问题来了
悲剧出现
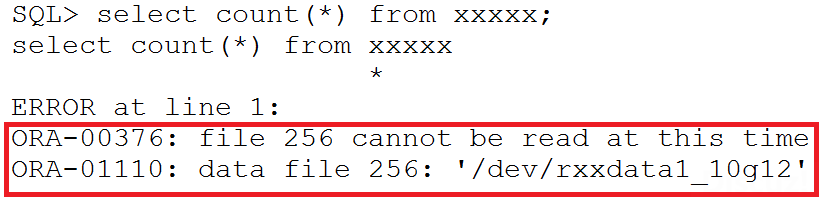
一个潜在的客户发现访问256号文件上的数据时报错,256号文件无法被访问。
进一步检查因为文件被offline,需要做recover。
并且该文件无法再online起来,原因是缺少归档日志,无法做recover。
于是向小y求救。小y心想,无非是两种情况
1) 是不是归档日志备份到磁带上了
2) 该归档日志被删除了
如果是第一种情况,那么就简单了,只需要从磁带上恢复回来即可!
如果是第二种情况,那就糟糕了,可能要丢数据了!
没关系,我们不惹事,事来了我们也不怕。
我们先来看下客户online数据文件的操作过程:
1.1 文件online
256号文件的online操作,显然oracle会提示该文件需要做介质恢复即media recovery。因为文件在offline的时候(不管什么原因)不会把该文件所对应的脏块刷到磁盘中。
1.2 Recover 数据文件
于是客户做了recover datafile 256的操作,并输入AUTO,但是数据库提示找不到序列号为14389的日志文件
1.3 查看报错信息
操作系统上检查,该日志文件也不存在
1.4 归档日志去哪了
是不是备份到磁带上以后,在文件系统上被删除了呢?
检查rman的备份情况,发现节点1所需要的归档日志根本没有任何备份的记录!
这下悲催了!256号文件online所需要的的归档日志已经被删除!数据可能要丢失了!
Part 2
事故时如何发生的
一个小变更怎么会导致这样的状况
经了解,这是一个IBM AIX上的10g RAC环境,数据文件采用裸设备。
客户最近刚为RAC做了一次表空间加数据文件的“小”变更!
那么文件被offline,以及归档日志找不到了,这两个问题的出现和这次变更有直接的关系么?给表空间加个数据文件,这样的变更也会导致数据丢失么?
也许你会觉得不可思议,不过小y基本已经猜到了过程。不同的地方总在上演着类似的悲剧。
到这里,建议读者朋友们可以先停一下,思考一下变更和这两个问题的关联!以及思考一下,如果是你,你接下来会协助客户怎么继续处理呢?
Part 3
剧情重现
为什么文件被offline&归档日志没了?
其实很简单,我们直接来看变更过程和问题出现的整个过程:
3.1 变更“成功”
1月4日11:50分左右,客户发起了变更。在RAC第二个节点为某个表空间添加了两个数据文件,并且添加成功。Alert日志显示Completed。变更“成功”
3.2 真的成功了么?
但是变更真的成功了么?变更做的利索么?
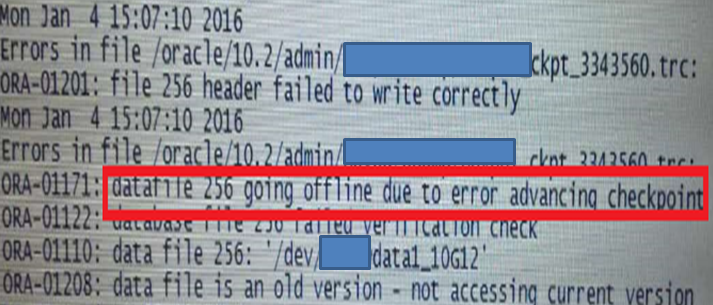
15:07分,节点1 在做checkpoint的时候,需要更新每个数据文件头的SCN号,但是由于新加的裸设备的操作系统权限不对,出现IO报错。显然,这是一个典型的RAC忘记修改一个节点权限的问题。这么多ORA-报错,如果这个时候发现并处理,那么一切还来得及!只是..没有可是了…
3.3 数据文件强制offline
15:07分,节点1由于裸设备的权限问题,checkpoint无法写文件头的SCN,因此新加入的两个数据文件被强制offline. 这么多ORA-报错,如果这个时候发现并处理,那么一切还来得及!只是..没有可是了…
3.4 发现问题
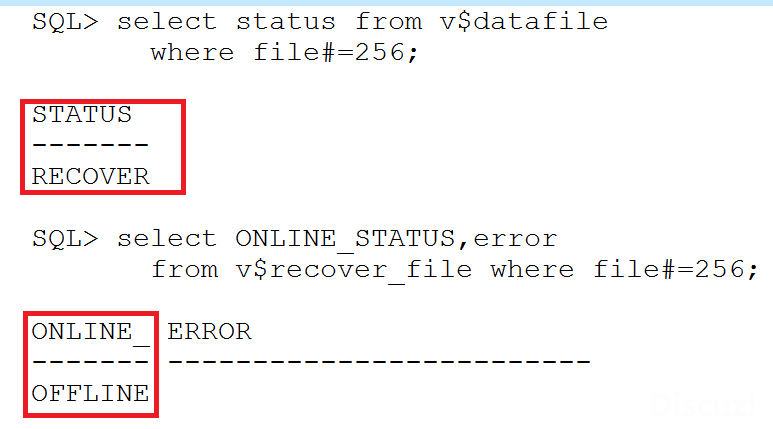
过了N个小时,当节点1访问这两个文件中的数据开始报错时,客户开始意识到问题的严重性了!从视图v$recover_file中可以看到,file_id为256和257的两个文件处于offline状态。
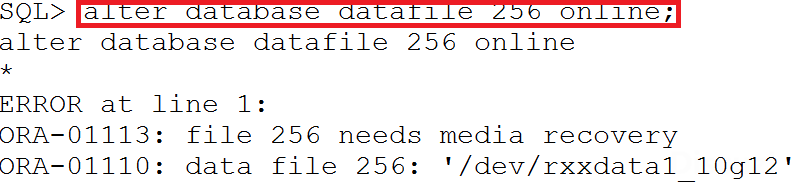
发现裸设备权限忘记修改的问题后,客户修改了节点1的裸设备的权限并且执行alter database datafile ‘/dev/xxx’ online数据文件时,提示需要做recover。
检查发现节点1文件被offline期间的的归档日志在文件系统已经被删除,rman还没来得及备份,再也无法恢复!
那么是什么原因导致归档日志被删除了呢?
还记得我们在文章一开始“前言”部分的下面这段话么?
你的系统中是否还存在着类似下面这样一个处理逻辑的脚本呢?
为了避免归档日志来不及备份到磁带从而将归档文件系统撑满继而导致数据库hang,很多客户的系统中往往存在这样的一个脚本,当归档文件系统使用率达到60%的时候,启动脚本备份日志到带库,当归档日志使用率超过90%,删除归档日志,并且发出报警信息,提示归档日志被删除,需要尽快进行一次全备!
看上去这么做无可厚非啊,有问题么?
这么做到底有没有问题呢?
没错,客户的系统中就存在着这么一个脚本!
由于备份到磁带不正常,导致归档日志文件系统使用率达到阀值,继而触发了脚本删除归档日志的操作!再加上变更时忘记修改一个节点裸设备权限的“巧合”,导致了悲剧的发生!
到这里,你是否还觉得为了避免数据库hang而删除归档日志,事后再发起全备的做法是一个安全的做法呢?答案显然是否定的!小y相信,90%以上的DBA在删除归档日志的时候是不会去查看v$recover_file中是否存在需要恢复的文件的!
Part 4
还有救么?
怎么解决?
这种情况下,有办法把数据文件online起来么?(当然也可以用抽取软件直接抽取数据)
小y这么问,自然是有办法,而且方法很简单(不到5步)。
用
bbed将被offline文件的文件头的SCN改到和其他数据文件SCN一致即可,做起来也就几分钟,大家下来不防可以自己试一下。需要说明的是,这不过是一种骗过数据库一致性检测的方法,丢失了日志文件,数据丢失是不可避免的!
使用bbed修改数据文件头SCN时,唯一要小心的是修改时注意不同平台字节序的问题,linux平台是小字节序,高低位是相反的。
这里小y以自己环境的19号文件被offline后并且online需要的归档日志已经被删除的情况为例,来说明处理的过程。
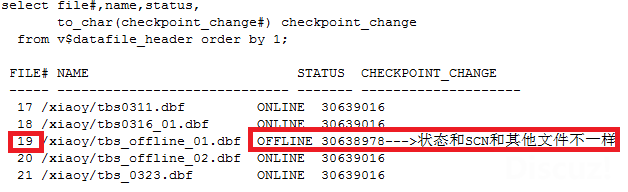
4.1 检查SCN
检查v$datafile_header, 19号文件状态是offline,SCN和其他文件不一样
丢失日志的情况下,要想把文件online起来,只能骗过数据库,我们只要把19号数据文件的文件头上的SCN改成和其他文件比如17/18号文件一样就可以。
4.2 确定SCN
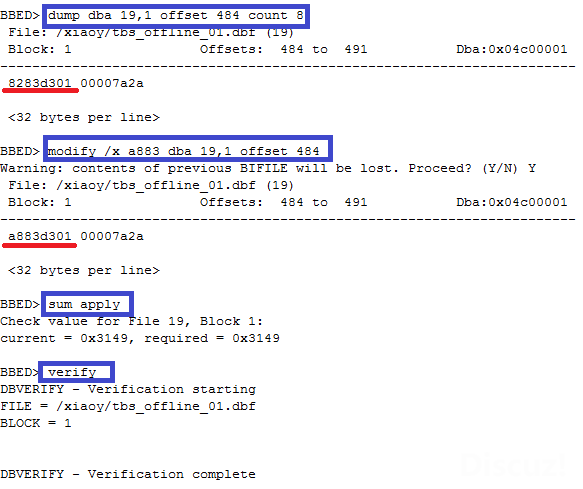
SCN号存在每个文件文件头(块号是1)的kcvfhckp.kcvcpscn这个结构当中,蓝色代表输入的命令,如下所示,红色部分即offset 484往后的4个字节表示SCNBASE,用16进制表示,我们将其用计算器转变为 10进制后,得到的数就是上图v$datafile_header的SCN。
4.3 注意字节存放高低位顺序
下图采用dump命令显示的的SCN号是 a883d301(见下划线)和上图中的

刚好是按照字节高低位相反的。

4.4 修改SCN
采用modify命令将19号文件的文件头上的SCN改成和其他文件比如17/18号文件一样,并重新计算校验值,最后verify确认BLOCK没检出异常就改完SCN了。
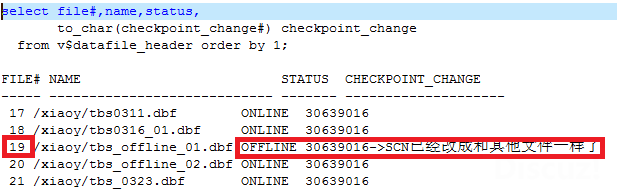
再次检查v$datafile_header,可以看到已经将19号文件已经被我们改成和其他文件SCN一样。
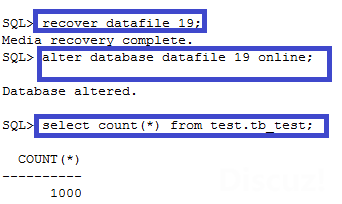
4.5 数据文件online
recover datafile后online起来,修复完成
Part 5
这是重点
故障原因总结:
本次案例中,为Oracle RAC表空间添加数据文件的一个变更,由于在一个节点忘记修改权限,导致数据文件被offline,后来归档日志由于文件系统使用率的原因,被脚本自动删除,从而导致了数据丢失的悲剧。通过bbed可以在没有日志文件的情况下把文件online起来,但是数据丢失是不可避免的!
中亦科技关于建设数据库科学运维体系的建议:
相信大家有一个共识,那就是“变更是导致故障的重灾区”。
运维无小事,变更无大小。
小的变更,往往因为熟练、轻视而没有充分准备详细的变更步骤。凭经验做事,加上熬夜疲惫、精神松懈等原因,很容易遗漏一些小的细节而导致大祸。
确实是这样的。
变更由人来操作(不可能用自动化运维手段来实现全部变更),是人就一定会有犯错的几率,即使是双人复核,也不能完全避免,而且真正长期做到变更双人复核的客户,绝对是少数。
那么,建设一套科学的运维体系就显得尤为重要了!
科学的体系下可以减少问题出现的概率。
以运维中的变更环节来举例,从方法论上来说,小y建议:
1、 梳理所有的变更
2、 梳理所有变更的风险点
3、 针对每个风险点,缕出对应的可行性解决方案
4、 解决方案从原则上说,是需要独立于现场实施人员的
具体到今天所分享的这个案例,小y认为有很多值得改进的地方:
1、 对于采用裸设备的RAC环境,缺少对于每个节点数据文件在OS上权限的监控
如果有这样的一个监控点,很快就可以发现节点1忘记修改权限,那么也就不会被offline了,也就不会出现由于数据丢失引发的故障了
2、 缺少对v$recover_file的监控
如果有这样的一个监控点,很快就可以发现文件被offline的情况,及时online起来就可以解决。另外,Online这个动作是否可以做成自动化呢?
3、 缺少对alert日志ORA-错误的监控或及时处理的机制
监控点的级别设置是否准确呢?同样是ORA-错误,预警则很容易被忽略;而严重则会发送短信通知。例如,小y有些同事在数据中心,每天需要轮着值班,对着监控的告警,逐条确认和分析、处理,以确保不被遗漏,从而保障业务的连续性。
4、 缺少对备份的监控或(和)及时处理机制
如果发现备份不成功的问题,例如备份作业太多导致排队,那么可以通过错峰、增加带机等形式,也就不会出现归档日志超过阀值得情况了。
5、 系统中无论如何也不应该存在删除归档日志的脚本
不删除怎么办呢?数据库会hang啊?你是接受数据库hang还是数据丢失?答案是显而易见的。归档空间不够,这需要从空间规划来入手,不行就预留七天的空间。数据的安全比廉价的存储空间更重要
原文地址:http://www.itpub.net/thread-2090323-1-1.html