那些年,翻过山,趟过河,挖了山丘,黑了河沟,终于还是遇到了——跨服务器查询
准备写点扯淡些的博客,然后想了好半天,终于想到了个稍微有点文艺的标题,不喜勿喷啊,喷着我这里到处都是就不好拉。。。
一:场景
先说说场景吧,为了不过分暴露业务,就用字母代替下吧,半个月前业务那边报了个bug,说根据A条件和B条件筛选一批数据,
当把时间(C条件)范围拉小点,可以筛选出数据,把(C条件)时间拉大点,就没有数据了。
二:分析
乍一看,泥煤的。。。真的有点神奇哦,0-24点可以拉到数据,0-12点反而就拉不到了,晕。。。。然后就仔细分析了下代码,
然来不知道哪一个程序员在M库里根据各种条件筛选出了20条数据,因为B条件在N库里面,所以他拿着这20条数据到N库去做筛选,
结果20条数据全部暴毙,最后就拿着空集合送到前台了。。。问题泥煤的终于明白了,就是如何根据多条件去做跨服务器查询。
三:探索
其实也挺悲剧的,从业快四年了也没遇到这个问题,虽然在上一家公司数据库做了主从复制,跨库,尼玛的。。。也没有跨服务
器查询呀。。。不过那天问题找到后也挺兴奋的,转了转珠子想了个办法,用多线程搞一搞。。。
四: 失败的一次尝试
由于开发人员接触不了生产,要是查的话还要找二线人员。。。我人又懒,不想邮件啥的通知人家,然后就自己假象了下数据应该
不会超过多少条。。。后来就是因为这个应该导致了该解决方法的失败。
步骤如下:
①: 我那时假象一天的数据应该不会超过5w吧,为了加速,我准备多开几个线程,一个线程捞tmd的5000条数据,5w的话我就开
10个线程。10w的话就开20个线程,反正线程是随数据变的。
②: 就这样我分别从M和N库中捞出来我也不知道多少个OrderID,然后在两组OrderID里面求个交集,当然这个要注意了,从数据
结构的角度说,这个需要用hash来去重,复杂度O(M+N),当我看到C#自带的intersect就是先灌到hash里面做的,我就放
心了,至少不会出现恶心的O(MN)的复杂度了。。。
③: 求交集后,我现在就拿到一组OrderID了,然后拿这些orderID在内存中分页,取出20条OrderID后再到主库M中去查真正我需
要的数据,最后把数据送到前台上。。。

这些想法在我脑子里面遨游之后,我就啪啪啪的写完了代码,测试环境下也通过了。。。然后屁颠屁颠的上生产了,就这样噩梦开始了。。。
过了个星期,业务过来说:这下好了,原先数据查不出来,现在你给我页面报错了,我说:晕,不会吧,我马上去看看。。。查了下后,然来
发现是页面执行时间过长,iis超时了。。。唉,这下没法子了,去找二线查了下数据,居然N库中有26w的数据,那我得要开52个线程,晕死,
我不知道当时生产环境的cpu狂飙的有木有。。。苦逼呀。。。还得继续扣这些猥琐的代码。。。
五: 再次寻找解决方案
1:使用opendatasource跨服务器查询
刚才我也寒酸的分析了下5个where,有4个在M库中,有1个在N库中,那就用opendatasource来做远程服务器的inner join吧。。。
也许是公司为了性能和安全性考虑,禁用了此种使用方式,没撤,此方案破产。。。
2: 做数据的冗余
泥煤的,把我逼到绝境了。。。既然跨不了服务器,那也只能做数据冗余了,没办法,只能在M库里面建立一张冗余表,将N库中表的数
据导入到这张冗余表吧,然后我就可以堂堂正正的用sql直接inner join了,问题也就差不多解决了,说干就干吧。
<1>事前冗余
我准备在web端插入数据的时候再冗余到XX表中,虽然是个过得去的主意,但是web端太多了,你懂的,要是为了这个小功能,要去改动无
数个的web端,工作量有点大了,还不知道人家部门配合不配合。。。而且我的需求也比较特殊,需要等M库具有某些操作的时候,N库中的
表才会生成数据,所以该种方案想想还是放弃了。。。

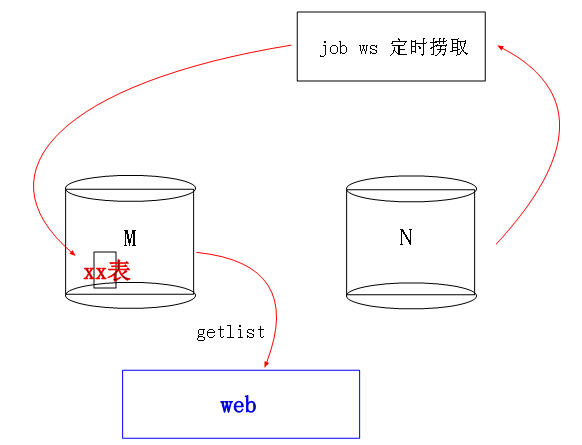
<2>事后冗余
后来还是决定用jobws每个小时去定时捞N库中的数据,然后放入M库的冗余表中,虽然业务那边看的可能不是最新的一个小时的数据,
但是没关系,这些数据不需要实时的,只要保证是最近一天的就足够了,最后也就决定这种可行点了。。。悲剧啊。。。啊啊啊啊啊。。。
突然发现博客好像没这么扯蛋过。。。还好蛋都扯完了,不过这也算是一个非常经典的问题,如果大家有什么好招数,记得分享分享
啊。。。谢谢了。。。。


【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 没有源码,如何修改代码逻辑?
· 一个奇形怪状的面试题:Bean中的CHM要不要加volatile?
· [.NET]调用本地 Deepseek 模型
· 一个费力不讨好的项目,让我损失了近一半的绩效!
· .NET Core 托管堆内存泄露/CPU异常的常见思路
· 微软正式发布.NET 10 Preview 1:开启下一代开发框架新篇章
· 没有源码,如何修改代码逻辑?
· NetPad:一个.NET开源、跨平台的C#编辑器
· PowerShell开发游戏 · 打蜜蜂
· 在鹅厂做java开发是什么体验