Java数据结构和算法(一)--栈
栈:
英文名stack,特点是只允许访问最后插入的那个元素,也就是LIFO(后进先出)
jdk中的stack源码:
public
class Stack<E> extends Vector<E> { //继承Vector,Vector和ArrayList几乎相同,都是通过数组保存数据,只不过方法有Synchronized修饰
public Stack() {
}
public E push(E item) { //push,也就是add,把数据保存得add到数组的末尾
addElement(item);
return item;
}
public synchronized E pop() { //pop,也就是removeLast(),并且返回末尾值
E obj;
int len = size(); //得到数组长度
obj = peek(); //得到数组末尾值
removeElementAt(len - 1); //删除末尾元素
return obj;
}
public synchronized E peek() { //peek,返回末尾元素,只是查询,不会删除
int len = size();
if (len == 0)
throw new EmptyStackException();
return elementAt(len - 1);
}
public boolean empty() { //empty,是否为空
return size() == 0;
}
public synchronized int search(Object o) {
int i = lastIndexOf(o);
if (i >= 0) {
return size() - i;
}
return -1;
}
}
从上面源码看到:
JDK源码中的stack通过集成Vector实现,通过数组保存数据,一般使用push()、pop()、peek()来实现stack基本功能LIFO
stack有栈顶、栈底的概念,栈底是封闭的,数据只能从栈顶进出

自定义实现stack:
public class MyStack<E> {
private int maxDepth; //栈深度
private Object[] elementData; //保存数据的数组
private int top; //栈顶的位置,空栈为-1
public MyStack() {
this.maxDepth = 10;
this.elementData = new Object[10];
this.top = -1;
}
public MyStack(int initialCapacity) {
this.maxDepth = initialCapacity;
this.elementData = new Object[initialCapacity];
this.top = -1;
}
public E push(E e) {
ensureExplicitCapacity(top +1);
elementData[++top] = e;
return e;
}
public E pop(){
E e = peek();
elementData[top] = null;
this.top--;
return e;
}
public E peek() {
return (E)elementData[top];
}
private void ensureExplicitCapacity(int minCapacity) {
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
private void grow(int minCapacity) { //扩容
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - Integer.MAX_VALUE > 0)
newCapacity = Integer.MAX_VALUE;
this.maxDepth = newCapacity;
elementData = Arrays.copyOf(elementData, maxDepth);
}
public int size() {
return top + 1;
}
public boolean isEmpty() {
return top == -1;
}
}
public static void main(String[] args) {
MyStack<Integer> stack = new MyStack<Integer>();
stack.push(1);
stack.push(2);
stack.push(3);
int size = stack.size();
for (int i = 0; i < size; i++) {
System.out.print(stack.peek() + " ");
}
System.out.println("");
for (int i = 0; i < size; i++) {
System.out.print(stack.pop() + " ");
}
}
输出结果: 3 3 3 3 2 1
这是使用ArrayList的思路实现Stack:
1、通过Object[]保存数据
2、扩展支持泛型
3、初始容量设置为10,扩容之后为原来容量的1.5倍
4、实现了push()、pop()、peek()和grow()
5、stack不适合使用for、foreach、Iterator,所以这里没实现Iterable接口,因为peek()永远只是栈顶的值,或者用pop()
PS:for循环的size,如果for循环使用pop(),不要写成:
for (int i = 0; i < stack.size(); i++) {
System.out.print(stack.pop() + " ");
}
因为弹出元素,size会变化,无法弹出所有数据,可以使用测试代码中那样,或者while循环:
while (!stack.isEmpty()) {
System.out.println(stack.pop());;
}
到此为止一个stack的功能已经实现,从输出结果看使用时没问题的
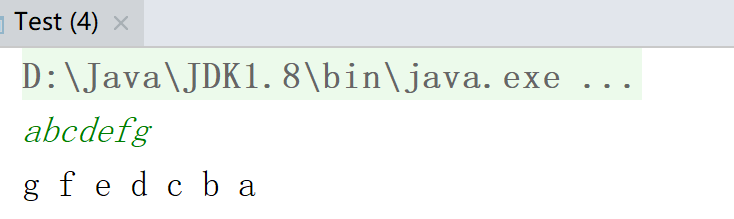
实践1:实现输入字符串,逆序输出
public static void main(String[] args) {
MyStack<Character> stack = new MyStack<Character>();
char[] chars = getInput().toCharArray();
for (char c : chars) {
stack.push(c);
}
while (!stack.isEmpty()) {
System.out.print(stack.pop() + " ");;
}
}
public static String getInput() {
String s = null;
try {
InputStreamReader reader = new InputStreamReader(System.in);
BufferedReader bufferedReader = new BufferedReader(reader);
s = bufferedReader.readLine();
} catch (IOException e) {
e.printStackTrace();
}
return s;
}
输出结果:
实践2:分隔符匹配
栈通常用于解析xml标签或者HTML标签,例如'{'要有个'}'进行匹配,通过把读取字符,发现左分隔符push,发现右分隔符pop,然后对比是否
匹配,不匹配就报错,如果栈中没有左分隔符和右分隔符匹配,或者有左分隔符一直没有被匹配,这些情况,也会报错。
例如:a{12(u<d>1)f3}
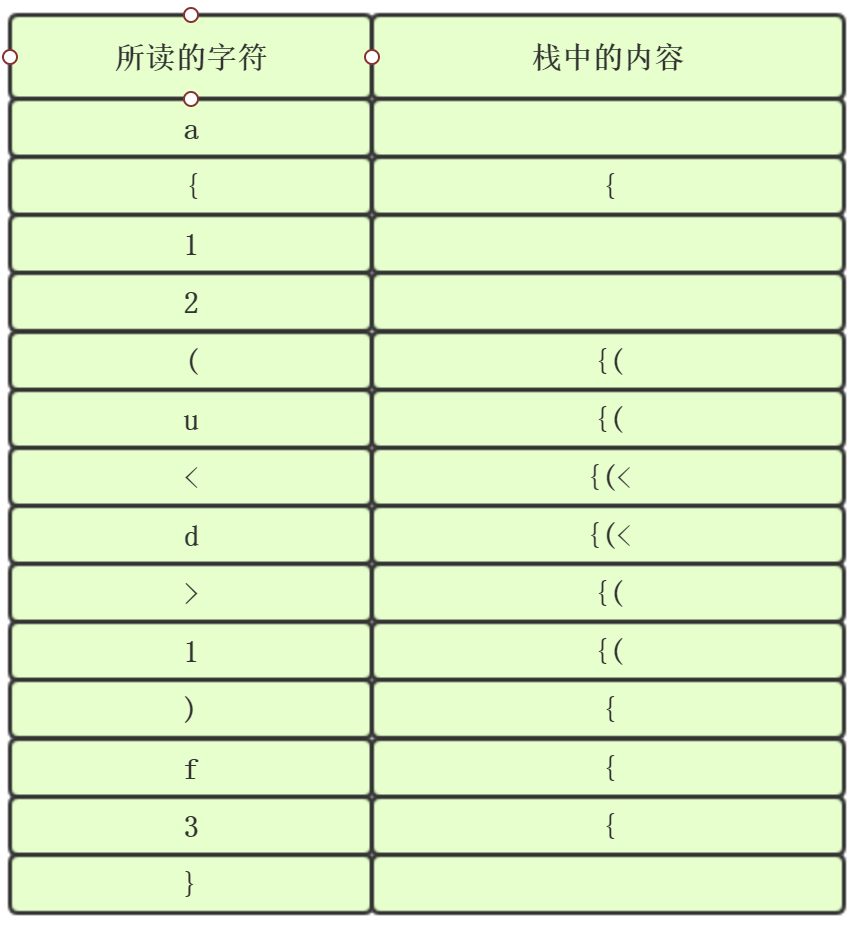
代码实现:
public static boolean isValid(String s) {
MyStack<Character> stack = new MyStack<>();
char[] chars = s.toCharArray();
for (char aChar : chars) {
switch (aChar) {
case '{':
stack.push('}');
continue;
case '<':
stack.push('>');
continue;
case '(':
stack.push(')');
continue;
default:
if (stack.isEmpty() || stack.pop() != aChar) {
return false;
}
}
}
return stack.isEmpty();
}
总结:
stack是概念上的工具,我们已经实现了两个功能,能够实现什么功能看个人实现,甚至Ctrl+Z撤销的实现就是用stack实现的
stack入栈和出栈的时间复杂度都是O(1),栈的操作时间和栈中数据的个数没有关系,不需要移动和比较,只不过我们这里实现了扩容,如果
发生扩容,会稍微影响一点
内容参考:
<Java数据结构和算法>

