


『TensorFlow』梯度优化相关
tf.trainable_variables可以得到整个模型中所有trainable=True的Variable,也是自由处理梯度的基础
基础梯度操作方法:
tf.gradients
用来计算导数。该函数的定义如下所示
def gradients(ys,
xs,
grad_ys=None,
name="gradients",
colocate_gradients_with_ops=False,
gate_gradients=False,
aggregation_method=None):
虽然可选参数很多,但是最常使用的还是ys和xs。根据说明得知,ys和xs都可以是一个tensor或者tensor列表。而计算完成以后,该函数会返回一个长为len(xs)的tensor列表,列表中的每个tensor是ys中每个值对xs[i]求导之和。如果用数学公式表示的话,那么 g = tf.gradients(y,x)可以表示成 ,
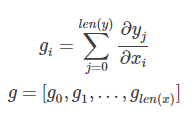
tf.clip_by_global_norm
修正梯度值,用于控制梯度爆炸的问题。梯度爆炸和梯度弥散的原因一样,都是因为链式法则求导的关系,导致梯度的指数级衰减。为了避免梯度爆炸,需要对梯度进行修剪。
先来看这个函数的定义:
def clip_by_global_norm(t_list, clip_norm, use_norm=None, name=None):
输入参数中:t_list为待修剪的张量, clip_norm 表示修剪比例(clipping ratio).
函数返回2个参数: list_clipped,修剪后的张量,以及global_norm,一个中间计算量。当然如果你之前已经计算出了global_norm值,你可以在use_norm选项直接指定global_norm的值。
那么具体如何计算呢?根据源码中的说明,可以得到
list_clipped[i]=t_list[i] * clip_norm / max(global_norm, clip_norm),
其中 global_norm = sqrt(sum([l2norm(t)**2 for t in t_list]))
可以写作
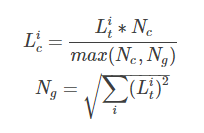
其中,
Lic和Lig代表t_list[i]和list_clipped[i],
Nc和Ng代表clip_norm 和 global_norm的值。
其实也可以看到其实Ng就是t_list的L2模。上式也可以进一步写作
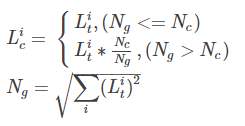
也就是说,当t_list的L2模大于指定的Nc时,就会对t_list做等比例缩放。
这里讲解一下具体应用于优化器的方法,
self._lr = tf.Variable(0.0, trainable=False) # lr 指的是 learning_rate
tvars = tf.trainable_variables()
grads, _ = tf.clip_by_global_norm(tf.gradients(cost, tvars),
config.max_grad_norm)
# 梯度下降优化,指定学习速率
optimizer = tf.train.GradientDescentOptimizer(self._lr)
# optimizer = tf.train.AdamOptimizer()
# optimizer = tf.train.GradientDescentOptimizer(0.5)
self._train_op = optimizer.apply_gradients(zip(grads, tvars)) # 将梯度应用于变量
# self._train_op = optimizer.minimize(grads)
优化器类处理法:
提取梯度,使用梯度优化变量,效果和上面的例子相同,
# 创建一个optimizer. opt = GradientDescentOptimizer(learning_rate=0.1) # 计算<list of variables>相关的梯度 grads_and_vars = opt.compute_gradients(loss, <list of variables>) # grads_and_vars为tuples (gradient, variable)组成的列表。 #对梯度进行想要的处理,比如cap处理 capped_grads_and_vars = [(MyCapper(gv[0]), gv[1]) for gv in grads_and_vars] # 令optimizer运用capped的梯度(gradients) opt.apply_gradients(capped_grads_and_vars)

