
爬取数据入门指南
世界杯来了,想分析一下各个球员的比赛数据,然后预测今年的世界杯金靴奖,根据经验大家肯定普遍认为梅西,C罗,内马尔等球星概率大些;但经验毕竟是经验,数据才是最靠谱的,通过分析数据,可以评估一个球员的价值(当然,球员的各方面的表现(特征),都会有一个权重,最终衡量权重*特征值之和最高者的金靴概率胜算大些)。那么,如何获取这些数据呢?写段简单的爬取数据的代码就是最好的获取工具。本文以2014年的巴西世界杯球员为基础进行实践操作;
一、什么是爬数据?
网络爬虫(网页蜘蛛),是一种按照一定的规则,自动的抓取万维网信息的程序或者脚本;
学习一些爬数据的知识有什么用呢?
比如:大到大家经常使用的搜索引擎(Google, 搜狗);
当用户在Google搜索引擎上检索相应关键词时,谷歌将对关键词进行分析,从已“收录”的网页中找出可能的最符合用户的条目呈现给用户;那么,如何获取这些网页就是爬虫需要做的,当然如何推送给用户最有价值的网页,也是需要结合相应算法的,这就涉及到数据挖掘的的知识了;
比较小一些的应用,比如我们统计测试工作的工作量,这就需要统计一周/一月的修改单数量,jira记的缺陷数以及具体内容;
还有就是最近火热进行的世界杯,如果你想统计一下各个球员/国家的数据,并存储这些数据以供其他用处;
还有就是根据自己的兴趣爱好通过一些数据做一些分析等(统计一本书/一部电影的好评度),这就需要爬取已有网页的数据了,然后通过获取的数据做一些具体的分析/统计工作等。
二、学习简单的爬虫需要具备哪些基础知识?
我把基础知识分为两部分:
1、前端基础知识
HTML/JSON,CSS; Ajax
参考资料:http://www.w3school.com.cn/h.asp
http://www.w3school.com.cn/ajax/
http://www.w3school.com.cn/json/
2. python编程相关知识
(1)Python基础知识
基本语法知识,字典,列表,函数,正则表达式,JSON等
参考资料:http://www.runoob.com/python3/python3-tutorial.html
(2)Python常用库:
Python的urllib库的用法 (此模块我用的urlretrieve函数多一些,主要用它保存一些获取的资源(文档/图片/mp3/视频等))
Python的pyMysql库 (数据库连接以及增删改查)
python模块bs4(需要具备css选择器,html的树形结构domTree知识等,根据css选择器/html标签/属性定位我们需要的内容)
python的requests(顾名思义,此模块用于发送request请求的/POST/Get等,获取一个Response 对象)
python的os模块 (此模块提供了非常丰富的方法用来处理文件和目录。os.path.join/exists函数用的较多一些)
参考资料:这部分可以参考相关模块的接口API文档
三、简单小项目上手实践(附源码)
(1).爬取Kugou网站音乐,以歌手id为输入,下载歌手所有的专辑歌曲并以专辑名为文件夹存放下载的歌曲;
具体实现过程如下:
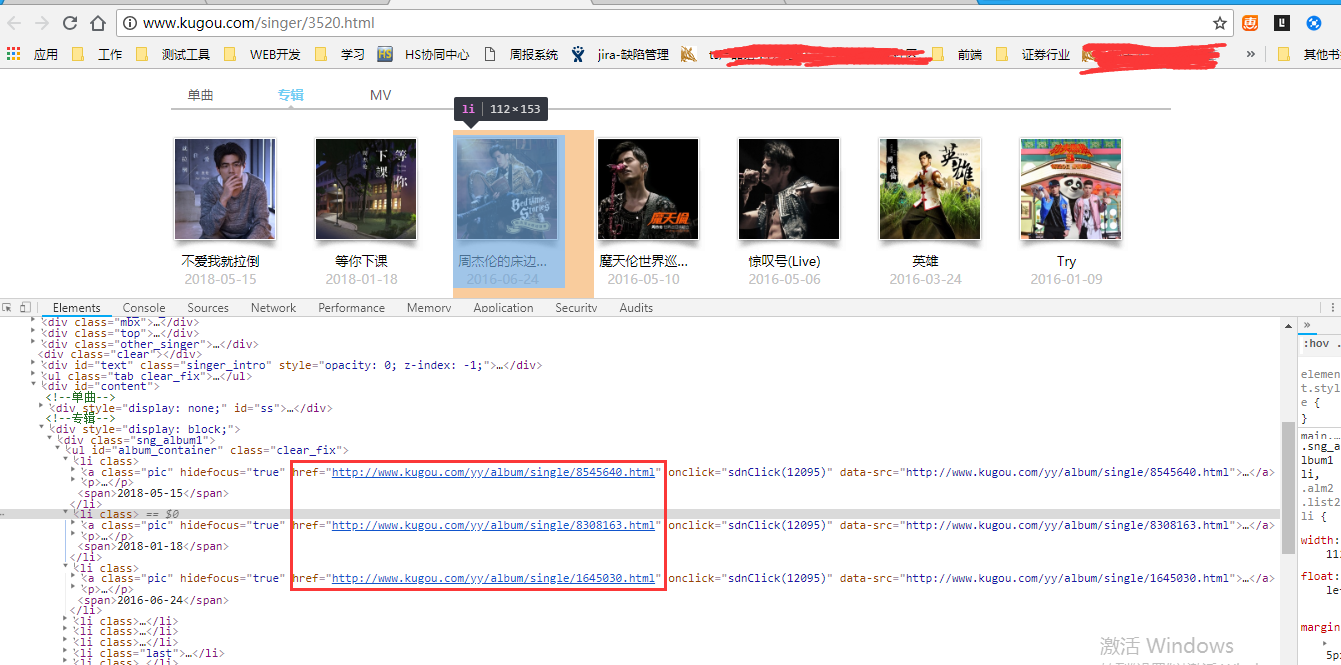
1.酷狗首页搜索歌手,进入歌手主页,获取url中的singId,例如朴树主页:http://www.kugou.com/singer/3520.html,其中3520即为singId;
2.根据歌手singerId可以获得歌手的所有专辑的albumId,例如 这是专辑的页面,http://www.kugou.com/yy/album/single/962593.html,其中962593为albumId
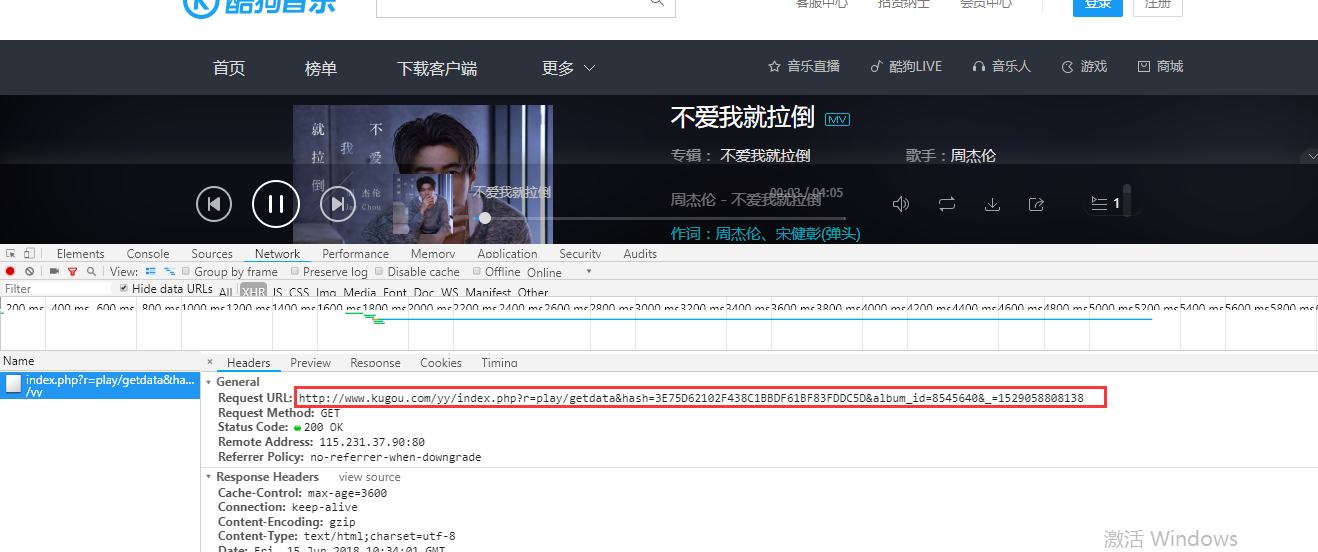
3.酷狗播放歌曲的实现方式,是通过ajax请求获取的服务器资源,点击播放某歌曲,播放页面打开F12,切至netWork,观察Request URL请求,如下 例如http://www.kugou.com/yy/index.php?r=play/getdata&hash=89AB193EC33E2AE6AF04BD408F8F1083&album_id=962593&_=1529057140131
经过测试发现(建议使用截包工具截获url请求),只需要(get请求)http://www.kugou.com/yy/index.php?r=play/getdata&hash=89AB193EC33E2AE6AF04BD408F8F1083
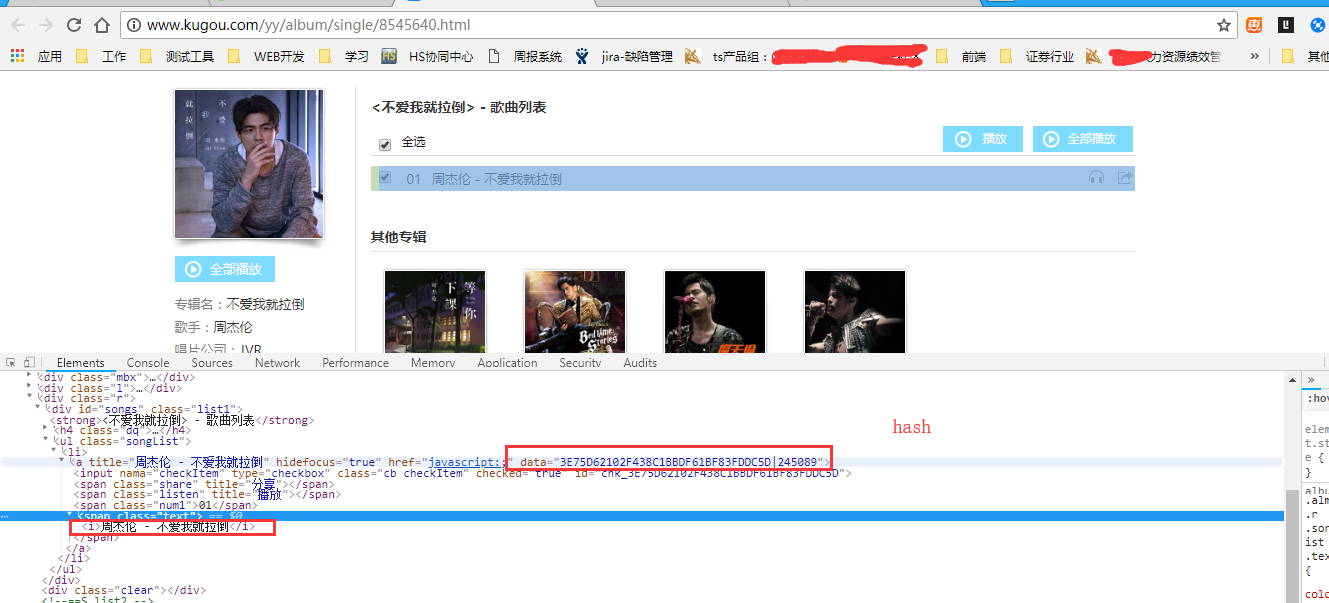
而每首歌有一个单独的hash,只要找到每首歌的hash,即可获取每首歌的ajax请求url,而这个hash存在于专辑页面中,bs4提取专辑内所有歌曲的hash.
4.可以发现其ajax请求的response信息中存在该歌曲的MP3资源url,那么通过urllib.request.urlretrieve()函数即可保存该歌曲.
图例过程:

# -*- coding: utf-8 -*- # @Time : 2018/6/8 # @Author : Torre # @Email : klyweiwei@163.com # 免费下载酷狗音乐:通过歌手singerId即可以专辑下载歌手的所有歌曲。 # 具体过程:1.酷狗首页搜索歌手,进入歌手主页,获取url中的singId,例如朴树主页:http://www.kugou.com/singer/3520.html,其中3520即为singId; # 2.根据歌手singerId可以获得歌手的所有专辑的albumId,例如 这是专辑的页面,http://www.kugou.com/yy/album/single/962593.html,其中962593为albumId # 3.酷狗播放歌曲的实现方式,是通过ajax请求获取的服务器资源,点击播放某歌曲,播放页面打开F12,切至netWork,观察Request URL请求,如下 # 例如http://www.kugou.com/yy/index.php?r=play/getdata&hash=89AB193EC33E2AE6AF04BD408F8F1083&album_id=962593&_=1529057140131 # 经过测试发现(建议使用截包工具截获url请求),只需要(get请求)http://www.kugou.com/yy/index.php?r=play/getdata&hash=89AB193EC33E2AE6AF04BD408F8F1083 # 而每首歌有一个单独的hash,只要找到每首歌的hash,即可获取每首歌的ajax请求url,而这个hash存在于专辑页面中,bs4提取专辑内所有歌曲的hash. # 4.可以发现其ajax请求的response信息中存在该歌曲的MP3资源url,那么通过urllib.request.urlretrieve()函数即可保存该歌曲. import os import urllib.request import requests import re import json import getSoup # from urllib.request import urlretrieve headers = { 'origin': "http://www.kugou.com", 'x-devtools-emulate-network-conditions-client-id': "97C9BAA42BE5A8449EC4283F764B4D9E", 'user-agent': "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36", 'content-type': "application/x-www-form-urlencoded", 'accept': "*/*", 'referer': "http://www.kugou.com/singer/3520.html", 'accept-encoding': "gzip, deflate", 'accept-language': "zh-CN,zh;q=0.9", 'cookie': "kg_mid=88665d81b7959ab3787c4976831a30f9; Hm_lvt_aedee6983d4cfc62f509129360d6bb3d=1528705681; Hm_lpvt_aedee6983d4cfc62f509129360d6bb3d=1528707581", 'cache-control': "no-cache", 'postman-token': "c717ef07-2b91-06f1-1d22-abcb47b0bce2" } # 获取歌手的所有album信息 def getAlbumid(singerID): # 获取歌单albumid url = "http://www.kugou.com/yy/" querystring = {"r": "singer/album", "sid": singerID} # headers = { # 'origin': "http://www.kugou.com", # 'x-devtools-emulate-network-conditions-client-id': "97C9BAA42BE5A8449EC4283F764B4D9E", # 'user-agent': "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36", # 'content-type': "application/x-www-form-urlencoded", # 'accept': "*/*", # 'referer': "http://www.kugou.com/singer/3520.html", # 'accept-encoding': "gzip, deflate", # 'accept-language': "zh-CN,zh;q=0.9", # 'cookie': "kg_mid=88665d81b7959ab3787c4976831a30f9; Hm_lvt_aedee6983d4cfc62f509129360d6bb3d=1528705681; Hm_lpvt_aedee6983d4cfc62f509129360d6bb3d=1528707581", # 'cache-control': "no-cache", # 'postman-token': "c717ef07-2b91-06f1-1d22-abcb47b0bce2" # } response = requests.request("POST", url, headers=headers, params=querystring) res = response.text # print(type(res)) jsonRes = json.loads(res) loadAlbumids = [] # 保存albumids到list loadAlbumname = [] albumids = jsonRes['data'] for albumid in albumids: albumid = albumid['albumid'] # print(albumid) loadAlbumids.append(albumid) # print(albumid) for albumname in albumids: albumname = albumname['albumname'] albumname = albumname[0] loadAlbumname.append(albumname) # print(albumname) return loadAlbumname, loadAlbumids # getAlbumid(2303) # 获取该专辑内的所有歌曲的hash def getMp3Info(albumid): url = 'http://www.kugou.com/yy/album/single/'+str(albumid)+'.html' soup = getSoup.getSoup(url) hashs = soup.select('.songList a') loadMp3Hash = [] for hashss in hashs: hash = hashss.get('data') # 通过spilt('|')分割字符串,获取hash mp3Hash = hash.split('|')[0] # print(hash.split('|')[0]) # hash = hash.spilt('|') loadMp3Hash.append(mp3Hash) # print(mp3Hash) return loadMp3Hash # mp3 = getMp3Info(1645030) # for i in range(len(mp3)): # print(mp3[i]) # 通过ajax请求获取歌曲的PlayerUrl def getPlayUrl(hash, albumId): url = "http://www.kugou.com/yy/index.php" querystring = {"r": "play/getdata", "hash": hash, "album_id": albumId} response = requests.request("GET", url, headers=headers, params=querystring) response.raise_for_status() res = response.text # print(type(res)) jsonRes = json.loads(res) playUrl = jsonRes['data'] audioName = playUrl['audio_name'] playUrl = playUrl['play_url'] music = (audioName, playUrl) print('-'.join(music)) return audioName, playUrl # @test # mp3 = getMp3Info(1645030) # for i in range(len(mp3)): # print(mp3[i]) # getPlayUrl(mp3[i], '1645030') # 文件/文件夹的创建是不允许一些非法字符存在的,此函数过滤掉非法字符 def validateName(name): rstr = r"[\/\\\:\*\?\"\<\>\|]" # '/ \ : * ? " < > |' new_name = re.sub(rstr, "", name) return new_name # 进度信息 def cbk(a,b,c): per=100.0*a*b/c if per>100: per=100 print('%.2f%%' % per) # # 保存为MP3, 保存到特定文件夹下面:文件夹以专辑名字命名; 注意,在代码的根目录下创建mp3文件夹 def saveAudio(url, album, filename): filepath = os.getcwd()+'\\mp3\\'+album if os.path.exists(filepath): mp3 = os.path.join(filepath + '\\', '' + filename + '.mp3') if url == '': print('the url is NUll, pass') else: urllib.request.urlretrieve(url, mp3, cbk) else: os.makedirs(filepath) mp3 = os.path.join(filepath + '\\', '' + filename + '.mp3') if url == '': print('the url is NUll, pass') else: urllib.request.urlretrieve(url, mp3, cbk) # 运行主程序, 只需要填入 歌手ID即可(http://www.kugou.com/yy/html/singer.html, # 点击任一歌手即可获得其ID), 可以自动下载其所有专辑 : 比如3043 代表 许巍; 61874代表Sophia zelmani;朴树2303;34450 Taylor Swift def downloadMp3(singerId): albumname, albumids = getAlbumid(singerId) # length = len(albumids) # print(albumids) for i in range(len(albumids)): hashs = getMp3Info(albumids[i]) for ii in range(len(hashs)): audioName, playUrl = getPlayUrl(hashs[ii], albumids[i]) saveAudio(playUrl, validateName(albumname[i]), validateName(audioName)) # 调用函数 ,下载歌曲 downloadMp3(34450)
(2).爬取2014年世界杯各个球员的参赛数据。
1.数据库连接以及sql语句格式化
数据库连接及其操作,我单独封装成一个类ConnectDatabase;
1.读取本地的配置文件(Json文件:数据库的连接地址、账号、密码、数据库名等信息)
2.主要函数有数据库连接、获取数据库的所有表、执行sql并提交、关闭数据库连接等
2.数据爬取并存储
1.通过requests.get()获取response对象;
2.bs4.BeautifulSoup()获取bs4对象;
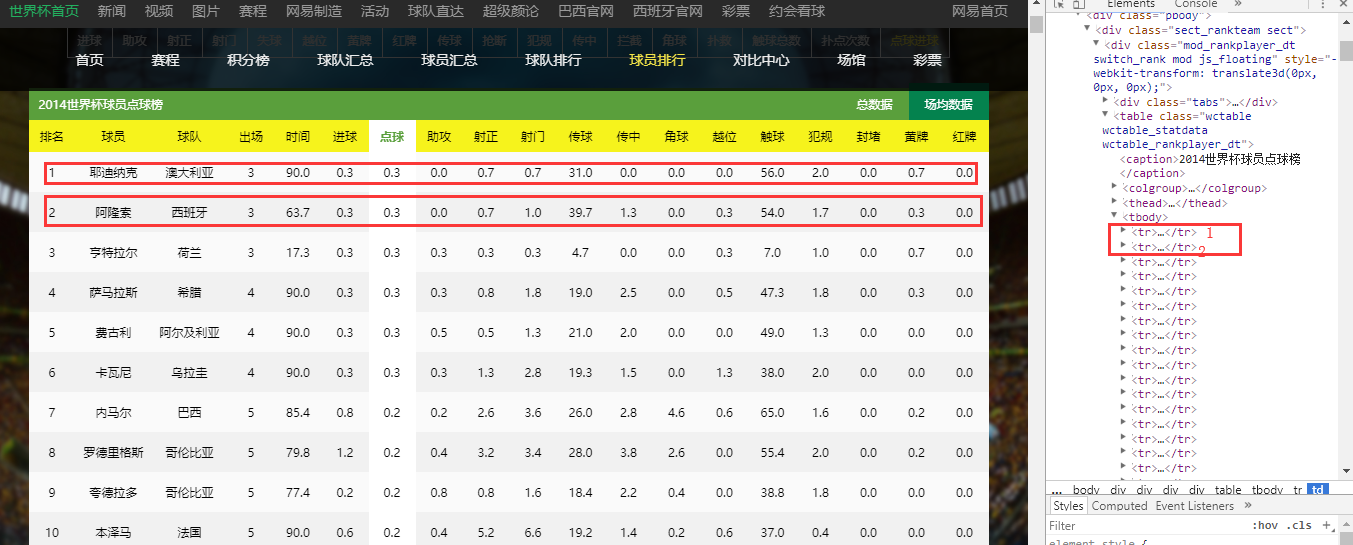
3.通过select()方法,获取bs4对象的表格数据并存储到list中
4.执行sql并提交数据
-- 建表语句 CREATE TABLE `playertechsum` ( `id` int(255) NOT NULL AUTO_INCREMENT, `player` varchar(20) DEFAULT '' COMMENT '球员', `team` varchar(20) DEFAULT NULL COMMENT '球队', `games` int(255) DEFAULT NULL COMMENT '出场', `minsPlayed` int(255) DEFAULT NULL COMMENT '出场时间', `goals` int(10) DEFAULT NULL COMMENT '进球数', `attPenGoal` int(10) DEFAULT NULL COMMENT '点球', `goalAssist` int(10) DEFAULT NULL COMMENT '助攻', `ontargetScoringAtt` int(20) DEFAULT NULL COMMENT '射正', `totalScoringAtt` int(20) DEFAULT NULL COMMENT '射门', `totalPass` int(10) DEFAULT NULL COMMENT '传球', `totalCross` int(10) DEFAULT NULL COMMENT '传中', `wonCorners` int(10) DEFAULT NULL COMMENT '角球', `totalOffside` int(10) DEFAULT NULL COMMENT '越位', `touchBall` int(10) DEFAULT NULL COMMENT '触球', `fouls` int(10) DEFAULT NULL COMMENT '犯规', `outfielderBlock` int(10) DEFAULT NULL COMMENT '封堵', `yellowCard` int(10) DEFAULT NULL COMMENT '黄牌', `redCard` int(10) DEFAULT NULL COMMENT '红牌', PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- 数据库连接以及操作函数 # -*- coding: utf-8 -*- # @Time : 2018/5/24 20:02 # @Author : Torre # @Email : klyweiwei@163.com # Description :connect to database, return cursor and conn import json import pymysql import random import string import os import logging class ConnectDatabase: # def __init__(self, cur): # self.cur = cur # def get_conf(self, file='databases_conf.json'):读取本地json文件 def get_conf(self, file): with open(file, "r", encoding="utf-8") as f: conf = json.load(f) return conf # 数据库连接 def connect_db(self, host, user, password, db, port): conn = pymysql.connect(host, user, password, db, port, charset="utf8") # 最好加上utf-8 cur = conn.cursor() return conn, cur # 获取列 def get_cols(self, table, cur): sql = 'desc ' + str(table) + '' cur.execute(sql) res = cur.fetchall() return res # 执行sql,获取查询结果 def get_res(self, cur, sql): cur.execute(sql) res = cur.fetchall() return res # 执行并提交 def get_fetch(self, conn, cur, sql): cur.execute(sql) conn.commit() # 关闭数据库连接 def disconnect_db(self, conn, cur): cur.close() conn.close()
-- 获取bs4对象 #!/usr/bin/env python # -*- coding: utf-8 -*- # @Author : Torre Yang Edit with Python3.6 # @Email : klyweiwei@163.com # @Time : 2018/6/5 16:19 import requests from bs4 import BeautifulSoup as bs def getSoup(url): response = requests.get(url) response.raise_for_status() res = response.content soup = bs(res, 'html.parser') return soup
-- 爬取的数据插入到mariadb
# -*- coding: utf-8 -*- # @Time : 2018/6/18 18:59 # @Author : Torre # @Email : klyweiwei@163.com import getSoup import connect_dataBase import os import re from bs4 import BeautifulSoup as bs # db连接 connectDB = connect_dataBase.ConnectDatabase() get_conf = connectDB.get_conf('databases_conf.json') conn, cur = connectDB.connect_db(get_conf["brazilCup"]["host"], get_conf["brazilCup"]["user"], get_conf["brazilCup"]["password"], get_conf["brazilCup"]["database"], get_conf["brazilCup"]["port"]) url = 'http://worldcup.2014.163.com/playerrank/avg/attPenGoal/' soup = getSoup.getSoup(url) trs = soup.select('tbody tr') # print(tds) length = len(trs) # print(length) players = [] for tr in trs: # print(row) player = [] # print(len(tr)) for td in tr: tds = '\''+str(td.string.strip())+'\'' # print(tds) # player.append(str(td.string.strip())) player.append(tds) if "''" in player: player.remove("''") # print(player) # print(tuple(player)) # 球员排行榜 sql = 'insert into playertechsum(id,player,team,games,minsPlayed,goals,attPenGoal,goalAssist,ontargetScoringAtt,totalScoringAtt,totalPass,totalCross,wonCorners,totalOffside,touchBall,fouls,outfielderBlock,yellowCard,redCard) values('+\ ','.join(player)+')' connectDB.get_fetch(conn, cur, sql)
四、结后语
当然,想深入学习爬虫,最好还是要学习一个爬虫框架。常见python爬虫框架参考如下:
(1)Scrapy:很强大的爬虫框架,可以满足简单的页面爬取(比如可以明确获知url pattern的情况)。用这个框架可以轻松爬下来如亚马逊商品信息之类的数据。但是对于稍微复杂一点的页面,如weibo的页面信息,这个框架就满足不了需求了。
(2)Crawley: 高速爬取对应网站的内容,支持关系和非关系数据库,数据可以导出为JSON、XML等
(3)Portia:可视化爬取网页内容
(4)newspaper:提取新闻、文章以及内容分析
(5)python-goose:java写的文章提取工具
(6)mechanize:优点:可以加载JS。缺点:文档严重缺失。不过通过官方的example以及人肉尝试的方法,还是勉强能用的。
附件:资料下载地址 链接:https://pan.baidu.com/s/179RtOxk4CsnjqjChW0nljw 密码:lczh


 浙公网安备 33010602011771号
浙公网安备 33010602011771号