

Python 实用小工具 练习(2)
2-2 Json 知识点
json.load():用于从json文件中读取数据。
json.loads():用于将str类型的数据转成dict。
json.dump():用于将dict类型的数据转成str,并写入到json文件中。
json.dumps():用于将dict类型的数据转成str。(dumps = dump string 不是dumps)
llicety Python json unicode utf-8处理总结
json.dumps 序列化时对中文默认使用的ascii编码,想输出真正的中文需要指定ensure_ascii=False。

2-3 xPath(Html、XML查询语言)
URL(uniform resource locator)统一资源定位器
安装 pip install lxml
2-4 xPath 实战
获取文本
//标签1[@属性1=“属性值1”]/标签2[@属性2=“属性值2”]/.../text()
获取属性值
//标签1[@属性1=“属性值1”]/标签2[@属性2=“属性值2”]/.../@属性n #超链接地址
//与/区别:/文档根路径匹配,//任意位置匹配
读取保存HTML出现错误,'utf-8' codec can't decode byte 0xb5 in position
解决办法《Python3解决UnicodeDecodeError: 'utf-8' codec can't decode byte..问题 终极解决方案》
cuiqingcai大佬关于lxml库使用的帖子《Python爬虫利器三之Xpath语法与lxml库的用法》
定位还有问题,先看崔大佬帖子里推荐视频。
2-5、2-6 Requests库
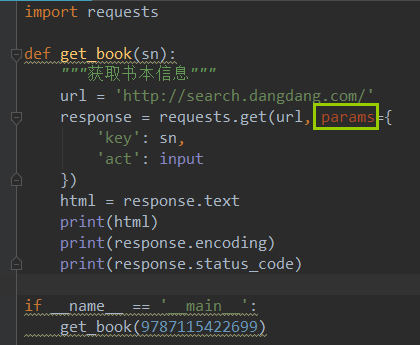
2-7 字符串的使用
%格式化字符串及HighBig(.format)格式方法
%c 转换成字符(ASCII码值)
%r 优先用repr()函数进行字符串转换
%s 优先用str()进行字符转换
%d 转成有符号十进制数
%u 转成无符号十进制数
%o 转成无符号八进制数
%f 转成浮点数(小数部分自然截断)
%e 转换成科学记数法
%% 输出%
2-8 当当爬虫
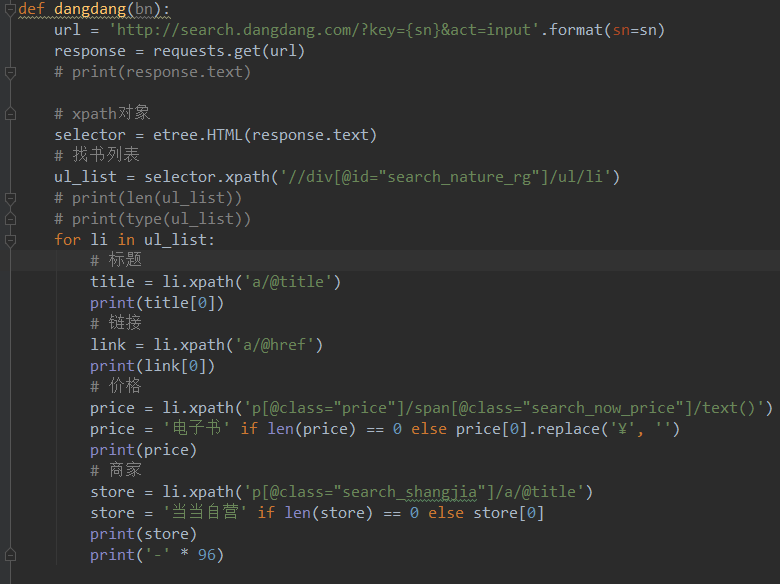
注意:xpath定位、HighBig格式化需加强
2-9 京东爬虫
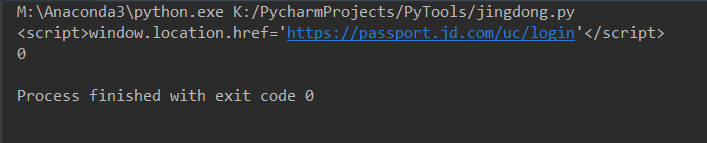
被限制了,简单添加了协议头还是一样,先看完再找办法。
2-11 淘宝爬虫
搜索结果需登录才能看到
2-12比价
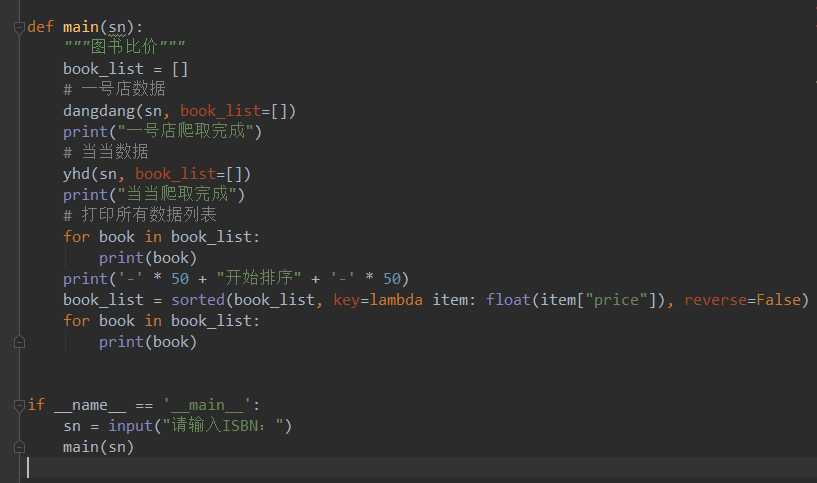
京东和淘宝采集限制,最后照例子只测试了一号店和当当。最后感觉有点乱,不是很严谨,算是给我这种新人一种思路。
这一期带来的内容:格式化字符串和lambda函数以及引用函数。后续自己用这种思路试试其他比价、预警程序。
