2017.08.10 Python爬虫实战之爬虫攻防篇
1.封锁user-agent破解:
user-agent是浏览器的身份标识,网站就是通过user-agent来确定浏览器类型的。有很多网站会拒绝不符合一定标准的user-agent请求网页,如果网站将频繁访问网站的user-agent作为爬虫的标志,然后加入黑名单该怎么办?
(1)首先在meiju项目下,settings.py的同级目录创建middlewares目录,进入middlewares目录,创建__init__.py,将middlewares目录变成一个Python模块
(2)创建资源文件resource.py和中间件文件customUserAgent.py:
(3)将多个浏览器的user-agent放入资源文件resource.py中加入列表待用:
#!/usr/bin/env python
#-*- coding: utf-8 -*-
UserAgents = [
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; Acoo Browser; SLCC1; .NET CLR 2.0.50727; Media Center PC 5.0; .NET CLR 3.0.04506)",
"Mozilla/4.0 (compatible; MSIE 7.0; AOL 9.5; AOLBuild 4337.35; Windows NT 5.1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US)",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)",
"Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)",
"Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)",
"Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0",
"Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5",
"Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.9.0.8) Gecko Fedora/1.9.0.8-1.fc10 Kazehakase/0.5.6",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/535.20 (KHTML, like Gecko) Chrome/19.0.1036.7 Safari/535.20",
"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; fr) Presto/2.9.168 Version/11.52",
]
(4)修改customUserAgent,将资源文件中的user-agent随机选择一个出来,作为Scrapy的user-agent。
#!/usr/bin/env python
#-*- coding: utf-8 -*-
from scrapy.contrib.downloadermiddleware.useragent import UserAgentMiddleware
from meiju100.middlewares.resource import UserAgents
import random
class RandomUserAgent(UserAgentMiddleware):
def process_request(self, request, spider):
ua=random.choice(UserAgents)
request.headers.setdefault('User-Agent',ua)
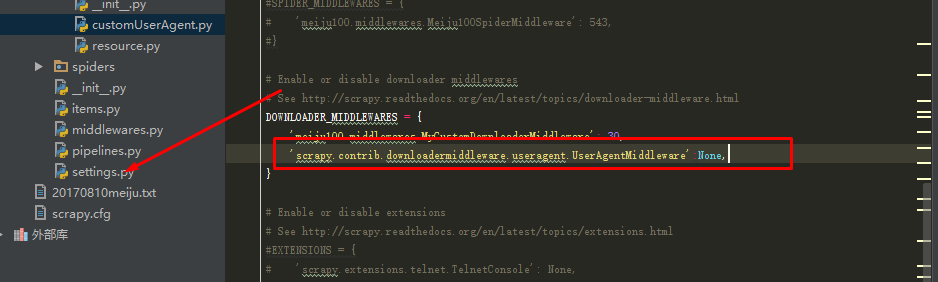
(5)最后修改settings.py文件,将RandomUserAgent加入DOWNLOADER_MIDDLEWARES
2.封锁IP破解:在反爬虫中,最容易被发觉的实际上是IP,同一IP短时间内访问同一站点,如果数量少,管理员可能会以为是网吧或者大型的局域网在访问,但是数目多了,很定就是爬虫了
解决这个难题的方法,就是准备一个代理池,从中随机选择一个代理使用:
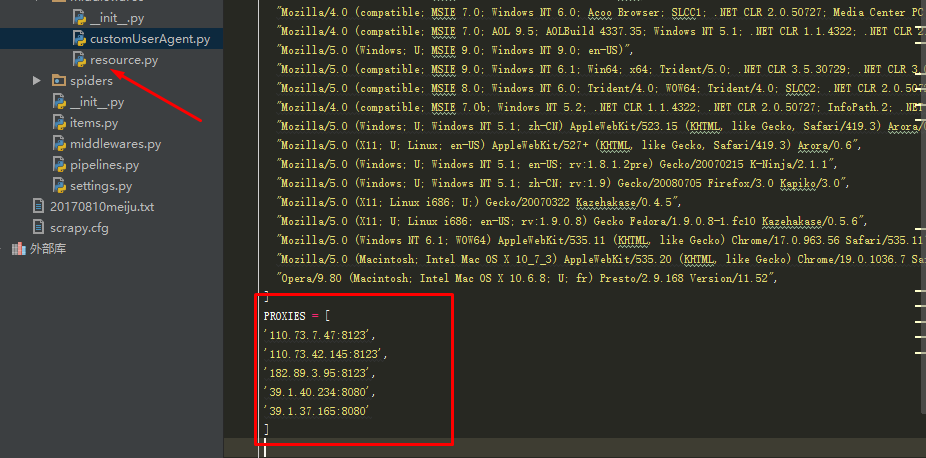
(1)在之前创建的middlewares目录中,在resource.py文件中加入一个IP池,也就是代理服务器的列表:
(2)创建一个中间件,customProxy.py,这个中间件的作用就是让Scrapy爬取网站时随机使用IP池中的代理:
#!/usr/bin/env python
#-*- coding: utf-8 -*-
import random
from meiju100.middlewares.resource import PROXIES
class RandomProxy(object):
def process_request(self,request,spider):
proxy=random.choice(PROXIES)
request.meta['proxy']='http://%s'%proxy
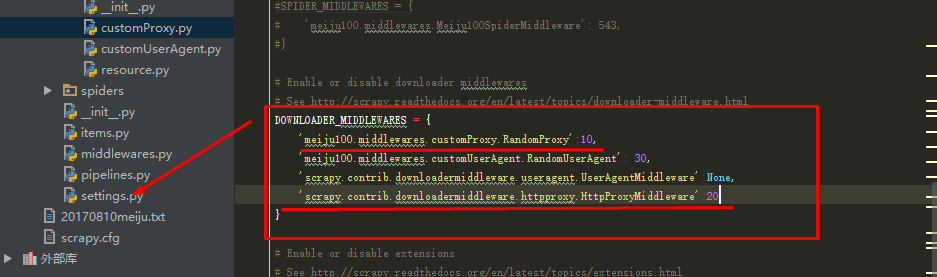
(3)最后修改settings.py文件,将customProxy加入到DOWNLOADER_MIDDLEWARES:
DOWNLOADER_MIDDLEWARES = {
'meiju100.middlewares.customProxy.RandomProxy':10,
'meiju100.middlewares.customUserAgent.RandomUserAgent': 30,
'scrapy.contrib.downloadermiddleware.useragent.UserAgentMiddleware':None,
'scrapy.contrib.downloadermiddleware.httpproxy.HttpProxyMiddleware':20
}
有些人之所以不断成长,就绝对是有一种坚持下去的力量。好读书,肯下功夫,不仅读,还做笔记。人要成长,必有原因,背后的努力与积累一定数倍于普通人。所以,关键还在于自己。

