


电商搜索系统存在以下特点:
数据量庞大。(上亿级别)
高并发。(日均pv过亿、数十亿)
一条商品数据由商品基本信息、价格、库存、促销、评价等组成,这些数据存储在各自业务系统当中。(多数据源导致构建索引比较麻烦)
召回率要求高。(哪个商家发现搜不到自家的商品肯定要抓狂,哪怕有一个搜不到。)
时效性要求高,价格变动、库存变动、上下架等要求近实时。(更新时间过长虽然不会造成资损,但是会严重影响用户体验)
索引更新量庞大。(上千万级别)
排序!排序!排序!如何把用户最想要的排在前面,提升转化率,是搜索的核心价值。
个性化排序。对用户进行画像,然后抽取特征项参与排序。你对风格、材质、价格、品牌等因素的偏好都会影响排序结果。(千人千面)
京东搜索系统架构图如下:
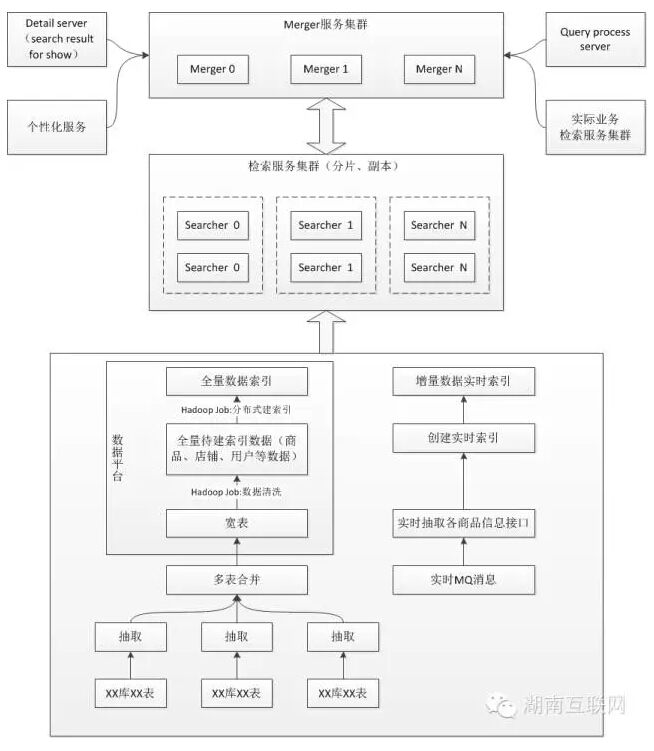
关键点解读:
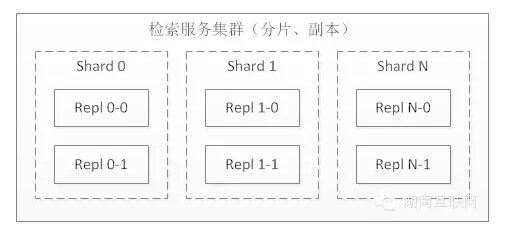
1)搜索分片、副本集
副本集:随着并发量越来越大,单机已不能胜任,可以考虑“横向扩展”(副本集)做负载均衡,提升整个搜索平台的并发能力。
分片:随着数据规模越来越大,单机的内存、计算资源吃紧,造成单次请求响应超时,可以考虑分片,将大索引切分成小索引,从而满足单机的性能。
将分片、副本集综合起来构建分布式搜索引擎,不管以后是搜索量增长还是数据量增长,都可以通过扩展来满足。
2)索引过程(全量索引、增量索引)
全量索引数据准备:上文提到“搜索系统中一条商品数据由商品基础信息、价格、库存、促销、评价等信息组成,这些数据都分布在不同的业务系统中”。为了便于索引处理,对多个系统的数据进行合并,生成商品宽表。然后在数据平台上对数据进行清洗,形成一份待全量索引数据。
全量索引:由于全量数据比较庞大,采用hadoop进行“并行”处理。其实全量索引重点就是分布式索引,简单方式可以根据一个数据切分规则,把数据分解成n块(n对应分片数),由不同的机器同时构建索引。如下图:
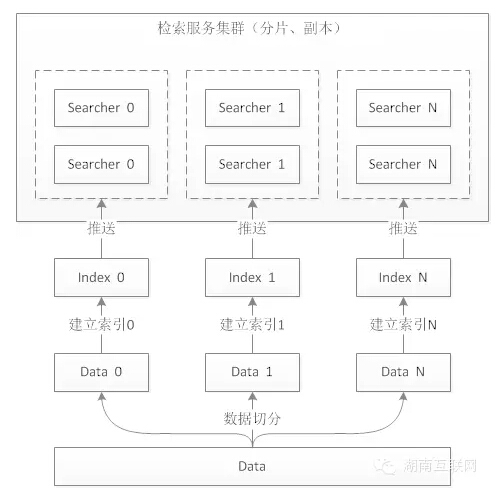
增量索引:接受MQ消息,然后实时调用各个业务接口建立索引。
3)检索
一个检索请求过来,先到merger,由merger将检索请求分发给各个searcher节点,searcher节点进行检索并返回结果给merger,然后merger进行合并排序,最后返回。
那么这里涉及两次排序,第一次是在searcher里面排序,第二次是在merger做合并排序。(排序后面具体再说)
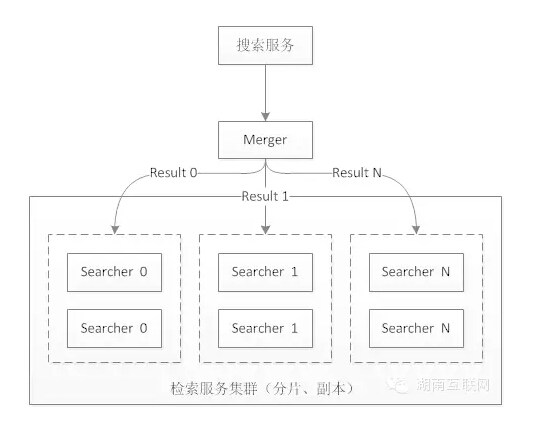
4)排序
上文提到一次搜索过程存在两次排序:search排序,merge排序。
searcher排序注重文本策略,这里主要包括文本域、价格、销量、好评等“商品综合分”排序。
merger排序根据多个结果集进行合并排序,主要包括:店铺多样性、品牌多样性、战略扶持品牌等业务规则。
各大电商公司的排序都不太一样,也会有“排序白皮书”供卖家进行参考,作为站内排序优化的参考书。
排序是电商搜索引擎的核心!
5)个性化搜索
个性化之前的搜索对于同一个查询,不同用户看到的结果是完全相同的。这可能并不符合所有用户的需求。在商品搜索中,这个问题尤为特出。因为商品搜索的用户可能特别青睐某些品牌、价格、店铺的商品,为了减少用户的筛选成本,需要对搜索结果按照用户进行个性化展示。
个性化的第一步是对用户和商品分别建模,第二步是将模型服务化。有了这两步之后,在用户进行查询时,merger同时调用用户模型服务和在线检索服务,用户模型服务返回用户维度特征,在线检索服务返回商品信息,排序模块运用这两部分数据对结果进行重排序,最后给用户返回个性化结果。
6)扩展搜索范围(Query Processer)
整合搜索用户在使用搜索时,其目的不仅仅是查找商品,还可能查询服务、活动等信息。为了满足这一类需求,首先在Query Processor中增加对应意图的识别。第二步是将服务、活动等一系列垂直搜索整合并服务化。一旦QP识别出这类查询意图,就条用整合服务,将对应的结果返回给用户。
7)其他
缓存设计(分级缓存)
Detail Server(补充展示字段)
以上内容整理自:
京东11.11 - 商品搜索系统架构设计

