



Viola Jones Face Detector
Viola Jones Face Detector是Paul viola 和 Michael J Jones共同提出的一种人脸检测框架。它极大的提高了人脸检测的速度和准确率。
- 速度提升方面:利用积分图像来提取图像特征值,所以非常快。同时,利用adaboost分类器的特征筛选特性,保留最有用特征,这也减少了检测时的运算复杂度。
- 准确率提升方面:将adaboost分类器进行改造,变成级联adaboost分类器,提高了人脸检测的准确率(降低漏检率和误检率)。
首先介绍几个术语:
检测率:存在人脸并且被检测出的图像在所有存在人脸图像中的比例。
漏检率:存在人脸但是没有检测出的图像在所有存在人脸图像中的比例。
误检率:不存在人脸但是检测出存在人脸的图像在所有不存在人脸图像中的比例。
FPR:false positive rate,假阳性率,即FP/(FP+TN),即所有不存在人脸图像被错分那一部分的比例,也就是误检率。
TPR:true positive rate,真阳性率,即TP/(TP+FN),即所有存在人脸图像被正确分类的那一部分的比例,也就是检测率。
整个步骤如下:
1.特征提取
论文中一共设计了四种特征,叫做haar-like feature分别是下面图1中的四种,后来的学者又设计了更丰富的类似特征,如图2。


这些特征都很简单,就是分别将白色和黑色区域中的所有像素相加,然后做差。例如图1中的A特征,首先计算两个区域像素和Sum(white),Sum(black).然后计算feature=Sum(white)-Sum(black)。但是考虑到多尺度问题,即利用不同大小的扫描窗口去检测不同大小的人脸,这个特征feature应该需要归一化。即最终特征:feature`=feature/pixel_num,pixel_num是黑色/白色区域的像素点个数。这样一来,即使扫描窗口的大小不一样,得到的人脸对应位置的特征值也能基本一致。另外,说一下为啥这个叫haar-like。因为在haar-wavelet中,haar基函数是下面这样一个东西。

想象一下,如果把这个一维函数,扩展成二维的,那上面的A特征不就是用一个二维的haar基函数与图像每个像素点相乘得到的吗?其他的特征,也可是看做haar基函数不同尺度的二维扩展。
接下来介绍积分图像(Integral Image),首先假设有一幅图像img,它的积分图像iimg的每个点(x,y)的值等于(0,0,x,y)所表示的矩形中img所有像素点的和。即:
 而积分图像iimg的计算很简单,时间复杂度为
而积分图像iimg的计算很简单,时间复杂度为![]() ,m,n分别是图像的长宽。计算完成iimg之后,如果我想要求任意矩形区域的像素和,就不再需要重复计算像素累计值,利用iimg即可,例如:计算(a,b,c,d)区域的sum值,用如下公式即可
,m,n分别是图像的长宽。计算完成iimg之后,如果我想要求任意矩形区域的像素和,就不再需要重复计算像素累计值,利用iimg即可,例如:计算(a,b,c,d)区域的sum值,用如下公式即可
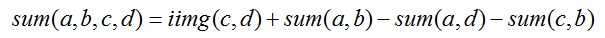
这样一来,上面所说的haar-like特征中需要计算的黑白区域的像素和只需要三次加减运算即可完成。因此,任何一维特征的提取只需要常数次运算。所以利用Integral Image可以很容易的计算上面所描述的特征。
最后,说说如何在一帧图像中提取这种特征。首先选定检测窗口的大小(这个可以是多尺度的,比如24*24,36*36等等),就拿24*24来说,利用这个窗口对整个图像进行滑动,每滑动到一个位置,就在窗口中提取一堆haar-like特征,至于在哪个位置提取什么尺寸的特征,论文中没有说明,这个挺符合微软研究院的风格的,他们很少给出完整的framework,不过后来也有很多学者对于这个问题进行了研究,所以这点不太重要。总而言之,按照论文里面说的,一个24*24的窗口,大概可以提取160000维特征。
同时,论文中也说了,上述的haar-like特征,虽然在表达能力上很弱,但是由于维数比较大,是overcomplete的,这也算是对其表达能力进行了补充。另外,为了检测不同尺寸的人脸,之前的检测系统通常是把输入图像做成图像金字塔(图像按照尺寸从大到小的一组),然后检测窗口大小不变。Viola-jones则相反,他们保持输入图像尺寸不变,让检测窗口的尺寸不断调整。因为窗口的调整比起图像的调整要方便的多,这也节省了大量的时间。
2. Adaboost分类器介绍
由于160000维特征也是个大数目,因此论文中假设,这些特征中只有一小部分是有用的,主要的问题就转化成了如何寻找这一小部分有用的特征。Adaboost分类器当然是一个非常合适的选择,因为这种分类器具有特征选择能力。Adaboost的原理就是构造一个由多个弱分类器并联成的强分类器,每个弱分类器都根据自己的准确率将自己的分类结果乘以权值,最后的输出是所有若分类器输出的加和。每个弱分类器的分类准确率可以很低,但是整个强分类器的准确率却会很高。有关adaboost分类器的具体公式和推导,可以参看我最后附的word文档,在此不作更详细的说明。
3. 级联Adaboost(cascade of classifiers)
然而,如果仅仅使用传统的adaboost分类器,还是太耗时了,假如我们仅保存前200维最有效的特征。那么对于检测窗口滑动到的每个位置,都需要提取200维特征,并且计算这200维特征输入到adaboost分类器中计算出的结果,这大概需要200次乘法和200次加法。考虑到检测窗口可以滑动到的位置以及不同尺度,检测算法的整体计算量还是比较大的。因此,论文对于adaboost分类器进行了创造性的改造,作者将若干个小的adaboost分类器级联起来,并且让每一级的分类器,都具有非常高的检测率(99.9%,接近100%),同时误检率也保持相当高(大概50%,即fpr)。那么,如果我们级联20个这样的小adaboost分类器,人脸的漏检率仅仅有:
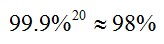
误检率仅仅有:
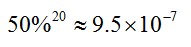
可见,这是一个准确率非常高的人脸检测器,同时,一旦在某一级分类器中,检测出不是人脸,人脸检测立刻终止。因为图片中有人脸的部分只占很小的比例,所以检测窗口在大部分位置和尺度上都可以很快就停止检测。这种人脸检测策略的速度比起上面所说的200个特征的原始adaboost分类器要快得多。(注意,每个小adaboost分类只有几维或几十维特征)
4. 如何训练cascade of classifiers
论文中给出了一种很简单但是很有效的方法。
1.用户选定每一层的最大可接受误检率f(maximum acceptable rate of fpr)和每一层的最小可接受的检测率d(minimum accpetable detection rate)
2.用户选择整体的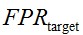
3.初始化:总体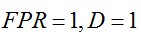 ,D指的是检测率,循环计数器i=0
,D指的是检测率,循环计数器i=0
4.循环:如果当前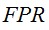 大于,继续添加一层adaboost分类器。
大于,继续添加一层adaboost分类器。
5.在训练当前层分类器时,如果目前该层的特征性能没有达到该层的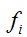 标准,则继续添加新的特征。添加新特征时,持续降低该特征的阈值,直到该层分类器的检测率
标准,则继续添加新的特征。添加新特征时,持续降低该特征的阈值,直到该层分类器的检测率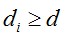 ,然后更新
,然后更新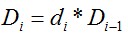
6.需要注意的是,每一级分类器使用的训练集中的负样本,都是上一级被错分的,即false positive,假阳性。这使得下一级分类器更加关注那些更难的(容易被错分的)样本。最后,如果检测到多个重叠的人脸位置,则将检测矩形框合并。
参考文献:
Robust Real-Time Face Detection,Paul Viola,Micheal J. Jones

