[svc]linux正则及grep常用手法
正则测试
可以用sublime等工具快速的检测正则是否合适
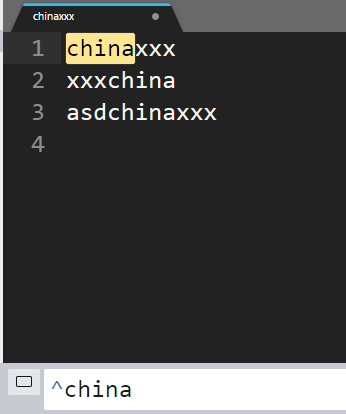
china : 匹配此行中任意位置有china字符的行
^china : 匹配此以china开关的行
china$ : 匹配以china结尾的行
^china$ : 匹配仅有china五个字符的行
[Cc]hina : 匹配含有China或china的行
Ch.na : 匹配包含Ch两字母并且其后紧跟一个任意字符之后又有na两个字符的行
Ch.*na : 匹配一行中含Ch字符,并且其后跟0个或者多个字符,再继续跟na两字符
扩展正则
**口诀: 温家星**
? : 匹配前面正则表达式的零个或一个扩展
+ : 匹配前面正则表达式的一个或多个扩展
* : 前面出现0个或多个
{m,n} : 前面出现m,n
| : 匹配|符号前或后的正则表达式
() : 匹配方括号括起来的正则表达式群,如g(la|oo)d
[a-z] : 序列,如[a-Z] [0-9] [Cc]
几个例子: 1.+代表出现1次或多次
[a-z]+
[a-c]d+
d[a-c]+
(ab)+
(d[a-c]+)+
2.()的例子
[root@n1 test]# egrep 'g(la|oo)d' test.md
good
glad
来自grep的man手册
Repetition
A regular expression may be followed by one of several repetition operators:
? The preceding item is optional and matched at most once.
* The preceding item will be matched zero or more times.
+ The preceding item will be matched one or more times.
{n} The preceding item is matched exactly n times.
{n,} The preceding item is matched n or more times.
{,m} The preceding item is matched at most m times. This is a GNU extension.
{n,m} The preceding item is matched at least n times, but not more than m times.
grep参数
-i, --ignore-case 不区分大小写
-v, --invert-match 排除
-c, --count 统计url出现次数
-E --extended-regexp 等价于egrep, grep -E 'a|b'
-n, --line-number
-r, --recursive 按照目录
-o, --only-matching 只显示匹配行中匹配正则表达式的那部分
-C -A -B
grep -nr
grep -oP
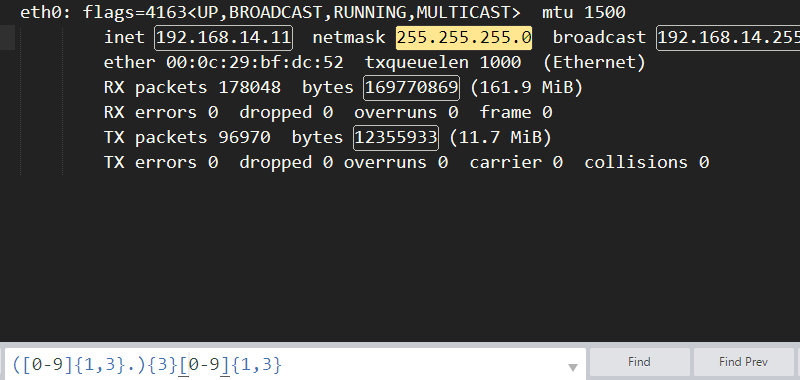
过滤ip

192.168.100.100
ifconfig|grep -oP "([0-9]{1,3}\.){3}[0-9]{1,3}"
过滤邮箱

cat >>tmp.txt<<EOF
iher-_@qq.com
hello
EOF
cat tmp.txt|grep -oP "[a-zA-Z0-9_-]+@[a-zA-Z0-9_-]+(\.[a-zA-Z]+)+"
统计baidu关键字的url在这个大文件中出现的次数
$ cat >file.txt<<EOF
wtmp begins Mon Feb 24 14:26:08 2014
192.168.0.1
162.12.0.123
"123"
123""123
njuhwc@163.com
njuhwc@gmil.com 123
www.baidu.com
tieba.baidu.com
www.google.com
www.baidu.com/search/index
EOF
grep -cn ".*baidu.com.*" file.txt
3
过滤jay的,非混音轨的mp3的内容
[root@lanny ~]# cat jay.txt
Jay_01_remix.mp3
jAy_02_rEmix.mp3
jaY_03_Remix.mp3
jay_05_ori.mp3
lanny.mp4
mo.3gp
lanny.mp3
思路: 先过滤mp3的内容,然后再mp3中找出jay的,然后再jay中找出非remix的内容
[root@lanny ~]# grep -E ".mp3" jay.txt|grep -i "jay"|grep -vi "remix"
jay_05_ori.mp3

