

ElasticSearch核心知识 -- 索引过程
1、索引过程图解:
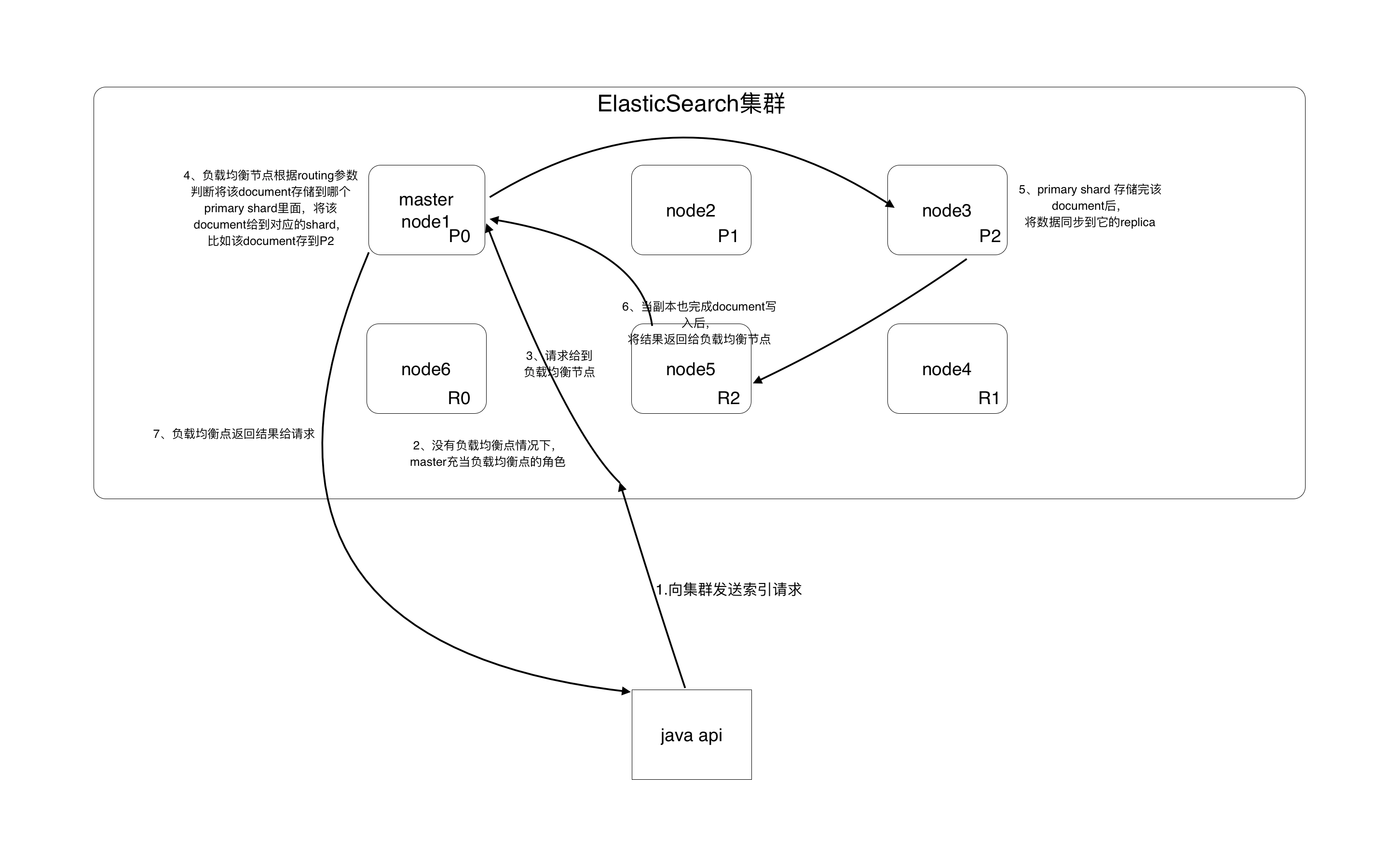
- api向集群发送索引请求,集群会使用负载均衡节点来处理该请求,如果没有单独的负载均衡点,master节点会充当负载均衡点的角色。
- 负载均衡节点根据routing参数来计算要将该索引存储到哪个primary shard上,然后将数据给到对应的shard。
- 对应的shard拿到数据后进行索引写入,写入成功后,将数据给到自己的replica shard。
- 当replica shard也将数据成功写入后,返回成功的结果到负载均衡节点。
- 此时负载均衡节点才认为数据写入成功,将成功索引的结果返回给请求的api
2、routing(路由)参数
2.1、routing参数的指定和计算原理
每个document存放在哪个shard上是由routing参数决定的,那这个参数的值是什么,ElasticSearch又是怎么通过该参数来确定存放在哪个shard上呢?
-
routing参数的默认值为_id,也可以进行手动指定routing参数,可以是值,也可以是某个字段:
PUT /index/type/id?routing=user_id { "user_id":"M9472323048", "name":"zhangsan", "age":54 } -
ElasticSearch有个哈希算法,通过 Hash(routing) % number_of_shards算得存储到哪个shard上面去,比如上面的语句,假设Hash("M9472323048") = 23,该index含有3个shard,则存储到 23 % 3 = 2,即P2上面。shard编号取值为0 number_of_shards - 1。
2.2、手动指定routing和自动routing的区别
routing的值默认为_id字段,_id可以保证在集群中唯一,但是有时候需要手动指定routing来优化后续的查询过程。因为routing确定,那就可以指定用哪个routing进行查询,缩减了目标结果集,减少了ElasticSearch集群的压力。
- 使用自动routing:
- 优点: 简单,可以很均衡的分配每个shard中的文档数量,做到负载均衡
- 缺点: 当查询一下复杂的数据时,需要到多个shard中查找,查询偏慢
- 使用手动routing:
- 优点: 查询时指定当初入库的routing进行查询,锁定shard,直达目标,查询速度快
- 缺点: 麻烦,要保证存储的均衡比较复杂
