

数据库优化实践【TSQL篇】
在前面我们介绍了如何正确使用索引,调整索引是见效最快的性能调优方法,但一般而言,调整索引只会提高查询性能。除此之外,我们还可以调整数据访问代码和TSQL,本文就介绍如何以最优的方法重构数据访问代码和TSQL。
第四步:将TSQL代码从应用程序迁移到数据库中
也许你不喜欢我的这个建议,你或你的团队可能已经有一个默认的潜规则,那就是使用ORM(Object Relational Mapping,即对象关系映射)生成所有SQL,并将SQL放在应用程序中,但如果你要优化数据访问性能,或需要调试应用程序性能问题,我建议你将SQL代码移植到数据库上(使用存储过程,视图,函数和触发器),原因如下:
1、使用存储过程,视图,函数和触发器实现应用程序中SQL代码的功能有助于减少应用程序中SQL复制的弊端,因为现在只在一个地方集中处理SQL,为以后的代码复用打下了良好的基础。
2、使用数据库对象实现所有的TSQL有助于分析TSQL的性能问题,同时有助于你集中管理TSQL代码。
3、将TS QL移植到数据库上去后,可以更好地重构TSQL代码,以利用数据库的高级索引特性。此外,应用程序中没了SQL代码也将更加简洁。
虽然这一步可能不会象前三步那样立竿见影,但做这一步的主要目的是为后面的优化步骤打下基础。如果在你的应用程序中使用ORM(如NHibernate)实现了数据访问例行程序,在测试或开发环境中你可能发现它们工作得很好,但在生产数据库上却可能遇到问题,这时你可能需要反思基于ORM的数据访问逻辑,利用TSQL对象实现数据访问例行程序是一种好办法,这样做有更多的机会从数据库角度来优化性能。
我向你保证,如果你花1-2人月来完成迁移,那以后肯定不止节约1-2人年的的成本。
OK!假设你已经照我的做的了,完全将TSQL迁移到数据库上去了,下面就进入正题吧!
第五步:识别低效TSQL,采用最佳实践重构和应用TSQL
由于每个程序员的能力和习惯都不一样,他们编写的TSQL可能风格各异,部分代码可能不是最佳实现,对于水平一般的程序员可能首先想到的是编写TSQL实现需求,至于性能问题日后再说,因此在开发和测试时可能发现不了问题。
也有一些人知道最佳实践,但在编写代码时由于种种原因没有采用最佳实践,等到用户发飙的那天才乖乖地重新埋头思考最佳实践。
我觉得还是有必要介绍一下具有都有哪些最佳实践。
1、在查询中不要使用“select *”
(1)检索不必要的列会带来额外的系统开销,有句话叫做“该省的则省”;
(2)数据库不能利用“覆盖索引”的优点,因此查询缓慢。
2、在select清单中避免不必要的列,在连接条件中避免不必要的表
(1)在select查询中如有不必要的列,会带来额外的系统开销,特别是LOB类型的列;
(2)在连接条件中包含不必要的表会强制数据库引擎检索和匹配不需要的数据,增加了查询执行时间。
3、不要在子查询中使用count()求和执行存在性检查
(1)不要使用
使用
代替;
(2)当你使用count()时,SQL Server不知道你要做的是存在性检查,它会计算所有匹配的值,要么会执行全表扫描,要么会扫描最小的非聚集索引;
(3)当你使用EXISTS时,SQL Server知道你要执行存在性检查,当它发现第一个匹配的值时,就会返回TRUE,并停止查询。类似的应用还有使用IN或ANY代替count()。
4、避免使用两个不同类型的列进行表的连接
(1)当连接两个不同类型的列时,其中一个列必须转换成另一个列的类型,级别低的会被转换成高级别的类型,转换操作会消耗一定的系统资源;
(2)如果你使用两个不同类型的列来连接表,其中一个列原本可以使用索引,但经过转换后,优化器就不会使用它的索引了。例如:
smalltable.float_column = large_table.int_column
在这个例子中,SQL Server会将int列转换为float类型,因为int比float类型的级别低,large_table.int_column上的索引就不会被使用,但smalltable.float_column上的索引可以正常使用。
5、避免死锁
(1)在你的存储过程和触发器中访问同一个表时总是以相同的顺序;
(2)事务应经可能地缩短,在一个事务中应尽可能减少涉及到的数据量;
(3)永远不要在事务中等待用户输入。
6、使用“基于规则的方法”而不是使用“程序化方法”编写TSQL
(1)数据库引擎专门为基于规则的SQL进行了优化,因此处理大型结果集时应尽量避免使用程序化的方法(使用游标或UDF[User Defined Functions]处理返回的结果集) ;
(2)如何摆脱程序化的SQL呢?有以下方法:
- 使用内联子查询替换用户定义函数;
- 使用相关联的子查询替换基于游标的代码;
- 如果确实需要程序化代码,至少应该使用表变量代替游标导航和处理结果集。
7、避免使用count(*)获得表的记录数
(1)为了获得表中的记录数,我们通常使用下面的SQL语句:
这条语句会执行全表扫描才能获得行数。
(2)但下面的SQL语句不会执行全表扫描一样可以获得行数:
WHERE id = OBJECT_ID('dbo.Orders') AND indid < 2
8、避免使用动态SQL
除非迫不得已,应尽量避免使用动态SQL,因为:
(1)动态SQL难以调试和故障诊断;
(2)如果用户向动态SQL提供了输入,那么可能存在SQL注入风险。
9、避免使用临时表
(1)除非却有需要,否则应尽量避免使用临时表,相反,可以使用表变量代替;
(2)大多数时候(99%),表变量驻扎在内存中,因此速度比临时表更快,临时表驻扎在TempDb数据库中,因此临时表上的操作需要跨数据库通信,速度自然慢。
10、使用全文搜索搜索文本数据,取代like搜索
全文搜索始终优于like搜索:
(1)全文搜索让你可以实现like不能完成的复杂搜索,如搜索一个单词或一个短语,搜索一个与另一个单词或短语相近的单词或短语,或者是搜索同义词;
(2)实现全文搜索比实现like搜索更容易(特别是复杂的搜索);
11、使用union实现or操作
(1)在查询中尽量不要使用or,使用union合并两个不同的查询结果集,这样查询性能会更好;
(2)如果不是必须要不同的结果集,使用union all效果会更好,因为它不会对结果集排序。
12、为大对象使用延迟加载策略
(1)在不同的表中存储大对象(如VARCHAR(MAX),Image,Text等),然后在主表中存储这些大对象的引用;
(2)在查询中检索所有主表数据,如果需要载入大对象,按需从大对象表中检索大对象。
13、使用VARCHAR(MAX),VARBINARY(MAX) 和 NVARCHAR(MAX)
(1)在SQL Server 2000中,一行的大小不能超过800字节,这是受SQL Server内部页面大小8KB的限制造成的,为了在单列中存储更多的数据,你需要使用TEXT,NTEXT或IMAGE数据类型(BLOB);
(2)这些和存储在相同表中的其它数据不一样,这些页面以B-Tree结构排列,这些数据不能作为存储过程或函数中的变量,也不能用于字符串函数,如REPLACE,CHARINDEX或SUBSTRING,大多数时候你必须使用READTEXT,WRITETEXT和UPDATETEXT;
(3)为了解决这个问题,在SQL Server 2005中增加了VARCHAR(MAX),VARBINARY(MAX) 和 NVARCHAR(MAX),这些数据类型可以容纳和BLOB相同数量的数据(2GB),和其它数据类型使用相同的数据页;
(4)当MAX数据类型中的数据超过8KB时,使用溢出页(在ROW_OVERFLOW分配单元中)指向源数据页,源数据页仍然在IN_ROW分配单元中。
14、在用户定义函数中使用下列最佳实践
不要在你的存储过程,触发器,函数和批处理中重复调用函数,例如,在许多时候,你需要获得字符串变量的长度,无论如何都不要重复调用LEN函数,只调用一次即可,将结果存储在一个变量中,以后就可以直接使用了。
15、在存储过程中使用下列最佳实践
(1)不要使用SP_xxx作为命名约定,它会导致额外的搜索,增加I/O(因为系统存储过程的名字就是以SP_开头的),同时这么做还会增加与系统存储过程名称冲突的几率;
(2)将Nocount设置为On避免额外的网络开销;
(3)当索引结构发生变化时,在EXECUTE语句中(第一次)使用WITH RECOMPILE子句,以便存储过程可以利用最新创建的索引;
(4)使用默认的参数值更易于调试。
16、在触发器中使用下列最佳实践
(1)最好不要使用触发器,触发一个触发器,执行一个触发器事件本身就是一个耗费资源的过程;
(2)如果能够使用约束实现的,尽量不要使用触发器;
(3)不要为不同的触发事件(Insert,Update和Delete)使用相同的触发器;
(4)不要在触发器中使用事务型代码。
17、在视图中使用下列最佳实践
(1)为重新使用复杂的TSQL块使用视图,并开启索引视图;
(2)如果你不想让用户意外修改表结构,使用视图时加上SCHEMABINDING选项;
(3)如果只从单个表中检索数据,就不需要使用视图了,如果在这种情况下使用视图反倒会增加系统开销,一般视图会涉及多个表时才有用。
18、在事务中使用下列最佳实践
(1)SQL Server 2005之前,在BEGIN TRANSACTION之后,每个子查询修改语句时,必须检查@@ERROR的值,如果值不等于0,那么最后的语句可能会导致一个错误,如果发生任何错误,事务必须回滚。从SQL Server 2005开始,Try..Catch..代码块可以处理TSQL中的事务,因此在事务型代码中最好加上Try…Catch…;
(2)避免使用嵌套事务,使用@@TRANCOUNT变量检查事务是否需要启动(为了避免嵌套事务);
(3)尽可能晚启动事务,提交和回滚事务要尽可能快,以减少资源锁定时间。
要完全列举最佳实践不是本文的初衷,当你了解了这些技巧后就应该拿来使用,否则了解了也没有价值。此外,你还需要评审和监视数据访问代码是否遵循下列标准和最佳实践。
如何分析和识别你的TSQL中改进的范围?
理想情况下,大家都想预防疾病,而不是等病发了去治疗。但实际上这个愿望根本无法实现,即使你的团队成员全都是专家级人物,我也知道你有进行评审,但代码仍然一团糟,因此需要知道如何治疗疾病一样重要。
首先需要知道如何诊断性能问题,诊断就得分析TSQL,找出瓶颈,然后重构,要找出瓶颈就得先学会分析执行计划。
理解查询执行计划
当你将SQL语句发给SQL Server引擎后,SQL Server首先要确定最合理的执行方法,查询优化器会使用很多信息,如数据分布统计,索引结构,元数据和其它信息,分析多种可能的执行计划,最后选择一个最佳的执行计划。
可以使用SQL Server Management Studio预览和分析执行计划,写好SQL语句后,点击SQL Server Management Studio上的评估执行计划按钮查看执行计划,如图1所示。
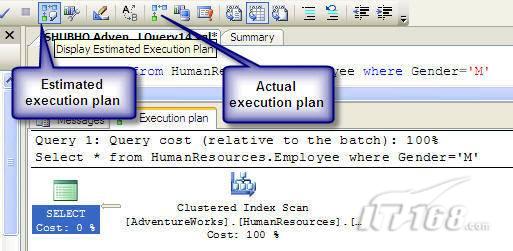
图 1 在Management Studio中评估执行计划
在执行计划图中的每个图标代表计划中的一个行为(操作),应从右到左阅读执行计划,每个行为都一个相对于总体执行成本(100%)的成本百分比。
在上面的执行计划图中,右边的那个图标表示在HumanResources表上的一个“聚集索引扫描”操作(阅读表中所有主键索引值),需要100%的总体查询执行成本,图中左边那个图标表示一个select操作,它只需要0%的总体查询执行成本。
下面是一些比较重要的图标及其对应的操作:
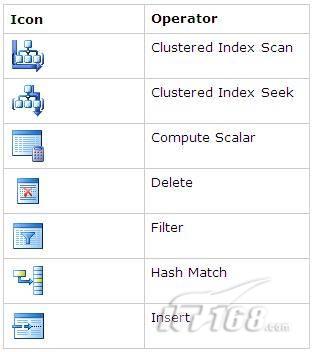
图 2 常见的重要图标及对应的操作
注意执行计划中的查询成本,如果说成本等于100%,那很可能在批处理中就只有这个查询,如果在一个查询窗口中有多个查询同时执行,那它们肯定有各自的成本百分比(小于100%)。
如果想知道执行计划中每个操作详细情况,将鼠标指针移到对应的图标上即可,你会看到类似于下面的这样一个窗口。
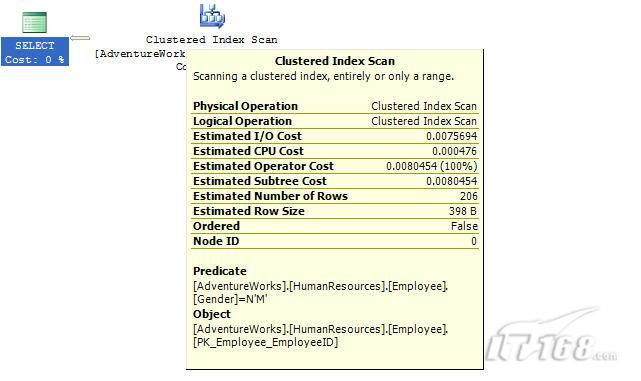
图 3 查看执行计划中行为(操作)的详细信息
这个窗口提供了详细的评估信息,上图显示了聚集索引扫描的详细信息,它要查找AdventureWorks数据库HumanResources方案下Employee表中 Gender = ‘M’的行,它也显示了评估的I/O,CPU成本。
查看执行计划时,我们应该获得什么信息
当你的查询很慢时,你就应该看看预估的执行计划(当然也可以查看真实的执行计划),找出耗时最多的操作,注意观察以下成本通常较高的操作:
1、表扫描(Table Scan)
当表没有聚集索引时就会发生,这时只要创建聚集索引或重整索引一般都可以解决问题。
2、聚集索引扫描(Clustered Index Scan)
有时可以认为等同于表扫描,当某列上的非聚集索引无效时会发生,这时只要创建一个非聚集索引就ok了。
3、哈希连接(Hash Join)
当连接两个表的列没有被索引时会发生,只需在这些列上创建索引即可。
4、嵌套循环(Nested Loops)
当非聚集索引不包括select查询清单的列时会发生,只需要创建覆盖索引问题即可解决。
5、RID查找(RID Lookup)
当你有一个非聚集索引,但相同的表上却没有聚集索引时会发生,此时数据库引擎会使用行ID查找真实的行,这时一个代价高的操作,这时只要在该表上创建聚集索引即可。
TSQL重构真实的故事
只有解决了实际的问题后,知识才转变为价值。当我们检查应用程序性能时,发现一个存储过程比我们预期的执行得慢得多,在生产数据库中检索一个月的销售数据居然要50秒,下面就是这个存储过程的执行语句:
exec uspGetSalesInfoForDateRange ‘1/1/2009’, 31/12/2009,’Cap’
Tom受命来优化这个存储过程,下面是这个存储过程的代码:
@startYear DateTime,
@endYear DateTime,
@keyword nvarchar(50)
AS
BEGIN
SET NOCOUNT ON;
SELECT
Name,
ProductNumber,
ProductRates.CurrentProductRate Rate,
ProductRates.CurrentDiscount Discount,
OrderQty Qty,
dbo.ufnGetLineTotal(SalesOrderDetailID) Total,
OrderDate,
DetailedDescription
FROM
Products INNER JOIN OrderDetails
ON Products.ProductID = OrderDetails.ProductID
INNER JOIN Orders
ON Orders.SalesOrderID = OrderDetails.SalesOrderID
INNER JOIN ProductRates
ON
Products.ProductID = ProductRates.ProductID
WHERE
OrderDate between @startYear and @endYear
AND
(
ProductName LIKE '' + @keyword + ' %' OR
ProductName LIKE '% ' + @keyword + ' ' + '%' OR
ProductName LIKE '% ' + @keyword + '%' OR
Keyword LIKE '' + @keyword + ' %' OR
Keyword LIKE '% ' + @keyword + ' ' + '%' OR
Keyword LIKE '% ' + @keyword + '%'
)
ORDER BY
ProductName
END
GO
分析索引
首先,Tom想到了审查这个存储过程使用到的表的索引,很快他发现下面两列的索引无故丢失了:
OrderDetails.ProductID
OrderDetails.SalesOrderID
他在这两个列上创建了非聚集索引,然后再执行存储过程:
exec uspGetSalesInfoForDateRange ‘1/1/2009’, 31/12/2009 with recompile
性能有所改变,但仍然低于预期(这次花了35秒),注意这里的with recompile子句告诉SQL Server引擎重新编译存储过程,重新生成执行计划,以利用新创建的索引。
分析查询执行计划
Tom接下来查看了SQL Server Management Studio中的执行计划,通过分析,他找到了某些重要的线索:
1、发生了一次表扫描,即使该表已经正确设置了索引,而表扫描占据了总体查询执行时间的30%;
2、发生了一个嵌套循环连接。
Tom想知道是否有索引碎片,因为所有索引配置都是正确的,通过TSQL他知道了有两个索引都产生了碎片,很快他重组了这两个索引,于是表扫描消失了,现在执行存储过程的时间减少到25秒了。
为了消除嵌套循环连接,他又在表上创建了覆盖索引,时间进一步减少到23秒。
实施最佳实践
Tom发现有个UDF有问题,代码如下:
(
@SalesOrderDetailID int
)
RETURNS money
AS
BEGIN
DECLARE @CurrentProductRate money
DECLARE @CurrentDiscount money
DECLARE @Qty int
SELECT
@CurrentProductRate = ProductRates.CurrentProductRate,
@CurrentDiscount = ProductRates.CurrentDiscount,
@Qty = OrderQty
FROM
ProductRates INNER JOIN OrderDetails ON
OrderDetails.ProductID = ProductRates.ProductID
WHERE
OrderDetails.SalesOrderDetailID = @SalesOrderDetailID
RETURN (@CurrentProductRate-@CurrentDiscount)*@Qty
END
在计算订单总金额时看起来代码很程序化,Tom决定在UDF的SQL中使用内联SQL。
dbo.ufnGetLineTotal(SalesOrderDetailID) Total -- 旧代码
(CurrentProductRate-CurrentDiscount)*OrderQty Total -- 新代码
执行时间一下子减少到14秒了。
在select查询清单中放弃不必要的Text列
为了进一步提升性能,Tom决定检查一下select查询清单中使用的列,很快他发现有一个Products.DetailedDescription列是Text类型,通过对应用程序代码的走查,Tom发现其实这一列的数据并不会立即用到,于是他将这一列从select查询清单中取消掉,时间一下子从14秒减少到6秒,于是Tom决定使用一个存储过程应用延迟加载策略加载这个Text列。
最后Tom还是不死心,认为6秒也无法接受,于是他再次仔细检查了SQL代码,他发现了一个like子句,经过反复研究他认为这个like搜索完全可以用全文搜索替换,最后他用全文搜索替换了like搜索,时间一下子降低到1秒,至此Tom认为调优应该暂时结束了。
小结
看起来我们介绍了好多种优化数据访问的技巧,但大家要知道优化数据访问是一个无止境的过程,同样大家要相信一个信念,无论你的系统多么庞大,多么复杂,只要灵活运用我们所介绍的这些技巧,你一样可以驯服它们。下一篇将介绍高级索引和反范式化。

