

MapReduce执行过程简要总结
宏观上MapReduce可以分为以下三个阶段,如下图1所示。
阶段1:input/map/partition/sort/spill
阶段2:mapper端merge
阶段3:reducer端merge/reduce/output

图1 MapReduce执行过程
以下分别对上述三个阶段详解。首先是Mapper端的执行逻辑,主要包含以下三点,如图2所示:
1. 将key/value/Partition写入到内存缓冲区中
2. 当缓冲区使用量达到一定阀值,将其spill到disk上,spill前,需要进行排序
3. 排序时先按照Partition进行排序,再按照key进行排序,默认排序算法是快速排序。
注意: 在内存中进行排序时,数据本身不用移动,仅对索引排序即可
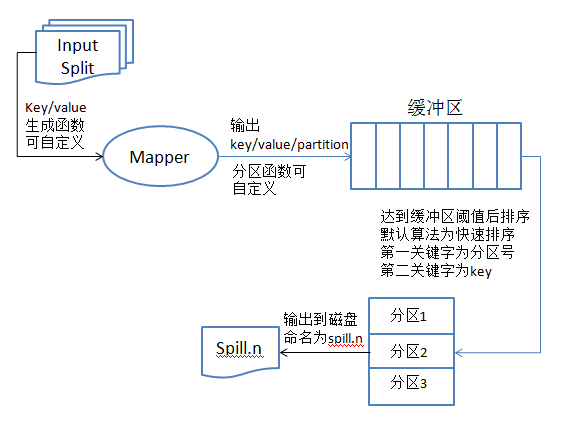
图2 Mapper端逻辑
接下来是Map端的归并实现,主要包含以下两点,如图3所示。
1.对生成的多个spill文件,进行归并排序
2.最终归并成一个大文件
注意:
1. 由于每一个spill文件都是按分区和key排序好的,所以归并完的文件也是按分区和key排序好的。
2.在进行归并的时候,不是一次性的把所有的spill文件归并成一个大文件。而是部分spill文件归并成中间文件,然后中间文件和剩下的spill文件再进行归并。
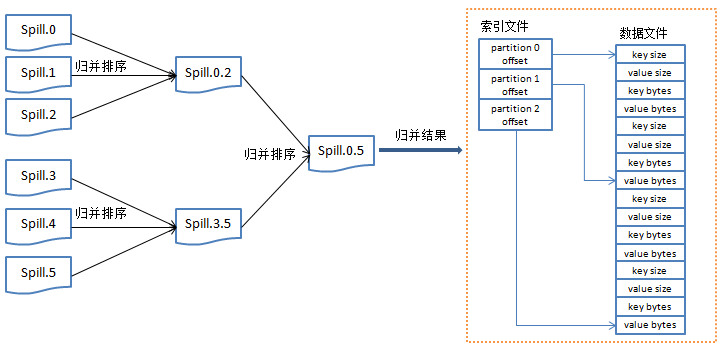
图3 Map端Merge
最后是Reducer端的Merge和Reduce,主要包含以下三点,如图4所示:
1. 当有新的MapTask事件完成时,拷贝线程从指定的机器上面拷贝数据
2. 当数据拷贝的时候,分两种情况,当数据量小的时候就会写入内存当中,当数据量大的时候就会写入硬盘当中
3. 来自不同的机器的多个数据文件,需要归并成一个文件.在拷贝文件过程中会进行文件归并操作.
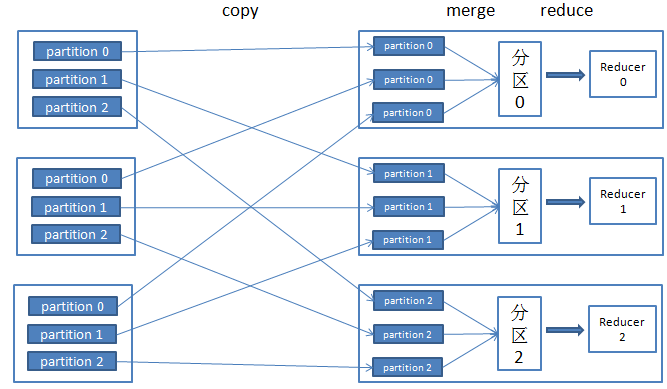
图4 Reducer端Merge和Reduce
转载请注明出处。
