


『TensorFlow』迁移学习
完全版见github:TransforLearning
零、迁移学习
将一个领域的已经成熟的知识应用到其他的场景中称为迁移学习。用神经网络的角度来表述,就是一层层网络中每个节点的权重从一个训练好的网络迁移到一个全新的网络里,而不是从头开始,为每特定的个任务训练一个神经网络。
假设你已经有了一个可以高精确度分辨猫和狗的深度神经网络,你之后想训练一个能够分别不同品种的狗的图片模型,你需要做的不是从头训练那些用来分辨直线,锐角的神经网络的前几层,而是利用训练好的网络,提取初级特征,之后只训练最后几层神经元,让其可以分辨狗的品种。节省资源是迁移学习最大意义之一,举图像识别中最常见的例子,训练一个神经网络。来识别不同的品种的猫,你若是从头开始训练,你需要百万级的带标注数据,海量的显卡资源。而若是使用迁移学习,你可以使用Google发布的Inception或VGG16这样成熟的物品分类的网络,只训练最后的softmax层,你只需要几千张图片,使用普通的CPU就能完成,而且模型的准确性不差。
使用迁徙学习时要注意,本来预训练的神经网络要和当前的任务差距不大,不然迁徙学习的效果会很差。例如如果你要训练一个神经网络来识别肺部X光片中是否包含肿瘤,那么使用VGG16的网络就不如使用一个已训练好的判断脑部是否包含肿瘤的神经网络。后者与当前的任务有相似的场景,很多底层的神经员可以做相同的事,而用来识别日常生活中照片的网络,则难以从X光片中提取有效的特征。
另一种迁移学习的方法是对整个网络进行微调(fine turing),假设你已训练好了识别猫品种的神经网络,你的网络能对50种猫按品种进行分类。接下来你想对网络进行升级,让其能够识别100种猫,这时你不应该只训练网络的最后一层,而应该逐层对网络中每个节点的权重进行微调。显然,只训练最后几层,是迁移学习最简单的1.0版,而对节点权重进行微调,就是更难的2.0版,通过将其他层的权重固定,只训练一层这样的逐层训练,可以更好的完成上述任务。
迁移方式和数据集规模关系
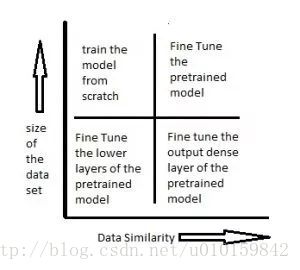
1)右下角场景,待训练的数据集较小,已训练的模型和当前任务相似。此时可以只是重新训练已有模型的靠近输出的几层,例如将ImageNet中输出层原来可以判别一万种输出的网络改的只能判别猫的品种,从而利用已有网络来做低层次的特征提取。
2)左下角场景,待训练的数据集较小,已训练的模型和当前任务场景差距较大。例如你有的已训练网络能识别出白天高速路上的违章车辆,你需要训练一个能识别出夜间违章车辆的模型,由于不管白天夜晚,交通规则是没有变化的,所以你需要将网络靠近输入的那几层重新训练,等到新的网络能够提取出夜间车辆的基本信息后,就可以借用已有的,在大数据集下训练好的神经网络来识别违章车辆,而不用等夜间违章的车辆的照片积累的足够多之后再重新训练。
3)左上角场景,待训练的数据集较大,已有的模型和新模型的数据差异度很高。此时应该做的是从头开始,重新训练。
4)右上角场景,待训练的数据集较大,已有模型的训练数据和现有的训练数据类似。此时应该使用原网络的结构微调。
一、实验目的
使用google已经训练好的模型,将最后的全连接层修改为我们自己的全连接层,将原有的1000分类分类器修改为我们自己的5分类分类器,利用原有模型的特征提取能力实现我们自己数据对应模型的快速训练。实际中对于一个陌生的数据集,原有模型经过不高的迭代次数即可获得很好的准确率。
二、代码实战
实机文件夹如下:
花朵图片数据下载:
curl -O http://download.tensorflow.org/example_images/flower_photos.tgz
已经训练好的Inception-v3的1000分类模型下载:
wget https://storage.googleapis.com/download.tensorflow.org/models/inception_dec_2015.zip
迁移学习代码以及使用指南见github,本次的代码可以将新保存的模型迁移到自己的数据集上,并对自己的数据进行预测。
新添加的测试部分,直接运行TransferLearning_reload.py即可,输出如下,

第二行白字的五个值对应第一行的5个分类的概率。
三、问题&建议
1.建议从main函数开始阅读,跳到哪里读到那里;
2.我给的注释很详尽,原书《TensorFlow实战Google深度学习框架》也有更为详尽的注释,所以这里不多说了
之前本部分对输入图片的过程进行了分析,当时水平有限,现在看来很幼稚,实际上分析一下图上节点即可了解:
- InceptionV3接受二进制数据即可自行解码,即接收open().read()的二进制流即可
- 保存的模型文件Graph包含了InceptionV3和新的classer,但是两者是隔离的,这是由于程序中并没将两者联通,是先把InceptionV3的瓶颈张量feed出来,然后是用这个数组去feed新的classer,但是由于saver、InceptionV3、classer使用的sess是同一个,所以最终两者都保存在了model模型中
