
《JavaScript高级程序设计》Chapter 12 DOM2和DOM3
小记
在DOM1的基础上进行扩展,引入更多的交互,并处理更高级的XML。分为许多应用的模块,对DOM2和DOM3的功能等进行描述,内容包括:DOM2级核心、DOM2级视图(view)、DOM2级事件(13章讨论)、DOM2级样式、DOM2级遍历和范围、DOM2级HTML、DOM3级增加了XPath模块和加载与保存模块,在Chapter18中讨论。本章讨论:
- DOM变化:命名空间(XHML和XHL,与HTML没有多大关系)、Document的编程式操作。go
- DOM样式的变化:对于HTML来说,这个比较重要。style属性、getComputedStyle()/currentStyle、document.stylesheets以及相关IE接口 go
- 遍历(深度优先):NodeIterator(以一个节点的步幅移动)、TreeWalker go
- 范围:可以选择文档的某个部分,将其交给文档片段,继而对其进行其他操作。IE中可以操作相应文本范围。go
DOM变化(讨论DOM2级核心、HTML和视图模块以及部分DOM3)
- 检测是否支持DOM核心、HTML和视图模块
var supportsDOM2Core = document.implementation.hasFeatrue("Core","2.0"); var supportsDOM3Core = document.implementation.hasFeatrue("Core", "3.0); var supportsDOM2HTML = document.implementation.hasFeatrue("HTML","3.0); var supportsDOM2Views = document.implementation.hasFeatrue("Views", "2.0"); var supportsDOM2XML = document.implementation.hasFeatrue("XML", "2.0);
- 针对命名空间的变化(主要是XML的命名空间,以XHTML为例)
- 命名空间相关概念的了解:prefix、localName、tagName(nodeName)、namespaceURI。同样可以对属性指定命名空间
- Node类型的变化
- 属性:localName、namespaceURI、prefix
- 方法(DOM3):isDefaultNamespace(namespaceURI)/lookupNamespaceURI(prefix)/lookupPrefix(namespaceURI)
- Document类型的变化
- 方法:createElementNS(namespaceURI, tagName)/createAttributeNS(namespaceURI, attributeName)/getElementsByTagNameNS(namespaceURI, tagName)
- Element类型的变化
- 对特性进行操作的方法(DOM2):getAttributeNS(namespaceURI, localName)/getAttributeNodeNS(namespaceURI,localName)/getElementsByTagNameNS(namespaceURI, tagName)/hasAttributeNS(namespaceURI, localName)/removeAttributeNS(namespaceURI, localName)/setAttributeNS(namespaceURI, qualifiedName, value)/setAttributeNoadeNS(attNode)
- NamedNodeMap类型的变化(特性的相关操作,较少使用)
- getNamedItemNS(namespaceURI, localName)/removeNamedItemNS(namesaceURI, localName)/setNamedItemNS(node)
- 其他的变化(非命名空间方面的)
- DocumentType类型:publicId、systemId、internalSubset
- Document类型:importNode()方法
- 意义:每个节点具有ownerDocument属性,表示其文档归属。如果单纯的在不同文档间进行复制,那么由于ownerDocument属性的问题,在使用appendChild()的时候就会产生问题。
- importNode(oldNode, true)会产生原节点的副本并可加入另外一个文档中。注意到第二个参数若为true,则连同其子节点一起进行复制。(常用于XML文档)
- DOM2级视图:defaultView属性,保存指针,指向给定文档的窗口或者框架。IE用parentWindow代替:
var parentWindow = document.defaultView || document.parentWindow; - DOM2级核心:document.implementation的createDocumentType()和createDocument()方法,二者通常结合使用,将前者创造的属性赋给后者的第三个参数。以创建文档。
- DOM2级HTML:document.implementation.createHTMLDocument()方法,创建一个包含<html>, <title>, <body>元素的html文档,其中可以通过参数指定title。
- Node类型的变化
- isSupported()方法,类似于hasFeature()方法,但同样有不足,注意和能力检测一起使用。
- DOM3级辅助比较节点:
isSameNode()/isEqualNode()。前者强调引用的节点都应该相同,后者强调节点的属性等相等。
setUserData("name", "Nicholas", function(){})为节点添加额外的数据。第三个参数的函数可以在节点进行相关操作(复制、导入、删除、重命名)的时候执行特定的操作。
- 框架的变化(frame)
- HTMLFrameElement/HTMLIFrameElement表示框架和内嵌框架
- contentDocument属性:指针,指向表示框架内容的文档对象,IE用contentWindow代替:
var iframe = getElementById("myIframe");
var iframeDoc = iframe.contentDocument || iframe.contentWindow.document; - 注意跨域安全策略的限制和影响。
样式(DOM的样式模块)
- 访问样式的方式:样式表(<style>和<link>),元素的style属性
var supportsDom2CSS = document.implementation.hasFeature("CSS","2.0"); var supportsDOM2CSS2 = document.implementation.hasFeatrue("CSS2", "2.0");
- 访问元素的样式:通过style属性
- 注意对于用短划线进行分隔的属性名需要在JS中转换为驼峰式进行访问,且注意某些属性名如float本身为JS的保留字,需要转换为cssFloat或者syleFloat来进行访问。
- 最好带上度量单位,标准模式和混杂模式对于不带度量单位的处理不一样。
- 通过element.style.width格式进行访问。
- 注意到用style特性设置的属性值的级别较高。
- 注意不同浏览器对默认值的处理不一样,所以若想要得到统一的效果,就自己进行设置。
- DOM2规定的样式相关的方法或者属性:
![]()

-
-
- length一般和item()可以互换使用,此时将style看做一个对象数组。
- getPropertyValue()方法获得属性值,而getPropertyCSSValue()方法获取属性值以及值的类型。
-
- 计算的样式:经历了重叠的样式,可以获得样式表中的样式。
- document.defaultView.getComputedStyle()方法,参数为要取得计算样式的元素以及伪元素信息(后者若没有写成null)
- IE用currentStyle属性代替,是CSSStyleDeclaration的实例。
- 计算样式是只读的。
- 操作样式表(统一处理style元素和link元素)
- CSSStyleSheet对象:继承自stylesheet。统一处理HTMLLinkElement和HTMLStyleElement,但后两者可以修改特性,前者只是只读。
- var supportsDOM2StyleSheets = document.implementation.hasFeatrue("Stylesheets","2.0);
- 继承而来的属性:
![]()

-
- 除此之外的属性和方法(处理rules)
![]()
- 除此之外的属性和方法(处理rules)

-
- document.stylesheets在不同浏览器中返回的样式表有不同。IE和Opera还会返回rel被设为“alternate stylesheet”的样式表。
- 可以直接通过link或者style元素取得CSSStyleSheet,DOM规定了个sheet,IE则用stylesheet(之前提到过document.stylesheets)
function getStylesheet(element){
return element.sheet || element.stylesheet
} - CSS规则:CSSStyleRule对象,包含了常用的属性cssText,selectorText和style等。获取规则:document.stylesheets[0].cssRules || document.stylesheets[0].rules;
- 创建规则:insertRules()方法,IE中用addRule()代替。若需要加入的规则较多,不妨用之前提到过的动态引入样式表的方法。
- 删除规则:deletRules()方法,IE用removeRule()方法。
- 元素大小(所占的空间)
- 偏移量:offsetHeight/offsetWidth(以像素计,包括内容区,滚动条,上下/左右边框。不包含外边距),offsetLeft/offsetTop(左/上外边框至包含元素的左/上内边框之间的像素值)
- 注意offsetParent属性不一定等于parentNode属性。例如<td>的offsetParent指向<table>,因为后者是DOM层次中距<td>最近的具有大小的元素。
- 页面上的偏移量:该元素的offsetLeft和其外容器的offsetLeft相加,一直加到根元素节点。
- 偏移量属性只读,且避免多次重复使用影响效率。
- 客户区大小(元素内容及其内边距所占空间大小):clientWidth/clientHeight:
![]()
- 偏移量:offsetHeight/offsetWidth(以像素计,包括内容区,滚动条,上下/左右边框。不包含外边距),offsetLeft/offsetTop(左/上外边框至包含元素的左/上内边框之间的像素值)

-
- 滚动大小:scrollHeight/scrollWidth, scrollLeft/scrollTop,如图:
![]()
- 滚动大小:scrollHeight/scrollWidth, scrollLeft/scrollTop,如图:

-
- 确定文档总高度的时候,必须取得scrollWidth/clientWidth, scrollHeight/clientHeight中的最大值。
- 之前也提到过,对于在document.body还是document.documentElement上应用上述属性和方法需要具体区分。
- 确定元素大小:
- 元素在页面中相对于视口的位置:通过getBoundingClientRect()方法的到返回的left、top、right、bottom
- 然而起始点offset不同,且可能没有该方法,所以需要自己构造这个方法:pdf P344-345
遍历(NodeIterator和TreeWalker)
var supportsTraversals = document.implementation.hasFeature("Traversal","2.0"); var supportsNodeIterator = (typeof document.createNodeIterator == 'function'); var supportsTreeWalker = (typeof document.createTreeWalker == 'function');
- 深度优先的遍历:两个方向-向上或者向下。先往深处探寻,再遍历下一个深度。
- NodeIterator(以一个节点为步幅的遍历)
- document.createNodeIterator(root, whatToShow, filter, entityReferenceExpansion)
- whatToShow:位掩码,想要遍历的节点。
- filter:构建一个过滤器NodeFilter对象或者函数,如果是对象,应该有acceptNode()方法,如下面例子,只遍历元素<p>。若不指定过滤器,则为null:
var filter = { acceptNode: function(node){ return node.tagName.toLowerCase() == "p"? NodeFilter.FILTER_ACCEPT: NodeFilter.FILTER_SKIP; } };
- 方法:nextNode()和previousNode()。顾名思义。
- TreeWalker(高级版本,功能更加强大的NodeIterator)
- document.createTreeWalker(root, whatToShow, filter, entityReferenceExpansion)
- 与NodeIterator相比,filter处的方法或者函数可以多返回一个值:NodeFilter.FILTER_REJECT(不会遍历不符合条件的节点并其子节点);而NodeFilter.FILTER_SKIP只是跳过不符合条件的节点而已。
- 方法:nextNode()/previousNode(), parentNode(),firstChild()/lastChild(),nextSibling()/previousSibling().
- 属性:currentNode
- 通过上述的方法和属性,TreeWalker可以试想在节点树上任意方向甚至步幅的移动。需要注意的是如下例中的walker指针本身是动态变化的,这正是“遍历”的体现。
-
-
- html代码
<div id = "div1"> <p><b>Hello</b> world!</p> <ul> <li>List item 1</li> <li>List item 2</li> <li>List item 3</li> </ul> </div>
- JS代码
var div = document.getElementById("div1"); var walker = document.createTreeWalker(div, NodeFilter_SHOW_ELEMENT, null, false); walker.firstChild(); //转到<p> walker.nextSibling();//转到<ul> waler.firstChild(); //转到第一个<li>
- html代码
-
范围(选择一整片区域,然后对其进行操作)
var supportsRange = document.implementation.hasFeature("Range","2.0"); var alsoSupportsRange = (typeof document.createRange == "function");
- 创建范围:createRange()创建实例,selectNode()/selectNodeContents()具体进行范围选择(前者选择整个节点,后者选择子节点),startContainer/startOffset, endContainer/endOffset, commonAncestorContainer属性动态刷新。以下述代码为例:
- html代码
<div id = "div1"> <p><b>Hello</b> world!</p> <ul> <li>List item 1</li> <li>List item 2</li> <li>List item 3</li> </ul> </div>
- JS代码
var range1 = document.createRange(); var range2 = document.createRange(); var p1 = document.getElementById("p1"); range1.selectNode(p1); range2.selectNodeContents(p1);
- 分析:
![]()
Range1使用selectNode()进行范围选择,则其startContainer/endContainer/commonAncestorContainer都是元素<p>的父节点document.body(commonAncestorContainer应该满足:共同的、最深的)。startOffset等于给定节点<p>在父元素childNodes中的位置索引1(考虑到DOM将前面的空格视作0)。endOffset等于startOffset+1(因为只选择了一个节点)。
Range1使用selectNodeContents()进行选择,顾名思义其startContainer/endContainer/commonAncerstorContainer都是传入节点<p>。startOffset是0,endOffset显然是p的子元素长度,此处为2。
- 还有一些方法可以进一步控制节点是否包含在范围中:setStartBefore()/setStartAfter()/setEndBefore()/setEndAfter()顾名思义。
- html代码
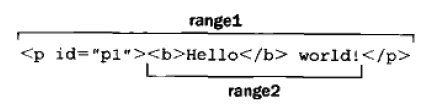
- 实现更加复杂或者说精细的选择:
- setStart(startContainer,startOffset)/setEnd(endContainer,endOffset)
- 作用:模拟selectNode()或者selectNodeContents()、选择(文本)节点的一部分
- 操作DOM范围中的内容:
- 重要的知识:内部会为范围创建一个文档片段(Document Fragment),且此片段具有完整的合理的构造,以待进一步使用。
- 删除范围:deleteContents()
- “抽出”范围:extractContents()。除了删除之外,会返回这个片段。
- 复制范围对象:cloneContents()创建一个范围对象副本。
- 插入范围中的内容:insertNode():注意如果没有经历上述的操作,后台不会创建额外的标签或者结构。
- 环绕插入的内容:surroundContents()
- 折叠DOM范围:collapse()。折叠到起点true或者终点false,collapsed可以判断有否折叠。
- 比较DOM范围:compareBoudaryPoints()。数轴大法:在前-1,在后1,同一个点0.
- 复制范围:cloneRange()。修改副本端点不会影响到原来的范围,而cloneContents()复制的是指向同一个区域的对象,所以会有影响。
- 清理范围:range.detach();range=null;
- IE8及更早版本中的范围的一些替代手段:
- 主要处理文本范围:creatTextRange()创建文本范围对象。
- findText()参数为文本,选择第一个符合条件的文本,并将范围移动环绕此文本。找到后会返回true,否则是false。还可传入另一个表示搜索方向的参数,负值向后,正值向前。
- moveToElementText()与selectNode()相似。接受一个元素,选择该元素的所有文本。可以通过htmlText获取范围内全部内容。
- parentElement类似commonAncestorContainer作为一个动态指标。
- 复杂范围:move()/moveStart()/moveEnd/expand()向四周移动范围。接受两个参数:移动单位和移动数量。
- 操作IE范围的内容
- 修改范围内容:通过text属性或者pasteHTML()方法。
- 折叠IE范围:collapse(),并通过boundingWidth属性确定是否折叠。
- 比较IE范围:compareEndPoints(),还是数轴大法。isEqual()/inRange()顾名思义。
- 复制IE范围:duplicate()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号