中文乱码问题
通过举一个小例子,来记录一下如何排查get和post请求中的乱码问题。
一、举例
我们在idea中创建一个动态的web工程,并在项目中创建一个register.jsp文件。
<%@ page contentType="text/html;charset=UTF-8" language="java" pageEncoding="UTF-8" %>
<html>
<body>
<form action="show.jsp" method="post">
账号: <input type="text" name="name"> <br>
密码: <input type="text" name="password"> <br>
<input type="submit" value="登录">
</form>
</body>
</html>
<%@ page contentType="text/html;charset=UTF-8" language="java" %>
<html>
<head>
<title>展示</title>
</head>
<body>
<%
request.setCharacterEncoding("utf-8");
String name = request.getParameter("name");
String password = request.getParameter("password");
%>
<%
out.println(name);
out.print(password);
%>
</body>
</html>
注:这里使用jsp是为了举例更加简单。
访问这个register.jsp
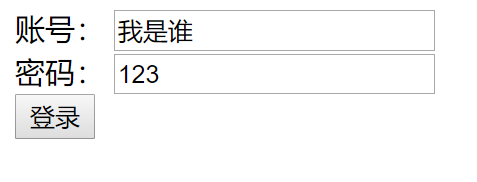
浏览器显示:

可以观察到这里可以观察到中文是正常显示的。
二、乱码的排查
如果在从请求到响应的过程中出现了乱码问题。该如何排查呢?
这里全部以UTF-8来举例,也推荐使用UTF-8编码
首先检查IDE工具的编码
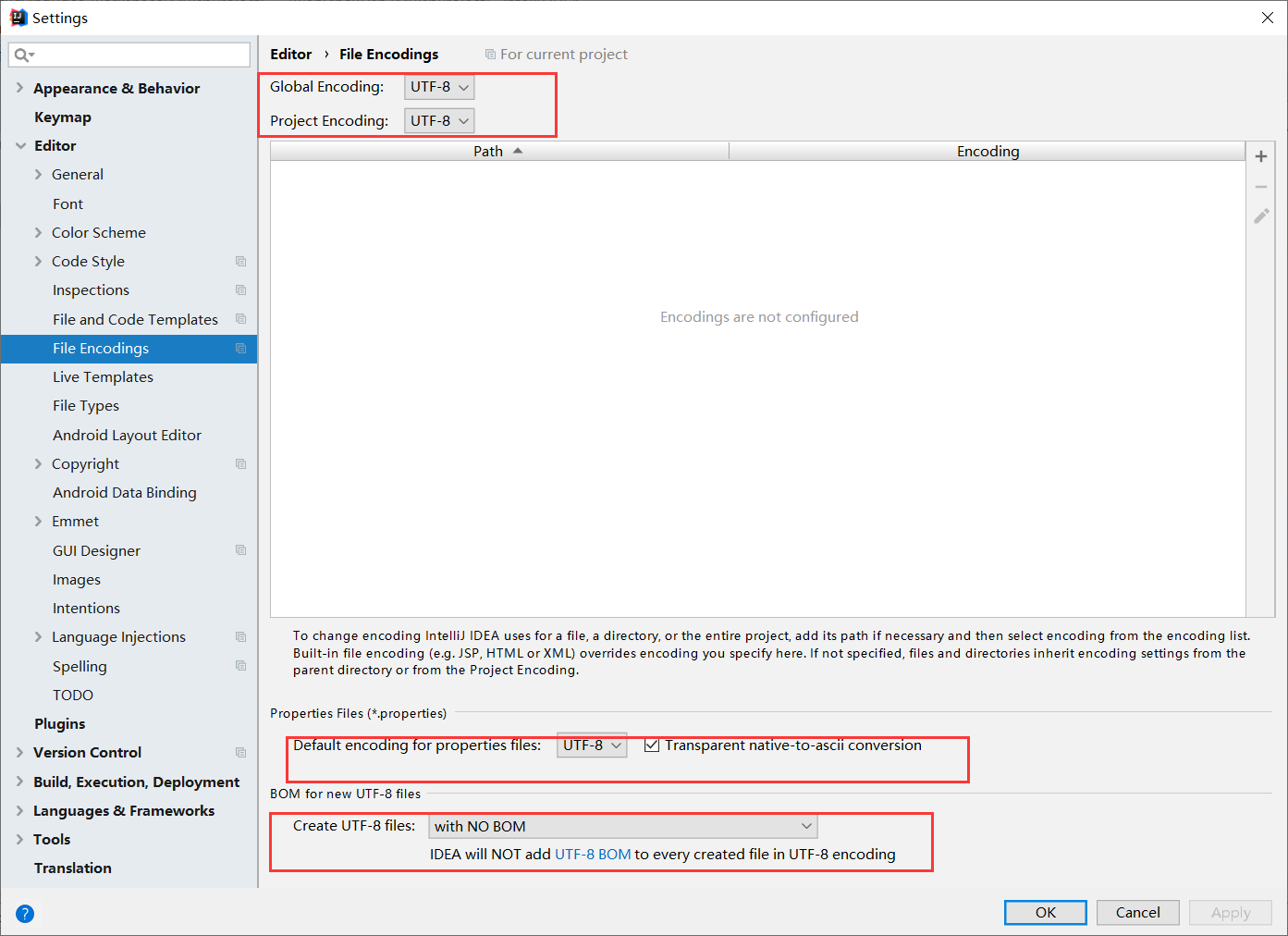
这样就将idea中文件的编码方式改成了utf-8,这里有一些注意的地方:对于进行设置之前创建的其他格式的文件,其编码格式还是保留原格式。
检查jsp代码中的编码设置
<%@ page contentType="text/html;charset=UTF-8" language="java" pageEncoding="UTF-8" %>
其中charset=UTF-8是就是告诉浏览器以UTF-8进行编码;
pageEncoding="UTF-8"如果jsp文件中出现了中文,这些中文使用UTF-8进行编码,这里最好与ide工具的问件编码格式保持一致。
区分请求方式是post还是get
- 在
tomcat7及以前, 默认编码设置是ISO-8859-1
<Connector port="8080" protocol="HTTP/1.1" connectionTimeout="20000" redirectPort="8443" />
可以在后面添加URIEncoding="UTF-8"来将tomcat对于请求以UTF-8的编码格式进行处理。
tomcat8以后,默认编码设置是utf-8,不需要再做额外的处理,只对get请求有效。
我们推荐使用上面的方式来解决get请求乱码的问题,但是还可以这样做
String name = request.getParameter("name");
name = new String(name.getBytes("iso-8859-1"),"utf-8");
String password = request.getParameter("password");
%>
既然已经知道tomcat7之前是使用iso-8859-1l来进行编码,我们可以先进行解码,再重新编码。
byte[] bytes= name.getBytes("ISO-8859-1");
name = new String(bytes,"UTF-8");
上面两句等价于
request.setCharacterEncoding("UTF-8");
这一句加在获取请求参数之前。
讲完请求乱码,我们再来看看响应乱码
public class HelloServlet extends HttpServlet{
public void doGet(HttpServletRequest request, HttpServletResponse response){
try {
PrintWriter pw= response.getWriter();
pw.println("你好");
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
此时将响应输出到浏览器发生了中文乱码,为什么会发生乱码呢,乱码的原因就是编码和解码不一致。
tomcat默认对输出流进行ISO-8859-1编码,浏览器如何解析呢?
如果未经特别设置,浏览器采用的是操作系统默认编码,即GBK或者GBK2312,此时发生乱码就在所难免。如何做?
response.setContentType("text/html; charset=UTF-8");
PrintWriter pw= response.getWriter();
pw.println("你好");
// 在获取输出流之前,加这一句,这句话有两个作用:①告诉浏览器采用UTF-8格式进行解码。②告诉tomcat采用utf-8编码
总结
在编码中,前端、后端、数据库以及各个角落存在着编码格式的设置,我们需要注意保持编码格式的统一,一般就不会在出现中文乱码的问题了。
你所看得到的天才不过是在你看不到的时候还在努力罢了!

