
NLP之统计语言模型SLM(三)
统计语言模型是用来计算一个句子产生概率的概率模型。
句子S由w1 , w2 , … , Wn组成,我们将S这个序列出现的概率表示为P(S),既然S=w1 , w2 , … , Wn,那么就有P(S)=P(w1 , w2 , … , Wn).
利用条件概率有
P(S)=P(W1 , W2 , … , Wn)=P(W1)·P(W2|W1)·P(W3|W1, W2)···P(Wn|W1,W2,…,Wn-1)
P(S)即是语言模型。
1、N-Gram
N-Gram语言模型简单有效,但是它只考虑了词的位置关系,没有考虑词之间的相似度,词语法和词语义,并且还存在数据稀疏的问题,所以后来,又逐渐提出更多的语言模型,例如Class-based ngram model,topic-based ngram model,cache-based ngram model,skipping ngram model,指数语言模型(最大熵模型,条件随机域模型)等
马尔科夫偷了个懒,认为Wi出现的概率只根Wi-1有关(马尔科夫模型,即MM,后面有个HMM,即隐藏马尔科夫模型),简化成
P(S)=P(w1)·P(w2|w1)·P(w3|w2)···P(Wn|Wn-1) (1.1 Bigram 二元模型)
P(S)=P(w1)·P(w2|w1)·P(w3|w2, w1)···P(Wn|Wn-1,Wn-2) (1.2 Trigram 三元模型)
| 一元 | 一个字词 | 上下文无关,等同于字典分词,即机械分词 | |
| 二元 | 二个字词 | bigram model | 一阶MM/HMM |
| 三元 | 三个字词 | triple model | 二阶MM/HMM |
2、神经网络语言模型
2.1 ffnnlm
Bengio等人发表的《A Neural Probabilistic Language Model》它也是基于N-Gram的,首先将每个单词w_{m-n+1},w_{m-n+2} … w_{m-1}映射到词向量空间,再把各个单词的词向量组合成一个更大的向量作为神经网络输入,输出是P(w_m)。本文将此模型简称为ffnnlm(Feed-forward Neural Net Language Model)。ffnnlm解决了传统n-gram的两个缺陷:(1)词语之间的相似性可以通过词向量来体现;(2)自带平滑功能
2.2 rnnlm
目前state-of-the-art语言模型应该是基于循环神经网络(recurrent neural network)的语言模型,简称rnnlm。循环神经网络相比于传统前馈神经网络,其特点是:可以存在有向环,将上一次的输出作为本次的输入。而rnnlm和ffnnlm的最大区别是:ffnnmm要求输入的上下文是固定长度的,也就是说n-gram中的 n 要求是个固定值,而rnnlm不限制上下文的长度,可以真正充分地利用所有上文信息来预测下一个词,本次预测的中间隐层信息(例如下图中的context信息)可以在下一次预测里循环使用。
基于RNN的language model利用BPTT(BackPropagation through time)算法比较难于训练,原因就是深度神经网络里比较普遍的vanishing gradient问题[55](在RNN里,梯度计算随时间成指数倍增长或衰减,称之为Exponential Error Decay)。所以后来又提出基于LSTM(Long short term memory)的language model,LSTM也是一种RNN网络,关于LSTM的详细介绍请参考文献[54,49,52]。LSTM通过网络结构的修改,从而避免vanishing gradient问题。
Bi-LSTM-CRF模型
实际应用的是Bi-LSTM-CRF模型

1)LSTM,即long short term memery 长短期记忆
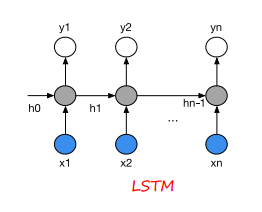
2)Bi-LSTM,即Bidirectional long short term memery 双向长短期记忆
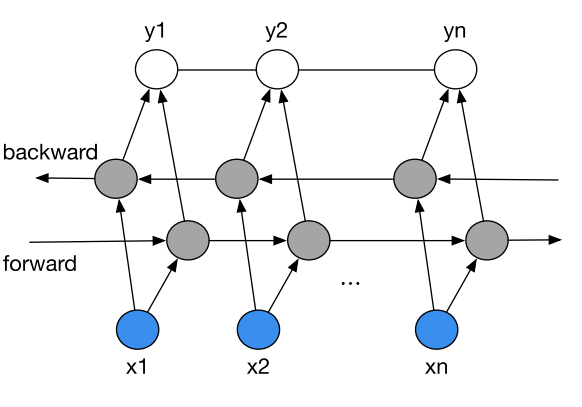
3)CRF

CRF比LSTM少了memery cell,LSTM与CRF相比,缺少全局(sentence-level)解码
具体实现见https://github.com/koth/kcws

