ASCII到Unicode到UTF-8
1、很久以前使用的是ASCII;只有一个字节,也就是2的8次方,可以表示256个不同状态,电脑最初起源于美国,够用了,刚开始只是使用了127位,后来后面的部分被他们用来表示一些横线字符之类的128-255的扩展字符集。
2、后来传入中国,中国汉字太多了,ASCII不够用,中国人就不承认扩展字符集了,而是使用组合的方式把大于127的两个编码字符连在一起也就是两个ASCII编码合起来表示一个汉字(GBK标准)。再后来中国又不够用了,就在规定不需要表示汉字的两个字符都是属于扩展字符集的,只要第一个字符是大于127的就行,就说明他是汉字(GB18030标准)。----所以一个汉字是两个英文字符那么大。
半角全角之分:127位及之前的是半角,之后的是全角。
3、后来像中国这样子的国家太多了,大家一人一个标准,所以需要进行统一了,那就是使用国际化标准组织(ISO)规范的unicode编码。Unicode使用两个字节来表示一个字符。就算是半角的那些英文们也是一样的,虽然他们只需要使用的低八位(把他们的高八位填零了)。
4、再后来,不幸的是unicode也超了,所以人家的解决办法是使用两个unicode编码来表示一个。
Eg:"\uD83D\uDE02\uD83D\uDE02\uD83D\uDE02".length() // 6
这个字符串表示的是三个”笑哭“(博客园打不出来)的表情,但是却是使用了六个unicode代码单元.
那么utf-8(每次传输的时候传8位) 和utf-16(每次传输的时候传16位)呢?
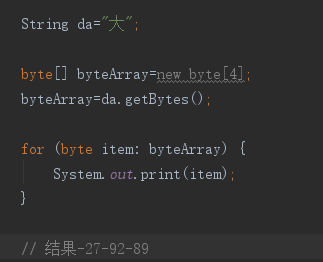
这个是编码规则,从unicode到utf-8以及utf-16并不是一一对应,而是需要用一定的规则进行转换。因为很多英文文件,他们的高八位几乎是0,那他们的文件凭空被扩大了一倍甚至更多,那不是很吃亏。一个字符现如今使用unicode来表示,他们需要的是一个unicode代码单元或者是一对代码单元,因此他们就需要使用两个字节或者是四个字节。而utf-8是每次传输的时候传输8位,他们是对unicode字符集进行再编码,编码之后的将一个unicode码位编码为1到4个字节。如果是英文就只需要一个字节,如果是辅助字符需要四个字节特别需要注意的是中文现在在utf-8中是需要3个字节(如下图)。而在utf-16中需要4个字节。目前国际上使用最广的是utf-8.