20155117王震宇 2016-2017-2 《Java程序设计》第八周学习总结
教材学习内容总结
正则表达式
- 正则表达式是记录文本规则的代码
- 元字符
^:^会匹配行或者字符串的起始位置,有时还会匹配整个文档的起始位置。$:$会匹配行或字符串的结尾。\b:不会消耗任何字符只匹配一个位置,常用于匹配单词边界 如 我想从字符串中"This is ..."匹配单独的单词 "is" 正则就要写成\bis\b\b不会匹配is 两边的字符,但它会识别is 两边是否为单词的边界
\d匹配数字
例如要匹配一个固定格式的电话号码以0开头前4位后7位,如0000-0000000 正则:^0\d\d\d-\d\d\d\d\d\d\d$当然还有更简便的写法。\w:匹配字母,数字,下划线
例如我要匹配"a2345BCD__TTz" 正则:\w+\s:匹配空格
例如字符 "a b c" 正则:\w\s\w\s\w一个字符后跟一个空格,如有字符间有多个空格直接把\s写成\s+让空格重复
-.:匹配除了换行符以外的任何字符
这个算是\w的加强版了\w不能匹配 空格 如果把字符串加上空格用\w就受限了,看下用 "."是如何匹配字符"a23 4 5 B C D__TTz" 正则:.+[abc]: 字符组 匹配包含括号内元素的字符
这个比较简单了只匹配括号内存在的字符,还可以写成[a-z]匹配a至z的所以字母就等于可以用来控制只能输入英文了。- 反义,将写法改成大写,意思与原来相反
\W匹配任意不是字母,数字,下划线 的字符\S匹配任意不是空白符的字符\D匹配任意非数字的字符\B匹配不是单词开头或结束的位置[^abc]匹配除了abc以外的任意字符- 贪婪、懒惰、占有
- 贪婪(贪心) 如
*字符 贪婪量词会首先匹配整个字符串,尝试匹配时,它会选定尽可能多的内容,如果 失败则回退一个字符,然后再次尝试回退的过程就叫做回溯,它会每次回退一个字符,直到找到匹配的内容或者没有字符可以回退。相比下面两种贪婪量词对资源的消耗是最大的。- 懒惰(勉强) 如
?懒惰量词使用另一种方式匹配,它从目标的起始位置开始尝试匹配,每次检查一个字符,并寻找它要匹配的内容,如此循环直到字符结尾处。 - 占有 如
+占有量词会覆盖事个目标字符串,然后尝试寻找匹配内容 ,但它只尝试一次,不会回溯
- 懒惰(勉强) 如
*(贪婪) 重复零次或更多
例如"aaaaaaaa" 匹配字符串中所有的a 正则:a*会出到所有的字符"a"+(懒惰) 重复一次或更多次
例如"aaaaaaaa" 匹配字符串中所有的a 正则:a+会取到字符中所有的a字符,a+与a*不同在于"+"至少是一次而*可以是0次。?(占有) 重复零次或一次
例如"aaaaaaaa" 匹配字符串中的a 正则 :a?只会匹配一次,也就是结果只是单个字符a{n}重复n次
例如从"aaaaaaaa" 匹配字符串的a 并重复3次 正则:a{3}结果就是取到3个a字符 "aaa";{n,m}重复n到m次
例如正则 "a{3,4}" 将a重复匹配3次或者4次 所以供匹配的字符可以是三个"aaa"也可以是四个"aaaa" 正则都可以匹配到{n,}重复n次或更多次
与{n,m}不同之处就在于匹配的次数将没有上限,但至少要重复n次 如 正则a{3,}a至少要重复3次
刚才的0000-0000000的正则形式可以改为0\d+−\d7。
加上限定可以进一步改为^0\d{2,3}-\d{7}。
教材学习中的问题和解决过程
代码调试中的问题和解决过程
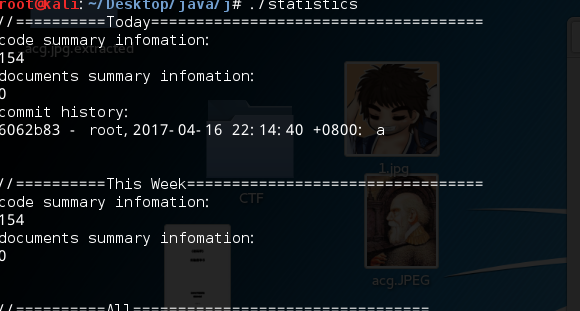
代码托管
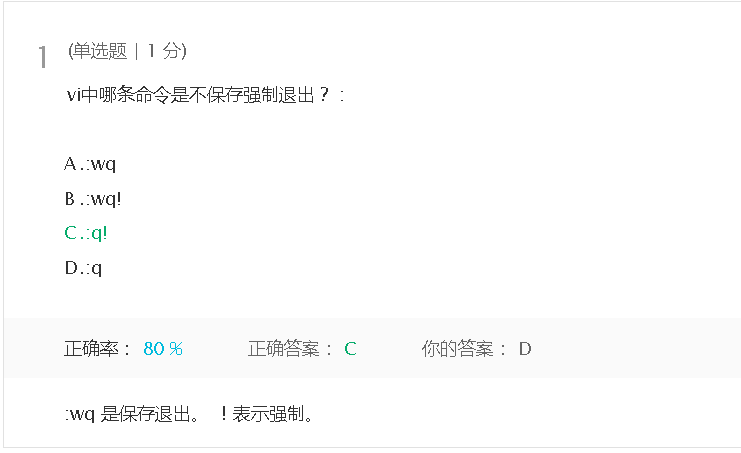
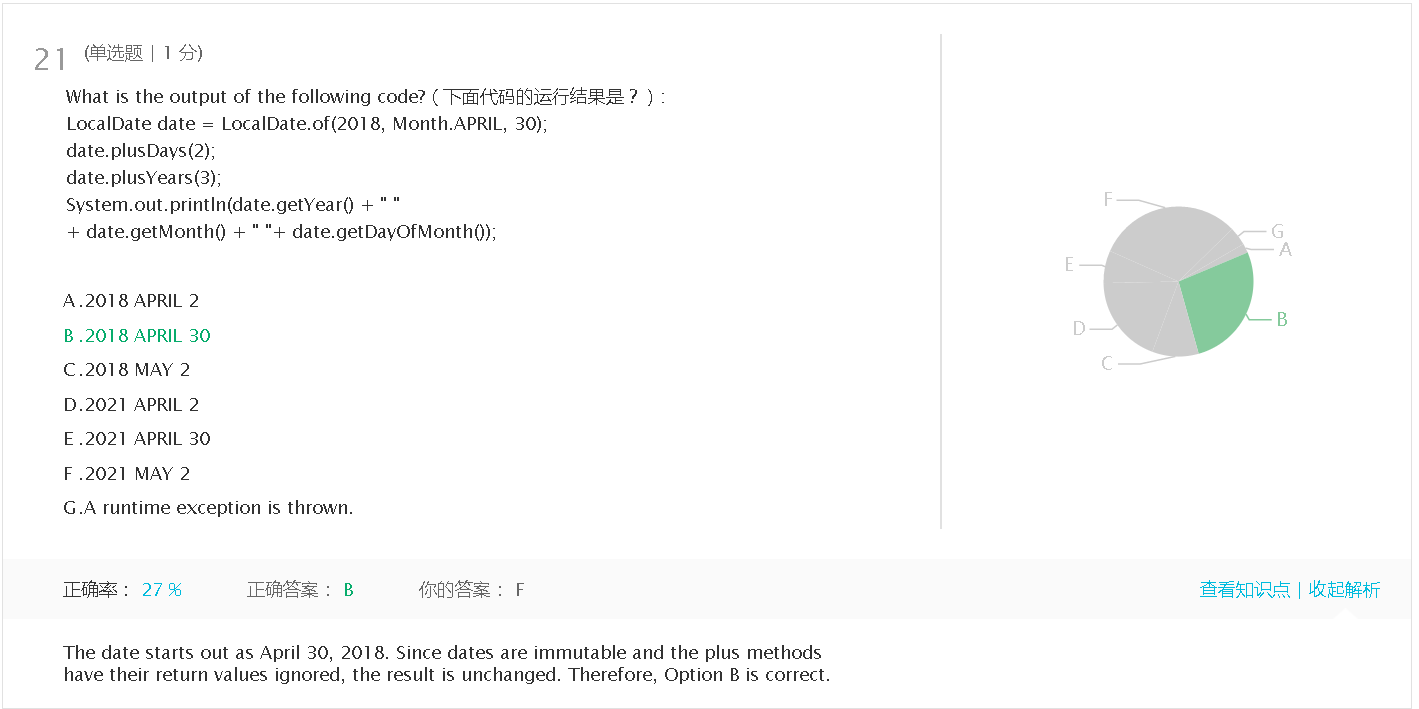
上周考试错题总结





结对及互评
其他(感悟、思考等,可选)
正则表达式匹配工具
学习进度条
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
|---|---|---|---|---|
| 目标 | 5000行 | 30篇 | 400小时 | |
| 第一周 | 0/0 | 2/2 | 20/20 | |
| 第二周 | 251/251 | 1/5 | 18/38 | |
| 第三周 | 651/902 | 1/6 | 10/48 | |
| 第四周 | 300/1400 | 1/7 | 10/58 | |
| 第五周 | 696/2196 | 1/8 | 10/68 | |
| 第六周 | 722/2918 | 1/9 | 10/78 | |
| 第七周 | 172/3090 | 1/10 | 10/88 | |
| 第八周 | 152/3242 | 1/11 | 10/98 |

