

内核随记(三)--同步(1)
1、概述
同步问题是操作系统中的经典问题,它伴随着并发处理而自诞生。现代体系结构中常见的并发处理情况可以分为如下三种情况:
(1)多个线程在单处理器上执行——多线程编程
(2)多个线程在多处理器上执行——并行计算
(3)多个线程在分布的多个处理上执行——分布式计算
相应的编程也分成三种情况:
共享变量编程、分布式(基于消息)编程和并行编程。
1.1、并发程序设计的本质
并发程序通常包括两个或多个进程一起工作,共同完成一项任务,于是进程(线程)间的通信产生,也就产生了同步问题。进程(或者线程)间需要通信是产生同步的根本原因,正是因为需要通信,才需要同步。进程之间有两种通信方式:共享变量(shared variables)和消息传递(message passing)。使用共享变量时,一个进程对变量进行写操作,另一个进程进行读操作。使用消息传递时,一个进程发送消息,一个进程接收消息。不管使用哪种通信方式,进程之间需要进行同步。有两种基本的同步方式:互斥(mutual exclusion)和条件同步(condition synchronization)。互斥保证关键代码段不会同一时刻执行。条件同步会阻塞进程,直到相应的条件发生。例如,对于通过共享内存方式来实现通信生产者和消费者进程,互斥变量保证生产者访问内存时,消费者不会访问内存。条件同步保证生产者写数据之前,消费者不会读数据。
同步的根本目的是创建临界区(critical region)或者等待特定的条件,常用的方式有:锁(lock)、信号量(semaphore)和管程(monitor)。前两者在Linux都有实现,最后一种方式一般在用户态层面实现(比如Java就是采用管程来实现同步原语的)。
并发编程的硬件来源:中断和多处理器。
1.2、硬件架构
常见而流行的三种计算机架构:(1)单处理器和内存(2)共享内存多处理器(3)分布式内存,包括多计算机和计算机网络。
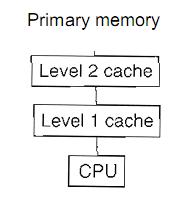
1.2.1、单处理器体系结构
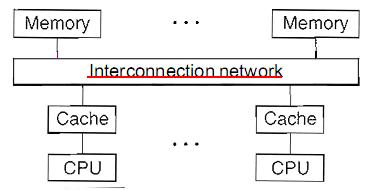
1.2.2、共享内存多处理器
处理器与内存之间通过互连网络连接起来。小规模的多处理器计算机可以包括30个处理器不等。互连网络通过内存总路(memory bus)或交换开关(crossbar switch)来实现。这种架构通常叫做UMA计算机,因为每个处理器和内存之间有相同的访问机会。UMA机器也叫做SMP。
1.2.3、分布式内存多处理器
在分布式内存多处理器结构中,也存在用于通信的互连网络,但是每个处理器都有它自己的私有内存(private memory)。
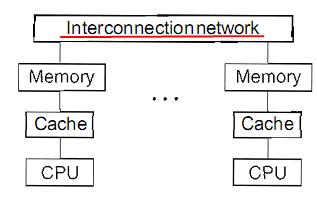
这种结构使用消息传递,而不是读写内存;不存在缓存和内存一致性问题。
为了利用多个处理器,有三种应用程序:多线程系统、分布式系统和并行计算。
2、Linux内核同步
Linux内核中产生并发处理的硬件来源有两个:中断和多CPU。其基本同步方式有四种:关闭中断(只对本地CPU)、原子操作(atomic operation)、自旋锁(spin lock)和信号量。原子操作实际上只是对CPU原子指令的简单包装,它的原子性由硬件保证。而硬件提供的原子指令是实现锁和信号量的基础。
对于内核态,CPU可能处于两处不同的内核控制路径:中断处理和异常处理(包括系统调用)。对中断处理程序,在单CPU下,可以通过禁止中断实现临界区;在多CPU下,可以通过自旋锁实现临界区。对异常处理程序,在单CPU下,可以通过禁止内核抢占实现临界区;在多CPU下,可以通过信号量实现临界区。
2.1、自旋锁(spin lock)
自旋锁主要是针对多CPU的,它是一种忙等待形式的同步(所以浪费CPU机器周期),主要用于中断处理。对于由自旋锁保护的临界区,会禁止内核抢占。对于单CPU,自旋锁除了禁止(或者开启)内核抢占外,什么也不做。
2.1.1、硬件支持
在X86平台下,可以对如下一些指令加上LOCK前缀来保证指令的原子性执行:
(1) 位测试修改指令,如BTS,BTR和BTC;
(2) 交换指令XCHG,实际上,对于该指令,即使不加LOCK前缀,也是自动原子执行;
(3) 一些单操作数算术和逻辑运算指令,如INC, DEC ,NOT和NEG;
(4) 一些双操作数指令,如ADD, ADC,SUB,SBB, AND ,OR和XOR。
这些原子操作是实现自旋锁和信号量的基础。
2.1.2、自旋锁的实现
提供的接口如下:

数据结构:
 //include/asm-i386/spinlock.h
//include/asm-i386/spinlock.h
/*自旋锁数据结构,2.6.10*/
typedef struct {
volatile unsigned int lock;
#ifdef CONFIG_DEBUG_SPINLOCK
unsigned magic;
#endif
} spinlock_t;
/*从2.6.11开始,与2.6.10有些变化*/
typedef struct {
volatile unsigned int slock;
#ifdef CONFIG_DEBUG_SPINLOCK
unsigned magic;
#endif
#ifdef CONFIG_PREEMPT
unsigned int break_lock;
#endif
} spinlock_t;
接口的实现:
//include/linux/spinlock.h
#define spin_lock(lock) _spin_lock(lock)
#define spin_unlock(lock) _spin_unlock(lock)
////////////////////////////抢占内核的spin_lock//////////////////////
//kernel/spinlock.c
void __lockfunc _spin_lock(spinlock_t *lock)
{
preempt_disable(); //禁止内核抢占
if (unlikely(!_raw_spin_trylock(lock)))
__preempt_spin_lock(lock);
}
//include/asm-i386/spinlock.h
//返回1表示获得了自旋锁,返回0表示获取自旋锁失败
static inline int _raw_spin_trylock(spinlock_t *lock)
{
char oldval;
/*xchgb是原子字令.
**这些指令相当于:oldval=0;tmp=oldval;oldval=lock->lock;lock->lock=tmp;
**即读取lock字段的旧值,将将其设为0(即锁住状态)
旧
*/
__asm__ __volatile__(
"xchgb %b0,%1"
:"=q" (oldval), "=m" (lock->lock)
:"0" (0) : "memory");
//如果自旋锁的旧值为正数(即原自旋锁处于unlock状态,当前内核控制中径可以获取锁),则函数返回1,否则返回0
return oldval > 0;
}
//include/linux/preempt.h
#define preempt_disable() \
do { \
inc_preempt_count(); \
barrier(); \
} while (0)
//kernel/spinlock.c
//当前CPU内核控制路径获取自旋锁失败时调用该函数
static inline void __preempt_spin_lock(spinlock_t *lock)
{
if (preempt_count() > 1) {
_raw_spin_lock(lock);
return;
}
do {
//抢占计数器值减1,在等待自旋锁时,允许内核抢占
preempt_enable();
while (spin_is_locked(lock))
cpu_relax();
preempt_disable();
} while (!_raw_spin_trylock(lock));//循环请求自旋锁
}
///////////////////////////对于非抢占内核的spin_lock//////////////////////////////
//对于非抢占的内核spin_lock
void __lockfunc _spin_lock(spinlock_t *lock)
{
//对于非抢占内核,什么也不做
preempt_disable();
_raw_spin_lock(lock);
}
//include/asm-i386/spinlock.h
static inline void _raw_spin_lock(spinlock_t *lock)
{
#ifdef CONFIG_DEBUG_SPINLOCK
if (unlikely(lock->magic != SPINLOCK_MAGIC)) {
printk("eip: %p\n", __builtin_return_address(0));
BUG();
}
#endif
__asm__ __volatile__(
spin_lock_string
:"=m" (lock->lock) : : "memory");
}
#define spin_lock_string \
"\n1:\t" \
"lock ; decb %0\n\t" \ #锁计数器值减1
"jns 3f\n" \ #如果小于0,则跳到标号3
"2:\t" \
"rep;nop\n\t" \ #执行空指令
"cmpb $0,%0\n\t" \ #与0比较
"jle 2b\n\t" \ #小于或等于0,则跳到2
"jmp 1b\n" \ #大于0,则跳到1
"3:\n\t"
/////////////////////////spin_unlock的实现/////////////////////////////////
void __lockfunc _spin_unlock(spinlock_t *lock)
{
_raw_spin_unlock(lock);
preempt_enable();
}
//include/asm-i386/spinlock.h
static inline void _raw_spin_unlock(spinlock_t *lock)
{
#ifdef CONFIG_DEBUG_SPINLOCK
BUG_ON(lock->magic != SPINLOCK_MAGIC);
BUG_ON(!spin_is_locked(lock));
#endif
__asm__ __volatile__(
spin_unlock_string
);
}
#define spin_unlock_string \
"movb $1,%0" \
:"=m" (lock->lock) : : "memory"
同步问题是操作系统中的经典问题,它伴随着并发处理而自诞生。现代体系结构中常见的并发处理情况可以分为如下三种情况:
(1)多个线程在单处理器上执行——多线程编程
(2)多个线程在多处理器上执行——并行计算
(3)多个线程在分布的多个处理上执行——分布式计算
相应的编程也分成三种情况:
共享变量编程、分布式(基于消息)编程和并行编程。
1.1、并发程序设计的本质
并发程序通常包括两个或多个进程一起工作,共同完成一项任务,于是进程(线程)间的通信产生,也就产生了同步问题。进程(或者线程)间需要通信是产生同步的根本原因,正是因为需要通信,才需要同步。进程之间有两种通信方式:共享变量(shared variables)和消息传递(message passing)。使用共享变量时,一个进程对变量进行写操作,另一个进程进行读操作。使用消息传递时,一个进程发送消息,一个进程接收消息。不管使用哪种通信方式,进程之间需要进行同步。有两种基本的同步方式:互斥(mutual exclusion)和条件同步(condition synchronization)。互斥保证关键代码段不会同一时刻执行。条件同步会阻塞进程,直到相应的条件发生。例如,对于通过共享内存方式来实现通信生产者和消费者进程,互斥变量保证生产者访问内存时,消费者不会访问内存。条件同步保证生产者写数据之前,消费者不会读数据。
同步的根本目的是创建临界区(critical region)或者等待特定的条件,常用的方式有:锁(lock)、信号量(semaphore)和管程(monitor)。前两者在Linux都有实现,最后一种方式一般在用户态层面实现(比如Java就是采用管程来实现同步原语的)。
并发编程的硬件来源:中断和多处理器。
1.2、硬件架构
常见而流行的三种计算机架构:(1)单处理器和内存(2)共享内存多处理器(3)分布式内存,包括多计算机和计算机网络。
1.2.1、单处理器体系结构
1.2.2、共享内存多处理器
处理器与内存之间通过互连网络连接起来。小规模的多处理器计算机可以包括30个处理器不等。互连网络通过内存总路(memory bus)或交换开关(crossbar switch)来实现。这种架构通常叫做UMA计算机,因为每个处理器和内存之间有相同的访问机会。UMA机器也叫做SMP。
1.2.3、分布式内存多处理器
在分布式内存多处理器结构中,也存在用于通信的互连网络,但是每个处理器都有它自己的私有内存(private memory)。
这种结构使用消息传递,而不是读写内存;不存在缓存和内存一致性问题。
为了利用多个处理器,有三种应用程序:多线程系统、分布式系统和并行计算。
2、Linux内核同步
Linux内核中产生并发处理的硬件来源有两个:中断和多CPU。其基本同步方式有四种:关闭中断(只对本地CPU)、原子操作(atomic operation)、自旋锁(spin lock)和信号量。原子操作实际上只是对CPU原子指令的简单包装,它的原子性由硬件保证。而硬件提供的原子指令是实现锁和信号量的基础。
对于内核态,CPU可能处于两处不同的内核控制路径:中断处理和异常处理(包括系统调用)。对中断处理程序,在单CPU下,可以通过禁止中断实现临界区;在多CPU下,可以通过自旋锁实现临界区。对异常处理程序,在单CPU下,可以通过禁止内核抢占实现临界区;在多CPU下,可以通过信号量实现临界区。
2.1、自旋锁(spin lock)
自旋锁主要是针对多CPU的,它是一种忙等待形式的同步(所以浪费CPU机器周期),主要用于中断处理。对于由自旋锁保护的临界区,会禁止内核抢占。对于单CPU,自旋锁除了禁止(或者开启)内核抢占外,什么也不做。
2.1.1、硬件支持
在X86平台下,可以对如下一些指令加上LOCK前缀来保证指令的原子性执行:
(1) 位测试修改指令,如BTS,BTR和BTC;
(2) 交换指令XCHG,实际上,对于该指令,即使不加LOCK前缀,也是自动原子执行;
(3) 一些单操作数算术和逻辑运算指令,如INC, DEC ,NOT和NEG;
(4) 一些双操作数指令,如ADD, ADC,SUB,SBB, AND ,OR和XOR。
这些原子操作是实现自旋锁和信号量的基础。
2.1.2、自旋锁的实现
提供的接口如下:
数据结构:

/*自旋锁数据结构,2.6.10*/
typedef struct {
volatile unsigned int lock;
#ifdef CONFIG_DEBUG_SPINLOCK
unsigned magic;
#endif
} spinlock_t;
/*从2.6.11开始,与2.6.10有些变化*/
typedef struct {
volatile unsigned int slock;
#ifdef CONFIG_DEBUG_SPINLOCK
unsigned magic;
#endif
#ifdef CONFIG_PREEMPT
unsigned int break_lock;
#endif
} spinlock_t;
#define spin_lock(lock) _spin_lock(lock)
#define spin_unlock(lock) _spin_unlock(lock)
////////////////////////////抢占内核的spin_lock//////////////////////
//kernel/spinlock.c
void __lockfunc _spin_lock(spinlock_t *lock)
{
preempt_disable(); //禁止内核抢占
if (unlikely(!_raw_spin_trylock(lock)))
__preempt_spin_lock(lock);
}
//include/asm-i386/spinlock.h
//返回1表示获得了自旋锁,返回0表示获取自旋锁失败
static inline int _raw_spin_trylock(spinlock_t *lock)
{
char oldval;
/*xchgb是原子字令.
**这些指令相当于:oldval=0;tmp=oldval;oldval=lock->lock;lock->lock=tmp;
**即读取lock字段的旧值,将将其设为0(即锁住状态)
旧
*/
__asm__ __volatile__(
"xchgb %b0,%1"
:"=q" (oldval), "=m" (lock->lock)
:"0" (0) : "memory");
//如果自旋锁的旧值为正数(即原自旋锁处于unlock状态,当前内核控制中径可以获取锁),则函数返回1,否则返回0
return oldval > 0;
}
//include/linux/preempt.h
#define preempt_disable() \
do { \
inc_preempt_count(); \
barrier(); \
} while (0)
//kernel/spinlock.c
//当前CPU内核控制路径获取自旋锁失败时调用该函数
static inline void __preempt_spin_lock(spinlock_t *lock)
{
if (preempt_count() > 1) {
_raw_spin_lock(lock);
return;
}
do {
//抢占计数器值减1,在等待自旋锁时,允许内核抢占
preempt_enable();
while (spin_is_locked(lock))
cpu_relax();
preempt_disable();
} while (!_raw_spin_trylock(lock));//循环请求自旋锁
}
///////////////////////////对于非抢占内核的spin_lock//////////////////////////////
//对于非抢占的内核spin_lock
void __lockfunc _spin_lock(spinlock_t *lock)
{
//对于非抢占内核,什么也不做
preempt_disable();
_raw_spin_lock(lock);
}
//include/asm-i386/spinlock.h
static inline void _raw_spin_lock(spinlock_t *lock)
{
#ifdef CONFIG_DEBUG_SPINLOCK
if (unlikely(lock->magic != SPINLOCK_MAGIC)) {
printk("eip: %p\n", __builtin_return_address(0));
BUG();
}
#endif
__asm__ __volatile__(
spin_lock_string
:"=m" (lock->lock) : : "memory");
}
#define spin_lock_string \
"\n1:\t" \
"lock ; decb %0\n\t" \ #锁计数器值减1
"jns 3f\n" \ #如果小于0,则跳到标号3
"2:\t" \
"rep;nop\n\t" \ #执行空指令
"cmpb $0,%0\n\t" \ #与0比较
"jle 2b\n\t" \ #小于或等于0,则跳到2
"jmp 1b\n" \ #大于0,则跳到1
"3:\n\t"
/////////////////////////spin_unlock的实现/////////////////////////////////
void __lockfunc _spin_unlock(spinlock_t *lock)
{
_raw_spin_unlock(lock);
preempt_enable();
}
//include/asm-i386/spinlock.h
static inline void _raw_spin_unlock(spinlock_t *lock)
{
#ifdef CONFIG_DEBUG_SPINLOCK
BUG_ON(lock->magic != SPINLOCK_MAGIC);
BUG_ON(!spin_is_locked(lock));
#endif
__asm__ __volatile__(
spin_unlock_string
);
}
#define spin_unlock_string \
"movb $1,%0" \
:"=m" (lock->lock) : : "memory"

【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步