
Core Java 谈谈HashMap
说起Java的HashMap相信大家都不是很陌生,但是对于HashMap内部结构有些同学可能不太了解,咱们下一步就将其展开。
HashMap是基于Hash算法的,同理的还有HashSet和HashTable。我的一篇博文讲述了如果将Object作为Key的话,那么就需要注意重写其hashCode()和equals()方法,当然,这个equals()不是必要重写的,但是在Effective Java中这条是一条准则。那么针对这块有个问题,如果只写了hashCode方法不写equals或者反之呢? 咱们一会儿慢慢展开,相信同学们读完了会有所领悟。
HashMap有几个重要的概念 hashcode, entry, bucket,说道hashCode,其实它是一个Object对象的一个方法,也就说每个方法都有一个,它的默认值是对象地址然后转换为int并返回。Entry是一个Map的静态内部类,用于存储Key, value,以及指向next的一个链表(linked list)。
static class Entry<K,V> implements Map.Entry<K,V> { final K key; V value; Entry<K,V> next; int hash;
Bucket是什么呢,其实就是根据Hash值分布的一个篮子,请参考如下图表。
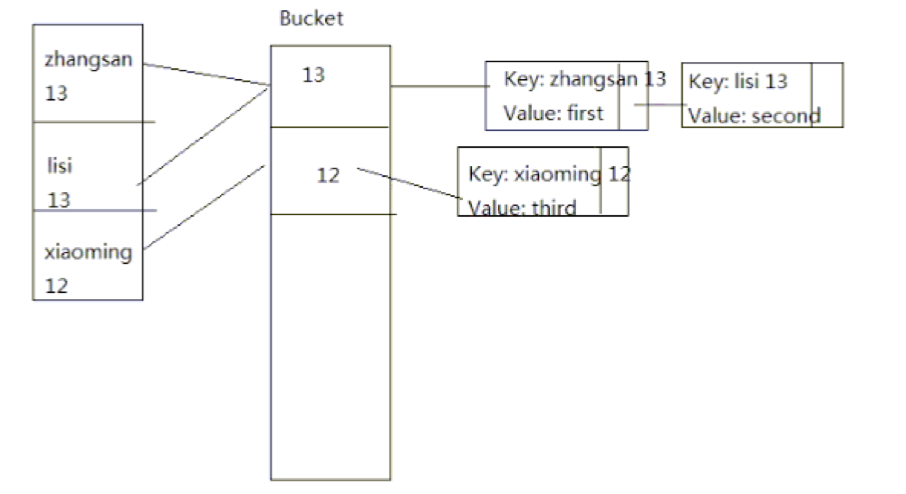
下一步,咱们直接进入HashMap源码(java 7), 从它的最原始的空构造函数入手,初始化时长度为16,0.75是负载因子。HashMap在初始化的时候没有初始化这个Entry, 它是在put的时候进行的,看inflateTable(threadhold);填充表,在这个时候这个负载因子就用到了16*0.75=12,也就是bucket默认的长度为12个,也就是hash的值只能存放12个,如果超过了12个的话,那就需要进行扩展,扩大两倍比如32,然后再根据这个负载因子去计算。
那么为什么用一个负载因子呢? 因为考虑到时间和空间之间的权衡才使用这个功能,如果这个负载因子小了,也就意味着分配的bucket比较少,这样查询和添加的时候速度比较快,但是增加bucket的速度变慢了。如果这个负载因子变大了,那么每次分配bucket的数量也随之增大了,这样会占据很大的内存空间。这个load factor参数决定了HashMap的性能。那是否还有其他参数决定HashMap的性能呢,那就是初始化的的capacity(容量),这个也可以初始化的时候设置,设置太大了在遍历的时候也会消耗很多资源。
/** * Constructs an empty <tt>HashMap</tt> with the default initial capacity * (16) and the default load factor (0.75). */ public HashMap() { this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR); }
然后继续看这个put,首先判断key是否为null,如果为null的话,就会分配一个hashcode为0的Entry用于存储。也就是HashMap支持null值并且只允许一个。
public V put(K key, V value) { if (table == EMPTY_TABLE) { inflateTable(threshold); } if (key == null) return putForNullKey(value); int hash = hash(key); int i = indexFor(hash, table.length); for (Entry<K,V> e = table[i]; e != null; e = e.next) { Object k; if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { V oldValue = e.value; e.value = value; e.recordAccess(this); return oldValue; } } modCount++; addEntry(hash, key, value, i); return null; } /** * Inflates the table. */ private void inflateTable(int toSize) { // Find a power of 2 >= toSize int capacity = roundUpToPowerOf2(toSize); threshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1); table = new Entry[capacity]; initHashSeedAsNeeded(capacity); }
* Retrieve object hash code and applies a supplemental hash function to the * result hash, which defends against poor quality hash functions. This is * critical because HashMap uses power-of-two length hash tables, that * otherwise encounter collisions for hashCodes that do not differ * in lower bits. Note: Null keys always map to hash 0, thus index 0. */ final int hash(Object k) { int h = hashSeed; if (0 != h && k instanceof String) { return sun.misc.Hashing.stringHash32((String) k); } h ^= k.hashCode(); // This function ensures that hashCodes that differ only by // constant multiples at each bit position have a bounded // number of collisions (approximately 8 at default load factor). h ^= (h >>> 20) ^ (h >>> 12); return h ^ (h >>> 7) ^ (h >>> 4); }
然后我们在继续看它的hash方法,它把key的hashCode取得了,然后又加工了一次,这是为什么呢?
因为为了防止差的hashcode功能,也就是更好的提高了hashcode的计算。然后根据hashcode去找到bucket所在的index,如果index相同的话怎么办呢,然后再去取出它的key,将key和Entry里边的Key再次进行比较,如果相等equals()的话,那么就可以取出结果了,如果不相等的话,继续Entry.next()进行判断,最后如果没有找到的话,就会返回null。
这里大家一定要注意Entry里边存放了key, value, next, 这时这个key取出来就用于判断了。这下同学们明白了如果hashcode相同了怎么处理了吧。如果如果一个key在设计时只重写了equals而没有写hashcode(),那么会出现什么现象呢? 答案是两个对象会被当做两个不同的对象放到了不同的bucket里边,这其实违背了一个很重要的原则:The part of the contract here which is important is: objects which are .equals() MUST have the same .hashCode(). 对象相等即它的hashCode相等。如果是在HashSet的里面,会被当做两个相同的对象,但这时错误的比如:Person a = new Person("zhangsang",13); Person b = new Person("zhangsan", 13); 如果只重写equals,那么他们是equal的,但是放到set里边会被认为两个对象。
还有一点就是put和get的时间复杂度为O(1),这就是它的hash的原理了。下面是我自己写的代码,供大家参考。
package com.hqs.core; import java.util.HashMap; import java.util.Iterator; import java.util.Map; public class Person { private final String name; private int age; public Person(String name, int age) { this.name = name; this.age = age; } @Override public String toString() { return "name: " + this.name + " age: " + this.age + " "; } @Override public int hashCode() { return this.age; } @Override public boolean equals(Object obj) { boolean flag = false; if(obj == null) flag = false; if(obj == this) flag = true; if(getClass() != obj.getClass()) flag = true; Person p = (Person) obj; if(p.name != null && this.name !=null) { if(p.name.equals(this.name) && p.age == this.age) flag = true; } else { flag = false; } return flag; } public static void main(String[] args) { Person zhangsan = new Person("zhangsan", 13); Person lisi = new Person("lisi", 13); Person xiaoming = new Person("xiaoming", 12); System.out.println("zhangsan hashCode: " + zhangsan.hashCode()); System.out.println("lisi hashCode: " + lisi.hashCode()); System.out.println("xiaoming hashcode: " + xiaoming.hashCode()); Map map = new HashMap(); map.put(zhangsan, "first"); map.put(lisi, "second"); map.put(xiaoming, "third"); Iterator<Person> it = map.entrySet().iterator(); while(it.hasNext()) { Map.Entry entry = (Map.Entry<Person, String>)it.next(); Person person= (Person)entry.getKey(); String value = (String)entry.getValue(); System.out.println(person + value); } } } zhangsan hashCode: 13 lisi hashCode: 13 xiaoming hashcode: 12 name: xiaoming age: 12 third name: lisi age: 13 second name: zhangsan age: 13 first
如果有写的不对的地方,还希望同学们给一些意见:68344150@qq.com

