。 例如,图8中自行车的精度明显不同。目前还没有关于标签质量与SOD模型性能之间关系的全面研究。 而关于语义分割的像素级标签质量的类似研究[150]表明,(1)训练用大量粗标记数据可以达到用较少数量的优质标记数据训练所得的性能,(2)使用粗标签先进行预训练然后使用少量的优质标签进行微调与使用大量优质标签的训练所得的模型相比是可以匹敌的。虽然有些作品已经证明了高质量标签的重要性[120],[151],但对SOD模型训练和数据集构建的需求还需要更深入的研究。
• 特定领域的SOD数据集 Domain-specific SOD datasets. SOD具有广泛的应用场景,例如自动驾驶,电子游戏,医学图像处理等,因为它有助于定位感兴趣的对象和情景感知。由于不同的场景设置,考虑到视觉外观和语义成分,这些应用中的显著性机制可能与传统自然图像设置中的显著性机制完全不同。因此,必须收集这些应用领域的特定SOD数据集。 领域特定数据集带来的好处已在FP中观察到,其中在专门收集的数据集上训练的显著性模型优于其他模型,用于预测人群注视点(predicting fixations on crowds,可以见下图,之后看看这篇论文究竟是什么意思 )[152],网页[153] - [155]或驾驶期间[156],[157]。比较有前景的是,收集领域特定的数据可以帮助建立特定显著性模型,与常规训练的SOD模型相比,可以在特定任务设置下更好地检测和分割显著对象[47]。

第三节 显著性排名和相对显著性
传统上,显著对象通常是指场景中最显著的对象或区域。 然而,对于存在多个显著对象的图像,这种“简单”定义可能不充分。 因此,如何评估共存对象或区域的显著性对于设计SOD模型和注释SOD数据集是重要的。
一种可能的解决方案是对对象或区域的显著性进行排名。 基于人类观察的眼动点预测通常由场景中的显著物体位置所引导,Li等人。 [59]建议使用眼动点对图像语义的显著性进行排名。
另一种解决方案是将几个观察者投票来决定多个突出实例的相对显著性。例如,Islam等人[90] 使用一系列真值图来训练SOD模型,这些真值图由不同观察者定义的不同显著性标准来制定,而不是经典的二元真值图。不同实例之间的相对显著性也可以作为显著对象计数的重要线索。
第四节 与眼动点的关系
眼动点预测(FP)和SOD都与计算机视觉领域中视觉显著性的概念密切相关。 FP可以追溯到20世纪90年代早期[158],旨在预测人类第一眼关注的焦点。 SOD的历史可以追溯到[29],[30],并尝试识别和分割场景中的显著对象。 FP起源于人类认知和心理学界,而SOD则更像是由应用驱动的“计算机视觉”目标任务。 由于显著性检测的不同目的,两者的生成显著图实际上是完全不同的。
FP和SOD之间的强相关性已在历史上进行了探索。在Mishara等人的早期工作[159]中,人类眼动点用于识别感兴趣的对象以进行分割,这种任务被称为“主动视觉分割”。后来,一些研究(例如,[41],[59],[160],[161])定量地探索和证明显著判断与人类自由眼动点预测之间存在明显的强相关性。Borji等人[161]同样表明,对场景中“最显著物体”的定义,即 吸引大部分人注释的物体定义 与 人们第一眼就观察的物体的定义,是非常相近的。
虽然密切相关,但只有少数模型同时考虑FP和SOD任务。 李等人 [59]提出了一种有效的SOD组合算法,该算法先进行分割处理,随后使用FP的方法进行显著性区域排序。FSN [79]融合了眼动流[99]和语义流[95]的输出以预测显著性,但它不会同时学习这两个任务。
有一些SOD数据集伴随着眼动点数据,例如PASCAL-S [59],DUT-OMRON [52]和XPIE的子集[119]。 但是,SOD注释通常不受眼动点数据的指导。 例如,PASCAL-S的显著性掩模是基于预分段区域构建的,使用鼠标点击从中选择“显著”区域。 DUT-OMRON [52]标记了显著物体的边界框,而没有考虑初步阶段的固定。 相反,固定数据的过滤过程受到带注释的边界框的影响。XPIE [119]的眼动点子集中的图像是从[162]和[163]中的数据集中收集的。 但是,显著性二元掩码的注释过程与眼动数据无关,眼动点数据与没有眼动点的其他子集中的图像相同。考虑到SOD和FP之间的强关联性,建议在将来构建SOD数据集期间注释显著性掩模时使用眼动点信息,如Judd-A [161](图像SOD)和VOS [164]中所做的那样 (视频SOD)。
更多关于SOD和FP关系背后的基本原理、模型和数据集的研究被鼓励用于生成更符合人类视觉选择机制的模型。
第五节 用语义特征提升SOD
语义信息在语义分割,目标检测,目标类别探测等高级视觉任务中至关重要。相比之下,它在SOD中的作用基本上未被充分探索,部分原因是SOD似乎更多地依赖于低级别视觉线索而不是高级语义信息。 实际上,高级语义信息可以为检测显著对象提供非常有用的指导,特别是在诸如背景高度杂乱的困难场景中。
已经有一些努力尝试去促进具有语义信息的SOD [70],[72]。 除了使用分割数据集预先训练SOD模型[70],或利用多任务学习同时训练SOD和语义分割[72],一个可行的方向是通过结合某些对象检测方法中的分割特征来增强显著特征,或者通过级联[165]或使用激活[166]。 这种特征强化利用了嵌入在像素类别中的语义来帮助估计每个像素的类不可知显著性值,尤其是在视觉模式不足以将目标与其周围环境区分开的情况下。
第六节 现实场景中SOD的应用
DNN通常被设计为深度和复杂的,以便增加模型容量并在各种任务中实现更好的性能。 然而,需要更加现实和轻量级的网络架构来满足移动和嵌入式应用的需求,例如机器人,自动驾驶,增强现实等。由于模型裁剪推而导致的精度和泛化能力的降低需要尽可能小。
为了促进SOD在实际场景中的应用,利用模型压缩[167]技术来学习具有竞争力预测精度的紧凑、快速的SOD模型是相当有价值的。 Hintonetal [168]扩展了[167]中的想法,并提出了知识蒸馏(KD),它能够在大型教师模型的软输出(soften outputs)的监督下训练深度浅或压缩的学生模型,可以使图像分类的精确度下降率很小。 罗梅罗等[169]通过利用教模型中的中级特征作为学生网络训练的“提示”,进一步扩展了KD。 当训练更快的物体检测模型时,这种压缩技术已经显示出在提高泛化能力和减轻缺陷方面的有效性[170],与图像分类相比,这是一项更具挑战性的任务。 值得探索利用这些技术压缩SOD模型,以实现快速准确的显著性预测。
还有一些应用程序,其中SOD的输入是来自其他模态(例如depths)的图像,并且与RGB数据集相比,标记数据是有限的。为了充分利用现有的RGB SOD数据集,除了使用通用RGB SOD特征表示进行初始化之外,还可以进行网络处理。 在其他模态的数据中,可以使用交叉模态蒸馏(cross modal distillation)[171],其利用新的模态转移从标记的RGB图像到配对的未标记数据,并有效地学习特征层次。 通过这种方式,一般SOD的现有DNN架构可以扩展到其他模态,而无需收集额外的大规模标记数据集。
第七章:结论
在本文中,我们尽我们所掌握的知识,首先对SOD进行全面探讨,其重点是围绕深度学习技术。 我们首先从几个不同的角度仔细探讨和组织基于深度学习的SOD模型,包括网络架构,监督水平等。然后,我们总结了流行的SOD数据集和评估标准,并编制了主要SOD方法的全面性能的基准。
接下来,我们研究了几个以前未充分探索的问题,并在基准测试和基线方面做出了新的努力。 特别是,我们通过编译和注释新数据集并测试几个有代表性的SOD算法来执行基于属性的性能分析。 我们还研究了SOD方法关于各种输入扰动的稳健性。 此外,我们在SOD中首次研究了SOD深层模型的鲁棒性、可转移性、对抗性攻击。 此外,我们通过交叉数据集推广实验评估现有SOD数据集的概括性和硬度。 我们最终会深入了解SOD在深度学习时期的几个未解决的问题和挑战,并提供有关未来可能的研究方向的深刻讨论。
所有显着性预测图,我们构建的数据集,注释和评估代码都可以在 https://github.com/wenguanwang/ SODsurvey 上公布。 总之,由于深度学习技术的惊人发展,SOD已经取得了显着的进步,但它仍然具有明显的改进空间。 我们希望这个综述能够提供一种有效的方法来了解最新技术,更重要的是,可以为未来的SOD探索提供帮助。
