Day5- Python基础5 模块导入、time、datetime、random、os、sys、hashlib、json&pickle
本节目录:
1.模块的分类
2.模块的导入
3.time模块
4.datetime模块
5.random
6.os模块
7.sys模块
8.hashlib
9.json&pickle
一、模块的分类
Python流行的一个原因就是因为它的第三方模块数量巨大,我们编写代码不必从零开始重新造轮子,许多要用的功能都已经写好封装成库了,我们只要直接调用即可,模块分为内建模块、自定义的模块、安装的第三方的模块,一般都放在不同的地方,下面来看一下内建模块怎么导入,以及他们存放的位置。
import sys # 可以用import 直接导入内建模块
for i in sys.path: # sys.path存放有每次导入模块都会去搜寻的路径
print(i)
'''
D:\pycharm2018\S3\s3基础\day9
D:\pycharm2018\S3 #自定义模块放在当前工作空间
F:\BaiduNetdiskDownload\python3.5.2\python35.zip
F:\BaiduNetdiskDownload\python3.5.2\DLLs
F:\BaiduNetdiskDownload\python3.5.2\lib #内建模块存放位置
F:\BaiduNetdiskDownload\python3.5.2
F:\BaiduNetdiskDownload\python3.5.2\lib\site-packages #第三方库的安装位置
'''
#可以向sys.path中用append()的方法导入,例如 sys.path.append('D:')后,在D:目录下的py文件可以用import直接导入
print(sys.platform) # win32 sys.platform可以获取当前工作平台(win32)or linux
#此外 sys.argv可以获取脚本的参数,argv[0] 是脚本名,argv[1]是第一个参数...
2.模块的导入
首先要说明下,自己定义的模块的名字和内建模块的名字不要相同,否则的话,导入的时候会出现问题,内建的模块,和第三方模块已经存在sys.path的路径中,所以直接导入即可,下面来说明下自己写了一个项目,项目中的各个库是如何导入的,假设我定义了一个modules的项目,下面是其目录结构看如何在1.py文件导入
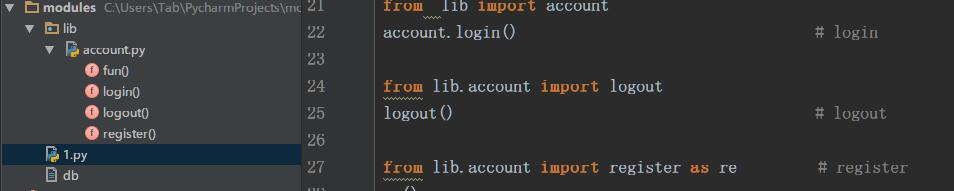
上图左边是目录树,右边是在1.py文件中如何导入在lib/account.py下定义的函数,列举了三种常用导入方式。
[1]:import多次为什么只导入一次?
在sys.modules记录着呢
3.time模块
time差不多有8,9种的方法,可能很多,但是我们要记住一个基本的规则是什么。
时间戳
1:时间戳 就是一个秒数 他是从1970 1月1日0点开始算 到现在一共经历了多少秒 1970年他是Unix诞生 >>> time.time() 1520587685.2926712 给我们的意义就是做计算用的 计算经历了多长时间,你不用这个time.time 用什么?
结构化时间
2:结构化时间 time.localtime 本地的时间对象 time.gmtime utc的时间对象 以英国格林尼治时间化分24个时区,一个时区15° 1°是15分钟 我们东八区与utc时间相差8小时 >>> time.localtime() time.struct_time(tm_year=2018, tm_mon=3, tm_mday=9, tm_hour=17, tm_min=33, tm_se c=9, tm_wday=4, tm_yday=68, tm_isdst=0) struct_time里面的每一个值都具有他特殊的意义: tm_wday 一周的周几 周一对应0 tm_yday 一年的多少天 给我们的意义就是我们可以对这个时间对象,取得到任意你想要的值。 >>> t = time.localtime() >>> t.tm_year 2018 >>> t.tm_wday 4
字符串时间
把时间戳或者结构化时间,变成我们直观可以接受的
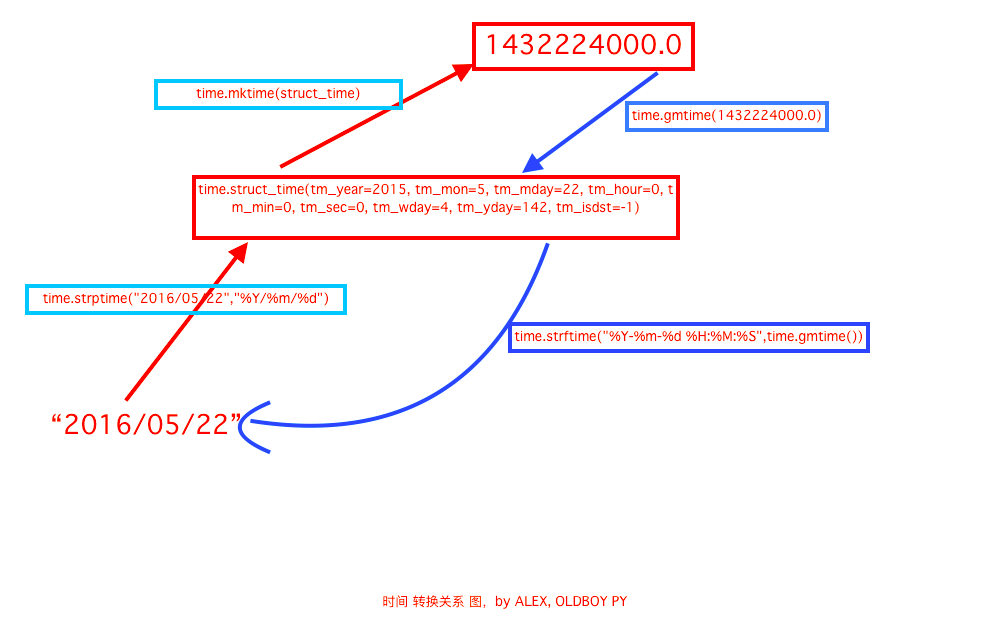
import time #时间戳与结构化时间之间的互换 #时间戳转成结构化时间 print(time.localtime(123456)) #本地时间 (UCT) print(time.gmtime(123456)) #标准时间 #结构化时间转成时间戳,必须传一个结构化时间的做参数 print(time.mktime(time.localtime())) #执行结果: time.struct_time(tm_year=1970, tm_mon=1, tm_mday=2, tm_hour=18, tm_min=17, tm_sec=36, tm_wday=4, tm_yday=2, tm_isdst=0) time.struct_time(tm_year=1970, tm_mon=1, tm_mday=2, tm_hour=10, tm_min=17, tm_sec=36, tm_wday=4, tm_yday=2, tm_isdst=0) 1493193977.0 #结构化时间与字符串时间之间的转换 #结构化时间转成字符串时间 print(time.strftime('%Y-%m-%d %X',time.localtime()))#time.localtime()不写默认是当前时间 print(time.strftime('%Y-%m-%d %X',time.localtime(123456))) #字符串时间转换成结构化时间 print(time.strptime('2017-4-21','%Y-%m-%d')) #字符串时间转成结构化时间 可以先查看下方法 #执行结果: 2017-04-26 16:06:17 1970-01-02 18:17:36 time.struct_time(tm_year=2017, tm_mon=4, tm_mday=21, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=4, tm_yday=111, tm_isdst=-1)
你要是嫌麻烦,不想自己转成字符串时间,可以使用time.asctime() 或time.ctime()
>>> time.asctime() ##他的默认参数就是一个结构化时间 'Fri Mar 9 18:07:04 2018' >>> time.ctime() ##他的默认参数是一个时间戳 'Fri Mar 9 18:11:17 2018' >>> time.ctime(23) ##在上面的转化没有,涉及到时间戳和字符串的转化,你可以采用这个 'Thu Jan 1 08:00:23 1970' >>> ##他们的参数不一样,但是最后都是字符串
其他的方法:
time.sleep(1) #参数秒,睡多少秒
4.datetime模块 (没啥好说的)
import datetime print(datetime.datetime.now()) ##这个会比time的asctime 和 ctime 好看多了 ##2018-03-09 18:17:39.286773
其他的一些使用:
import datetime
print(datetime.datetime.now()) # 2016-05-17 15:46:40.784376 获取当前的日期和时间
print(datetime.datetime.now()+datetime.timedelta(days=10)) # 2016-05-27 15:47:45.702528 将当前的时间向后推迟10天
print(datetime.date.today()) # 2016-05-17 获取当前的日期
print(datetime.datetime.utcnow()) # 2016-05-17 08:23:41.150628 获取格林威治时间
print(datetime.datetime.now().timetuple()) # time.struct_time(tm_year=2016 ... tm_hour=16,...)获取当前一个包含当前时间的结构体
print(datetime.datetime.now().timestamp()) # 1463473711.057878 获取当前的时间戳
print((datetime.datetime.fromtimestamp(1463473711.057878))) # 2016-05-17 16:28:31.057878 将时间戳转换成日期和时间
print(datetime.datetime.strptime('2016-05-17 16:28:31','%Y-%m-%d %H:%M:%S')) #2016-05-17 16:28:31 str转换为datetime
print(datetime.datetime.now().strftime('%D, %m %d %H:%M')) #05/23/16, 05 23 10:10 datetime转换为str
5.random模块
import random ret = random.random() ##随机输出 0 -1 之间的浮点数 ret = random.randint(1,3) ##[1-3]之间随机输出 为整数 ret = random.randrange(1,3) ## 和range(1,3)一样,顾头不顾尾 ret = random.choice([11,33,44]) ##从【11,33,44】这三个数字随机取出一个 各占百分之33的概率 ret = random.uniform(1,3) ##随机随机从1-3之间的浮点数 item =[1,3,4,5,6] print(random.shuffle(item),item) ##输出 None [1, 6, 4, 5, 3] 打乱序列里面的值,场景,如打扑克牌 打乱排序 print(ret)
练习:4个验证码 数字和字母组合
import random
def v_code():
ret = ""
for i in range(0,5):
num = random.randint(0,9) ##随机0-9
alf = chr(random.randint(65,122))
s = str(random.choice([num,alf]))
ret += s
return ret
print(v_code())
输出:
a2049
6.os模块
os模块是与操作系统交互的一个接口
os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径
os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd
os.curdir 返回当前目录: ('.')
os.pardir 获取当前目录的父目录字符串名:('..')
os.makedirs('dirname1/dirname2') 可生成多层递归目录
os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推
os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirname
os.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname
os.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
os.remove() 删除一个文件
os.rename("oldname","newname") 重命名文件/目录
os.stat('path/filename') 获取文件/目录信息
os.sep 输出操作系统特定的路径分隔符,win下为"\\",Linux下为"/"
os.linesep 输出当前平台使用的行终止符,win下为"\t\n",Linux下为"\n"
os.pathsep 输出用于分割文件路径的字符串
os.name 输出字符串指示当前使用平台。win->'nt'; Linux->'posix'
os.system("bash command") 运行shell命令,直接显示
os.environ 获取系统环境变量
os.path.abspath(path) 返回path规范化的绝对路径
os.path.split(path) 将path分割成目录和文件名二元组返回
os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素
os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素
os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False
os.path.isabs(path) 如果path是绝对路径,返回True
os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False
os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False
os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
os.path.getatime(path) 返回path所指向的文件或者目录的最后存取时间
os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
7.sys模块
修改环境变量的两种:
临时修改:
import sys
sys.path.append("d:\\") ###这里修改的是临时的
print(sys.path)
'''
['D:\\pycharm2018\\S3\\s3基础\\day9',
'D:\\pycharm2018\\S3',
'F:\\BaiduNetdiskDownload\\python3.5.2\\python35.zip',
'F:\\BaiduNetdiskDownload\\python3.5.2\\DLLs',
'F:\\BaiduNetdiskDownload\\python3.5.2\\lib',
'F:\\BaiduNetdiskDownload\\python3.5.2',
'F:\\BaiduNetdiskDownload\\python3.5.2\\lib\\site-packages',
'd:\\']
'''
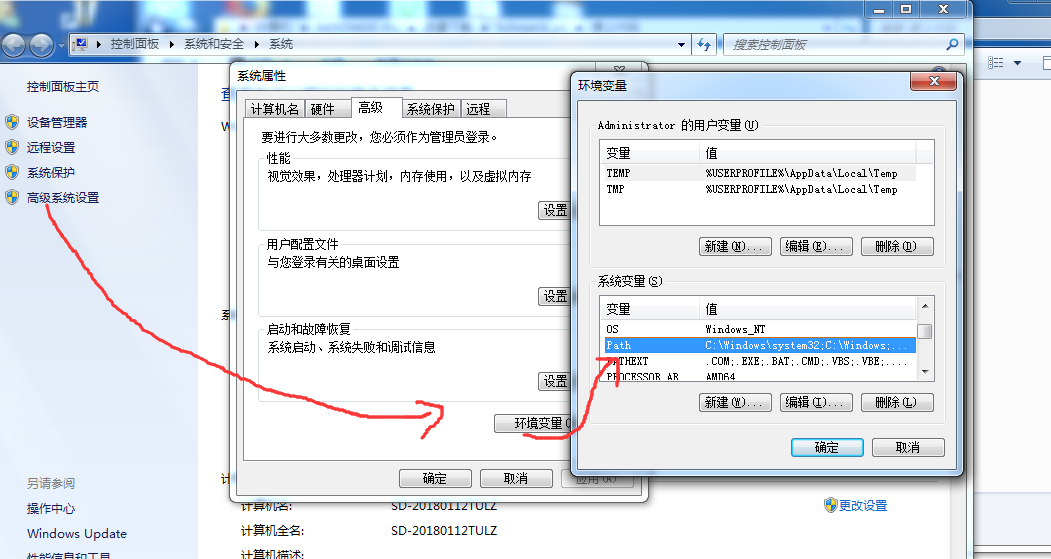
永久修改:
点击我的电脑--右键属性--》点击高级属性设置--》点击环境变量--》找到path 将要添加的路径加入 用英文的; 进行分隔
sys.argv 命令行参数List,第一个元素是程序本身路径 sys.exit(n) 退出程序,正常退出时exit(0) sys.version 获取Python解释程序的版本信息 sys.maxint 最大的Int值 sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值 sys.platform 返回操作系统平台名称
练习进度条:
import sys,time
for i in range(10):
sys.stdout.write('#')
time.sleep(1)
sys.stdout.flush()
8.摘要算法:hashlib模块
摘要算法又称哈希算法、散列算法。它通过一个函数,把任意长度的数据转换为一个长度固定的数据串(通常用16进制的字符串表示)。
摘要算法就是通过摘要函数f()对任意长度的数据data计算出固定长度的摘要digest,目的是为了发现原始数据是否被人篡改过。
摘要算法之所以能指出数据是否被篡改过,就是因为摘要函数是一个单向函数,计算f(data)很容易,但通过digest反推data却非常困难。而且,对原始数据做一个bit的修改,都会导致计算出的摘要完全不同。
MD5是最常见的摘要算法,速度很快,生成结果是固定的128 bit字节,通常用一个32位的16进制字符串表示。
注意:操作的是byte字节数据,如果是字符串str 则需要先转成字节 byte。
md5()方法
m = hashlib.md5()
m.update('hello'.encode('utf-8')) #字节数据
print(m.hexdigest()) #16进制的摘要算法结果
import hashlib # md5 = hashlib.md5() #调用md5算法 md5.update(b'hello') #对字节格式的文件进行摘要算法计算 print(md5.hexdigest()) #打印算法结果 'hello' #5d41402abc4b2a76b9719d911017c592 md5.update(b'world') #对字节格式的文件进行摘要算法计算 作用的字节是'helloworld'将上一次的加入到当前文本前 print(md5.hexdigest()) #打印算法结果。 #fc5e038d38a57032085441e7fe7010b0
#假设大文件为helloworld,最后得出的结果与上边最后打印的world一致。可以认为摘要算法有自动叠加的功能! import hashlib md5 = hashlib.md5() #调用md5算法 md5.update(b'helloworld') # print(md5.hexdigest()) #打印算法结果 与上边执行的摘要算法结果一致。 #fc5e038d38a57032085441e7fe7010b0
应用于:文件校验:大文件分块校验,防止文件过大导致的效率问题,最终传递的结果一样。
另一种常见的摘要算法是SHA1,调用SHA1和调用MD5完全类似:
import hashlib sha1 = hashlib.sha1() sha1.update('how to use sha1 in ') sha1.update('python hashlib?') print sha1.hexdigest()
SHA1的结果是160 bit字节,通常用一个40位的16进制字符串表示。比SHA1更安全的算法是SHA256和SHA512,不过越安全的算法越慢,而且摘要长度更长。
注意点:给md5加盐:
hashlib.md5("salt".encode("utf8"))
9.json & pickle 模块
用于序列化的两个模块
- json,用于字符串 和 python数据类型间进行转换
- pickle,用于python特有的类型 和 python的数据类型间进行转换
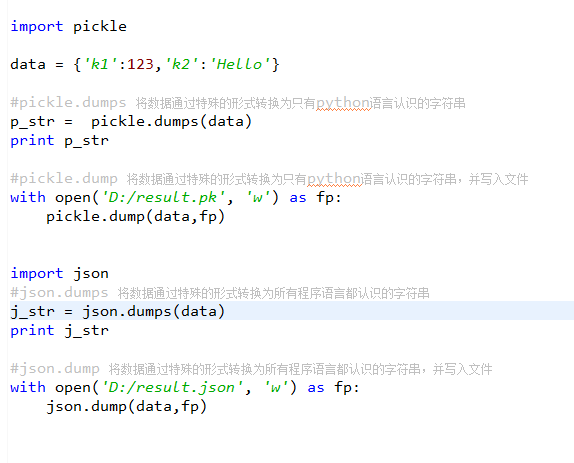
Json模块提供了四个功能:dumps、dump、loads、load
pickle模块提供了四个功能:dumps、dump、loads、load
pickle模块提供了四个功能:dumps、dump(序列化,存)、loads(反序列化,读)、load (不仅可以序列化字典,列表...可以把python中任意的数据类型序列化)
注意的是:
这时候机智的你又要说了,既然pickle如此强大,为什么还要学json呢?
这里我们要说明一下,json是一种所有的语言都可以识别的数据结构。
如果我们将一个字典或者序列化成了一个json存在文件里,那么java代码或者js代码也可以拿来用。
但是如果我们用pickle进行序列化,其他语言就不能读懂这是什么了~
所以,如果你序列化的内容是列表或者字典,我们非常推荐你使用json模块
但如果出于某种原因你不得不序列化其他的数据类型,而未来你还会用python对这个数据进行反序列化的话,那么就可以使用pickle
