

7.redis excel读写
上周复习:
1、内置函数
len
type
max()
sum()
round(5.3212,2)#取几位小数
char() #
ord() #
sorted()#排序
reversed()#反向
res = list(filter(func,[1,2,3,4,5]))#循环调用函数,False过滤,必须用list转换
res = list(map(func,[1,2,3,4,5]))循环调用,返回结果,必须用list转换
id()
eval('1+1')#执行简单代码
'''
import os
os.system('xxx')
'''
exec('')#执行复杂代码
2、函数的一点补充
递归:函数自己调用自己。
3、匿名函数
lambda s:str(s).isdigit()
def func(s):
return str(s).isdigit()
4、第三方模块安装
pip install xxx
easy_install xxx 需要安装setuptools模块
1、python操作xxx的模块
.whl
pip install 路径/pymysql.whl
.tar.gz
解压
python3 setup.py install
下面是电脑上装了多个版本的python
那你要去python的安装目录下,分别把python.exe
改个名字,能区分出来是python2还是python3
python2 -m pip install xxx
python3 -m pip install xxx
5、hashlib模块
import hashlib
s = 'xxxxx'
s = s.encode()
m = hashlib.md5(s)
res = m.hexdigest()
6、mysql数据库操作
import pymysql
conn = pymysql.connect(host,user,db,password,port,charset,
autocommit=True)
cur = conn.cursor(pymysql.cursors.DictCursor)
cur.execute(sql)
'select * from user;'
cur.fetchall() # ((1,name,password),(2,name,passwd2))
cur.fetchone() # (1,name,passwrd) {'id':1,"name":name,
"password":123234}
cur.close()
conn.close()
os.walk(r'e:\\') #递归循环一个目录
上周作业:
#1.需求:写一个函数,传入一个路径和一个关键字(关键字是文件内容),找到文件内容里面有这个关键字的文件
#循环读取路径下文件,存在关键字,返回路径+文件名
import os def seekfile(keyword,path=r'C:\Users\HDL\PycharmProjects\untitled\python'): for cur_path, cur_dirs, cur_files in os.walk(path): for file in cur_files: if file.endswith('.txt'): with open(os.path.join(cur_path,file),'r',encoding='utf-8') as f: for line in f: if keyword in line: res=os.path.join(cur_path,file) print('包含%s的文件是%s'%(keyword,res)) break seekfile('list')
#2、删除3天前的日志文件
#1、要获取到所有的日志文件 os.walk()
#2、先获取到文件的时间
#3、要判断文件的日期是否在三天前 当天的日期的时间戳 - 60*60*24*3
import time def timestampToStr(timestamp=None,format='%Y-%m-%d %H:%M:%S'): #时间戳转格式化好的时间 if timestamp: time1 = time.localtime(timestamp) res = time.strftime(format, time1) else: res = time.strftime(format) return res #20180304153958 def strTotimestamp(str=None,format='%Y%m%d%H%M%S'): #格式化的时间转时间戳 if str: timep = time.strptime(str, format) res = time.mktime(timep) else: res = time.time() return int(res) def clean_log(path,day=3): for cur_path, dirs, files in os.walk(path): for file in files: if file.endswith('log'): f_time = file.split('.')[0].split('_')[-1] file_timestamp = strTotimestamp(f_time,'%Y-%m-%d') cur_timestamp = strTotimestamp(time.strftime('%Y-%m-%d'),'%Y-%m-%d') if (cur_timestamp - file_timestamp) >= 60*60*24*day:#判断文件的时间是否大于3天 os.remove(os.path.join(cur_path,file))
3.注册、登录功能,从数据库判断用户是否存在,密码要加密
#需求:写一个注册的功能,要求数据存在数据库里面
# 1、名字为空、已经存在都要校验
# 2、校验通过之后,密码要存成密文的。
#定义函数,mysql操作,不传入用户名表示读取数据库表,传入表示写入数据库
#读取数据库表,判断用户名是否存在
#md5密码加密,加盐
#登录、注册 import pymysql def my_db(sql): conn = pymysql.connect(host='118.24.3.40',user='jxz',password='123456', db='jxz',port=3306,charset='utf8',autocommit=True) cur = conn.cursor(pymysql.cursors.DictCursor) cur.execute(sql) res = cur.fetchone() #{'username':'nhy'} {} cur.close() conn.close() return res import hashlib def my_md5(s,salt=''): s = s+salt news = str(s).encode() m = hashlib.md5(news) return m.hexdigest() def reg(): for i in range(3): user =input('username:').strip().upper() pd = input('password:').strip() cpd = input('cpwd:').strip() sql='select username from app_myuser where username = "%s";'%user if len(user) not in range(6,11) or len(pd) not in range(6,11): # 6 7 8 9 10 print('账号/密码长度错误,6-10位之间') elif pd != cpd: print('两次输入密码不一致') elif my_db(sql): print('用户已存在') else: md5_passwd = my_md5(pd) insert_sql= 'insert into app_myuser (username,passwd,is_admin) ' \ 'value ("%s","%s",1);'%(user,md5_passwd) my_db(insert_sql) print('注册成功!') break else: print('失败次数过多!') def login(): for i in range(3): username = input('请输入用户名:').strip().upper() password = input('请输入密码:').strip() sql='select username,passwd from app_myuser where username = "%s";'%username if username =='' or password =='': print('账号/密码不能为空') else: res = my_db(sql) # {'username':nhy 'passwd':'xxxxx'} if res: if my_md5(password) == res.get('passwd'): print('登陆成功!') break else: print('密码错误!') else: print('用户不存在') else: print('错误次数过多!')
上课内容:
导入模块:
1.导入模块的实质:
import 一个模块的实质就是把这个python文件从头到尾执行一遍
import my
注:直接导入文件名,不要加”.py”,把my里边的从头到尾执行一遍
2. import模块的查找模块的顺序
1) 从当前目录下找该文件
2) 从sys.path系统路径下查找该文件
3) 从上面2个目录都找不到,那就报错
3. 调用导入模块中的函数
1) 直接import
import my#导入模块
my.sayName()#调用模块中的函数,前边一定要有模块名
2) from import
from my import sayName #from 模块文件名 import 函数名
sayName()#直接调用函数,不用加my.
3. 模块文件放到哪里合适
1) 放到当前文件的目录下,这样比较麻烦,每次需要复制模块文件
2) 放到sys.path的其中一个路径下,但是每次需要复制模块文件
3) 把模块文件的路径加到sys.path中,但是这个只是临时的,每次导入模块文件之前都需要执行这个操作,比较麻烦
sys.path.append(r'/Users/nhy/PycharmProjects/day6')
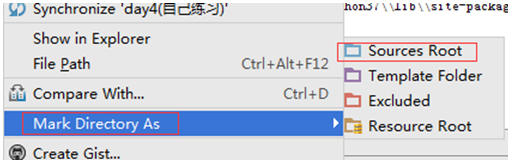
4) Pycharm左侧树下新建一个文件夹,里边存放常用的模块文件,选中该文件夹右键Mark Dicrectory As-Sources Root,则该文件夹及下边文件添加到sys.path下,永久有效,重启pycharmy也不会丢失
4.调用导入模块中的函数
1) 直接import
import my#导入模块
my.sayName()#调用模块中的函数,前边一定要有模块名
2) from import
from my import sayName #from 模块文件名 import 函数名
sayName() #直接调用函数,不用加”my."
5. if __name__ == '__main__':
别的文件里面导入这个python文件的话,就不执行下面的代码
执行自身文件会被执行
1) tool.py文件最下边写上下边内容
if __name__ == '__main__':
print(strTotimestamp())
print(clean_log('.'))
print(clean_log('.',2))
2) 单独右键执行tools.py文件,则下边文件内容会执行,直接执行
print(strTotimestamp())
print(clean_log('.'))
print(clean_log('.',2))
3) 某个文件比如d.py,导入tools模块,执行d.py文件时,if __name__ == '__main__'下边的内容不会被执行
import tools
则下边内容不会被执行
print(strTotimestamp())
print(clean_log('.'))
print(clean_log('.',2))
redis:一种非关系型数据库
1.关系型数据库和非关系型数据库
关系型数据库:用数据库、表存数据,表之间通过id相互关联,数据是存在磁盘上的
传统的关系型数据库:mysql、oracle、sql server
database
table1 user userid
table2 account userid
table3 order
userid
sql语句来操作数据
非关系型数据库、NOSQL
数据是存在内存里面,比较快
不需要通过sql语句来查询数据
传统的非关系型数据库:MongoDB(数据存在磁盘上)、redis、memcache
非关系型数据库存储数据是key = vaule形式
2.Python代码操作数据库
import redis #导入模块 ip = '***.**.*.**' password='******' r = redis.Redis(host=ip,password=password,port=6379,db=10, decode_responses=True)#连接redis #db=10 表示使用第几个数据库,默认是第0个 #decode_responses=True 表示返回数据是字符串 #string类型 # 增 set(key,value) # 删 delete(key) # 修改 set(key,value) # 查 get(key) r.set('nhy_sessionn','sdfsdfssd',30) #30指过期释放时间30s r.set('nhy_info','{"name":"xxxx","password":"123456","account":11234}') r.delete('nhy_info') #删一个不存在的key,不报错 res = r.get('nhy_info') r.flushall() #清空所有数据库里面的数据 r.flushdb() #只清空当前数据库里面的数据 r.keys() #获取到所有的key r.keys('*session*') #模糊匹配,获取到包含session的key r.expire('qml_session',30) #指定过期时间,过期之后就释放了
# 哈希类型hash #两层嵌套,外边一个大key,里边有小key #'nhy_info','{"name":"xxxx","password":"123456"} # 增 r.hset(大key,小key,value) # 删 r.delete(大key) r.hdel(大key,小key) # 修改 r.hset(大key,小key,value1) # 查 r.hgetall(大key) r.hget(大key,小key) r.hset('sms_code','18612532945','121213')#set值,两个小key不同 r.hset('sms_code','18612532941','121313') r.delete('sms_code') #把整个key删除掉 r.hdel('sms_code','18201034732') #删除指定的key r.hgetall('sms_code') #获取到这个key里面所有的内容,一个字典 {'18612532945': '121213', '18612532941': '121313'} r.hget('sms_code','18201034732') #获指定key值,一个字符串 #r.type(key) 获取key的类型string hash r.type('sms_code') r.type('lyl_session007')
3. 练习要把a redis里面的数据 全部到迁移到b redis
# 1、连上2个redis # 2、先从a redis里面获取到所有key # 3、然后判断key是什么类型,根据类型来判断使用什么方法 # 4、从aredis里面获取到数据,set 到b redis里面 import redis ip = ***.**.*.**' password='*****' r = redis.Redis(host=ip,password=password,port=6379,db=3, decode_responses=True)#连接redis r2 = redis.Redis(host=ip,password=password,port=6378,db=2, decode_responses=True)#连接redis all_key = r.keys() for k in all_key: if r.type(k) == 'string': a_data = r.get(k)#从aredis获取到的数据 r2.set(k,a_data) elif r.type(k) =='hash': hash_data = r.hgetall(k) # {'key1':'v1',key2:v2} for key,v in hash_data.items(): r2.hset(k,key,v)
excel操作:
命令行执行下边命令,安装模块
pip install xlrd #读excel
pip install xlwt #写excel
pip install xlutils #修改excel
写excel:
一个一个单元格写入,行号从0开始,列号从0开始
import xlwt #导入修改模块 book = xlwt.Workbook() #新建一个excel sheet = book.add_sheet('sheet1') #添加一个sheet页 stu_info = [ ['编号','姓名','密码','性别','地址'], [1,'machunbo','sdfsd23sdfsdf2','男','北京'], [2,'machunbo2','sdfsd23sdfsdf2','男','北京'], [3,'machunb3','sdfsd23sdfsdf2','男','北京'], [4,'machunbo4','sdfsd23sdfsdf2','男','北京'], [5,'machunbo5','sdfsd23sdfsdf2','男','北京'], [6,'machunbo6','sdfsd23sdfsdf2','男','北京'], [7,'machunbo6','sdfsd23sdfsdf2','男','北京'], [8,'machunbo6','sdfsd23sdfsdf2','男','北京'], [9,'machunbo6','sdfsd23sdfsdf2','男','北京'], [10,'machunbo6','sdfsd23sdfsdf2','男','北京'], [11,'machunbo6','sdfsd23sdfsdf2','男','北京'], ] #sheet.write(行号,列号,写入的字符串) #方法1:自定义变量,利用变量+1控制行列循环写入 row = 0 #行 for stu in stu_info: col = 0 # 列 for s in stu: #控制列 sheet.write(row,col,s) #0 3 男 col+=1 row+=1 #方法2:利用列表、元组的下标写入, #mysql数据库查询数据是二维元组,可以写入excel for index,value in enumerate(stu_info): # enumerate() 表示取到下标和值 index:下标 value:值,表示取到每行 #index:0 value: ['编号','姓名','密码','性别','地址'] #index:1 value: [1,'machunbo','sdfsd23sdfsdf2','男','北京'] for index2,v2 in enumerate(value):#再把每行按下标拆分列表 #index2:0 v2: '编号' #index2:1 v2: '姓名' sheet.write(index,index2,v2) book.save('stu3.xls')
#保存excel wps:文件名后缀是 xls或xlsx,微软的office后缀必须是xls
读excel
import xlrd #导入读excel模块 book = xlrd.open_workbook('stu3.xls')#打开需要读取的文件 sheet = book.sheet_by_index(0)#打开需要读取的sheet页 # sheet = book.sheet_by_name('sheet1') #sheet页可以通过序号读取,也可以通过名称读取 sheet.cell(0,0).value#获取指定单元格的内容,0行0列的单元格 sheet.cell(1,0).value sheet.row_values(0) #获取整行的数据,0行,结果为列表 #['id', '姓名', '密码', 'password', '地址'] sheet.row_values(1)#1行 sheet.col_values(0)#获取整列的数据,0列,,结果为列表 sheet.col_values(1)#1列 sheet.nrows #行数 sheet.ncols #列数 for row in range(1,sheet.nrows):#按行读取excel表内容 print(sheet.row_values(row))
修改excel
#1、先打开原来的excel #2、复制一份 #3、在复制的excel上修改 #4、保存 import xlrd #导入读取excel模块 from xlutils import copy #导入修改excel模块,直接使用copy方法 book = xlrd.open_workbook('stu3.xls') new_book = copy.copy(book) #复制原来的excel sheet = new_book.get_sheet(0) #在复制的excel上修改,获取sheet页得用get_sheet() sheet.write(0,0,'id')#直接使用write(行号,列号,值)进行修改 sheet.write(0,3,'password') new_book.save('stu3.xls')#保存文件,文件名必须与原文件名一致
接口开发:
使用flask模块,web框架,mock(模拟)服务,创建服务
服务里边创建接口
接口URL中传入参数,根据参数执行python代码,返回数据
1. 简单流程
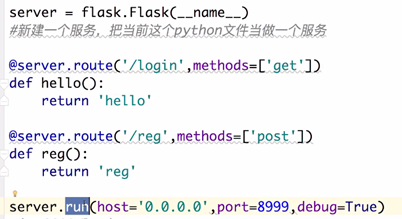
import flask #导入flask模块 server = flask.Flask(__name__) #新建一个服务,__name__表示把当前这个python文件当做一个服务 @server.route('/login',methods=['get']) def hello(): #函数紧挨着上边添加@server.route(),表示这个函数变成一个接口 #‘login’,表示访问路径是 ip:8000/login #methods=['get']表示访问url方法是get return 'hello' server.run()#启动这个服务
#执行该脚本
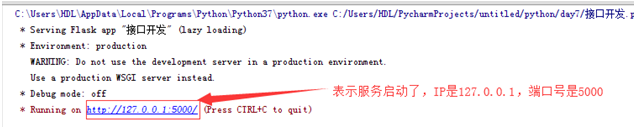
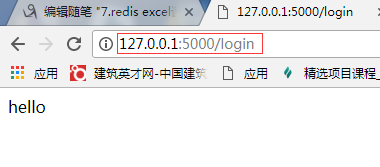
浏览器访问路径:http://127.0.0.1:5000/login
后边路径与创建接口时写的路径一致
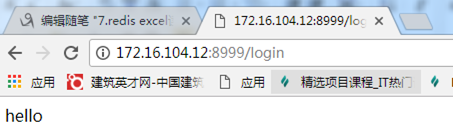
2. 指定ip端口号启动服务
server.run(host='0.0.0.0',port=8999,debug=True)#启动服务
#若ip是127.0.0.1,只能本机访问
#指定0.0.0.0,同一局域网的其他人也可以访问这台机器
#比如本机ip是172.16.104.12,同一局域网内的其他人可以访问172.16.104.12
#port=8999表示指定端口号是8999
#debug=True 表示修改代码之后自动重启服务
#访问路径是http:// 172.16.104.12:8999/login
说明:再次启动服务不能直接运行python文件,一定要点击重新运行按钮,否则旧服务没有停止,提示端口被占用

3. 如何从url中获取参数
@server.route('/login',methods=['get']) def hello(): uname = flask.request.values.get('username') #从url中获取username的值 pd = flask.request.values.get('passwd') #从url中获取passwd的值 return '%s %s'%(uname,pd)
重新启动服务
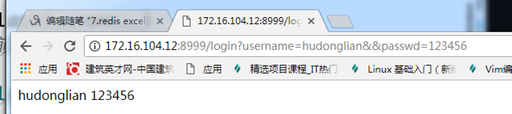
浏览器访问路径:
http://172.16.104.12:8999/login?username=hudonglian&&passwd=123456
4.一个服务创建多个接口
5.练习:使用接口访问数据库,登录功能
import flask #导入flask模块 import tools #里边包含连接数据库,md5加密函数 import json server = flask.Flask(__name__) #新建一个服务,__name__表示把当前这个python文件当做一个服务 @server.route('/login',methods=['get']) def hello(): uname = flask.request.values.get('username') #从url中获取username的值 pd = flask.request.values.get('passwd') #从url中获取passwd的值 sql = 'select * from app_myuser where username="%s";'%uname res = tools.my_db(sql) if res: if tools.my_md5(pd) == res.get('passwd'): res = {"code":0,"msg":"登录成功!"} else: res = {"code":1,"msg":"密码错误!"} else: res = {'code':2,"msg":"用户不存在"} return json.dumps(res,ensure_ascii=False,indent=4) #将返回的字典变成json串


