
除了L2正则化和dropout正则化,还有几种方法可以减少神经网络中的过拟合。
1. 数据增强
假设你正在训练一个猫咪图片的分类器,如果你想通过扩增数据集(即收集更多的数据)来解决过拟合,这种方法是可行的,但是扩增训练数据代价高,而且有时候我们很难收集到更多的数据。但是我们可以通过添加这类图片来增加训练集,比如说水平翻转图片,并把它添加入训练集。通过水平翻转图片,训练集大小可以增大一倍。我们还可随机裁剪图片,比如将原图片旋转并随意放大后裁剪。

对于光学字符识别,我们还可以通过添加数字随意旋转或扭曲来扩增数据,如下图:

因此,数据增强可以作为正则化方法使用。
2. early stopping
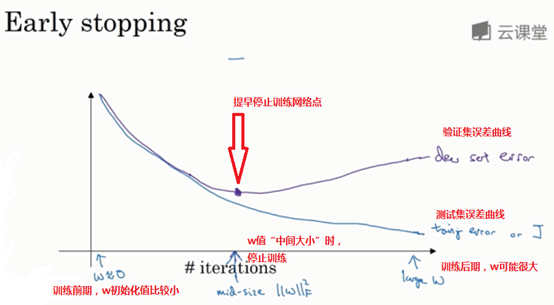
另外一种解决过拟合的方法是early stopping,即提早结束训练神经网络。
运行梯度下降时,我们绘制出训练误差和验证集误差。验证集误差可以是验证集上的分类误差,或验证集上的代价函数,逻辑损失和对数损失。你会发现,验证集误差通常会先呈下降趋势,然后在某个节点处开始上升。Early stopping的是当验证集误差减少到最小时,就停止训练。
为什么early stopping可以起作用?
当你刚开始训练神经网络时,参数w接近0,这是因为一般都将w随机初始化到一个比较小接近于0的值,所以你在长期训练神经网络之前,w依然很小。在迭代的过程中,w的值会变得越来越大,在后期,w的值可能很大。所以early stopping要做的就是在中间点停止迭代过程,我们得到一个中等大小的w值。与L2正则化相似,选择参数W范数值较小的神经网络,一般情况下可以使得神经网络过拟合不严重。
Early stopping的缺点
机器学习的过程包括几个步骤,其中一步就是选择一个算法来优化代价函数J,比如可以用梯度下降或者Momentum等来实现,但是优化代价函数J之后,我们也不想发生过拟合,因此会加上L2正则化和数据增强等方法来减少过拟合。Early stopping的缺点就是,你不能独立地处理这两个问题,因为提早停止梯度下降,也就是停止了优化代价函数J,因为现在你不再尝试降低代价函数J,所以代价函数J的值可能不够小,同时,你又希望不出现过拟合,你没有采取不同的方法来解决这两个问题,而是用一种方法同时解决两个问题,这样做的结果就是,要考虑的东西更复杂了。
如果不用early stopping,另一种方法就是L2正则化,训练神经网络神经网络的时间就可能很长,这会导致超参数搜索空间更容易分解,也更容易搜索,但是缺点就是你必须尝试很多正则化参数λ的值,这也导致搜索大量λ值的计算代价太高。
Early stopping的优点就是只运行一下梯度下降,你可以找出w的较小值,中间值和较大值,而无需尝试L2正则化超参数λ的很多值

