
Dropout为什么有正则化的作用?
下面来直观理解一下。
上面讲到,dropout每次迭代都会让一部分神经元失活,这样使得神经网络会比原始的神经网络规模变小,因此采用一个较小神经网络好像和使用正则化的效果是一样的。
第二个直观认识是
我们从单个神经元入手,这个单元的工作就是输入并生成一些有意义的输出,通过dropout,该单元的输入被随机地消除,因此该神经元不能只依靠任何一个特征(即输入),因为每个特征都有可能被随机清除,或者说该神经元的输入可能被随机清除,因此不会把所有赌注都放在一个输出上,不愿意给任何一个输入加上太多权重,因为它(输入)可能会被删除。因此该单元将通过这种方式积极地传播开,并为单元的四个输入只赋予一点权重。通过传播所有权重,dropout将产生收缩权重的平方范数的效果。和我们之前讲过的L2正则化类似,实施dropout的结果是它会压缩权重,并完成一些预防过拟合的外层正则化。事实证明,dropout被真实地作为一种正则化的替代方式,但是L2正则化对不同权重衰减是不同的,它取决于倍增的激活函数的大小。

总结一下,dropout的功能类似于L2正则化,与L2正则化不同的是,被应用的方式不同。Dropout也会有不同,甚至更适用于不同的输入范围。
实施dropout的另外一个细节是,下面是一个拥有三个输入特征的网络,其中一个要选择的参数是keep_prob,不同层的keep_prob也可以变化。比如说第一层,矩阵W[1]大小是3x7,第二个权重矩阵大小是7x7,等等。W[2]是最大的权重矩阵,因为W[2]拥有最大的参数集,即7x7,为了预防矩阵的过拟合,那么对于这一层,我们可以将该层的keep_prob的值设置的低一些,比如说0.5,对于其他层,过拟合的程度可能没那么严重,它们的keep_prob值可能高一些,如0.7,如果在某一层,我们不担心其存在过拟合的情况,那么keep_prob值可以设置为1。下图中紫色框出的小数即为每一层的keep_prob值。注意keep_prob值是1的话,那么意味着保留所有单元,即不在这一层使用dropout。
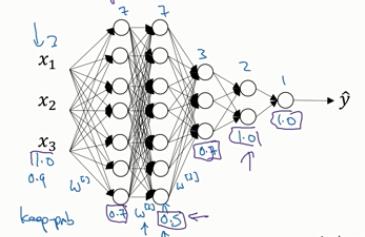
从技术上讲,我们也可以对输入层应用dropout,我们有机会删除一个或者多个输入特征,虽然现实中我们通常不这样做。
总结一下,如果你担心某些层比其他层更容易发生过拟合,可以把某些层的keep_prob值设置得比其他层更低,缺点是需要使用交叉验证,你要搜索更多的超参数;另一种方案是在一些层上应用dropout,而有些层不使用dropout,应用dropout的层只有一个超参数,即keep_prob。
下面分享两个实施过程中的技巧
实施dropout,在计算机视觉领域有很多成功的第一次,计算机视觉中输入量非常大,输入太多像素,以至于没有足够的数据,所以dropout在计算机视觉中应用得比较频繁。但要牢记的一点是,dropout是一种正则化方法,它有助于预防过拟合,因此,除非算法过拟合,不然一般不用dropout,因此一般用在计算机视觉领域,因为我们没有足够的数据,所以会造成过拟合。
Dropout的一大缺点就是代价函数J不再被明确定义(造成每次迭代损失函数值可能不会总体上单调递减),每次迭代,都会随机移除一些节点,如果再三检查梯度下降的性能,实际上很难进行复查。因此,一般是在调试前,先将keep_prob设置为1,先训练一遍,确保损失J是不断下降的,保证网络本身没问题之后,再设置合适的keep_prob值,再进行训练。
内容主要来自与:
Andrew Ng的改善深层神经网络:超参数调试、正则化以及优化课程

