



es有很多特性,分布式、副本集、负载均衡、容灾等。
我们先搭建一个很简单的分布式集群(伪),在同一机器上配置三个es,配置分别如下:
cluster.name: foxCluster node.name: "fox" cluster.name: foxCluster node.name: "fox2" transport.tcp.port: 9302 http.port: 9202 cluster.name: foxCluster node.name: "fox3" transport.tcp.port: 9303 http.port: 9203
加入一些数据先感受一下。
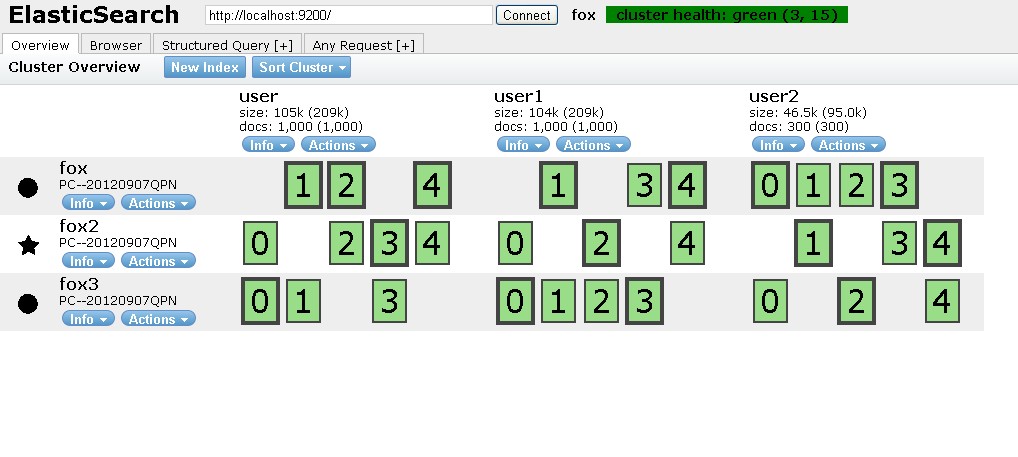
从图可知:
1)每个索引被分成了5个分片;
2)每个分片有一个副本;
3)5个分片基本均匀分布在3个dataNode上;
注意分片的边框(border)有粗有细,具体区别是:
粗边框代表:primary(true)
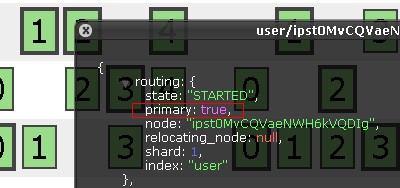
细边框代表:primary(false)
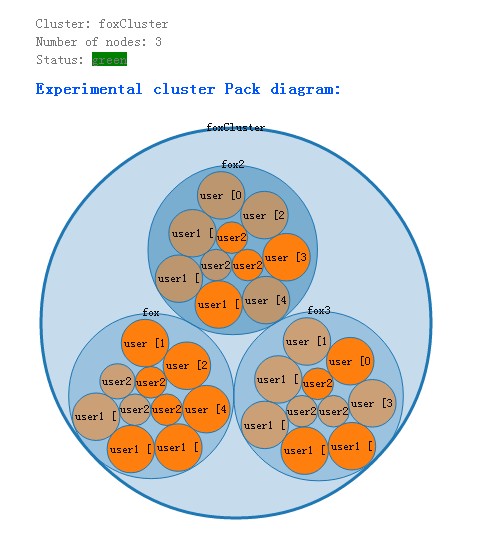
从bigdesk来看,也十分漂亮!
-------------------------------------------------
下面可以尝试关掉某个server,例如fox3。
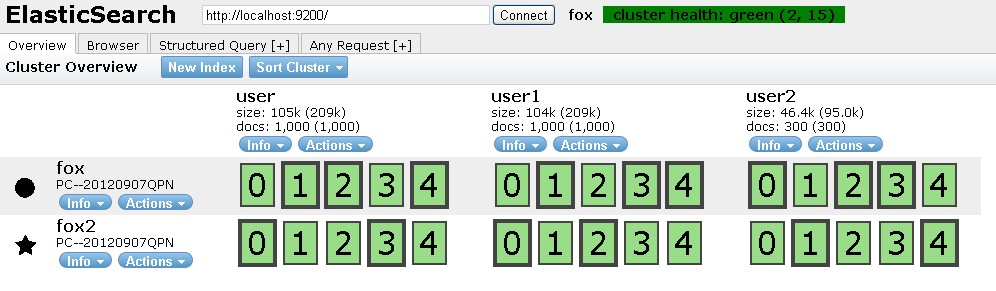
可以发现数据被“转移”了,起到了容灾的作用!
再重启fox3。在启动过程中,数据将重新分配给fox3。
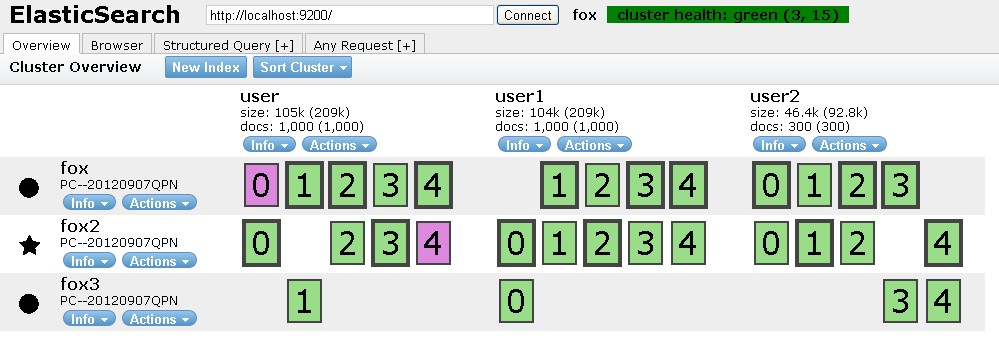
其中紫红色node为移动的数据块,完成转移后达到数据均匀分布的状态。
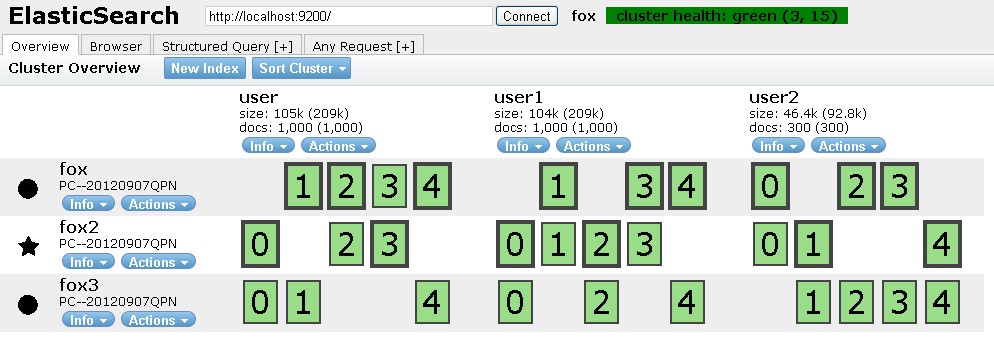
初步感觉es这块做得真心不错,以后要好好探索下他实现的原理。
-------------------------------------------------------
cluster
代表一个集群,集群中有多个节点,其中有一个为主节点,这个主节点是可以通过选举产生的,主从节点是对于集群内部来说的。es的一个概念就是去中心化,字面上理解就是无中心节点,这是对于集群外部来说的,因为从外部来看es集群,在逻辑上是个整体,你与任何一个节点的通信和与整个es集群通信是等价的。
shards
代表索引分片,es可以把一个完整的索引分成多个分片,这样的好处是可以把一个大的索引拆分成多个,分布到不同的节点上。构成分布式搜索。分片的数量只能在索引创建前指定,并且索引创建后不能更改。
replicas
代表索引副本,es可以设置多个索引的副本,副本的作用一是提高系统的容错性,当个某个节点某个分片损坏或丢失时可以从副本中恢复。二是提高es的查询效率,es会自动对搜索请求进行负载均衡。
recovery
代表数据恢复或叫数据重新分布,es在有节点加入或退出时会根据机器的负载对索引分片进行重新分配,挂掉的节点重新启动时也会进行数据恢复。
river
代表es的一个数据源,也是其它存储方式(如:数据库)同步数据到es的一个方法。它是以插件方式存在的一个es服务,通过读取river中的数据并把它索引到es中,官方的river有couchDB的,RabbitMQ的,Twitter的,Wikipedia的,river这个功能将会在后面的文件中重点说到。
gateway
代表es索引的持久化存储方式,es默认是先把索引存放到内存中,当内存满了时再持久化到硬盘。当这个es集群关闭再重新启动时就会从gateway中读取索引数据。es支持多种类型的gateway,有本地文件系统(默认),分布式文件系统,Hadoop的HDFS和amazon的s3云存储服务。
discovery.zen
代表es的自动发现节点机制,es是一个基于p2p的系统,它先通过广播寻找存在的节点,再通过多播协议来进行节点之间的通信,同时也支持点对点的交互。
Transport
代表es内部节点或集群与客户端的交互方式,默认内部是使用tcp协议进行交互,同时它支持http协议(json格式)、thrift、servlet、memcached、zeroMQ等的传输协议(通过插件方式集成)。
