
基于Hadoop分布式集群YARN模式下的TensorFlowOnSpark平台搭建
1. 介绍
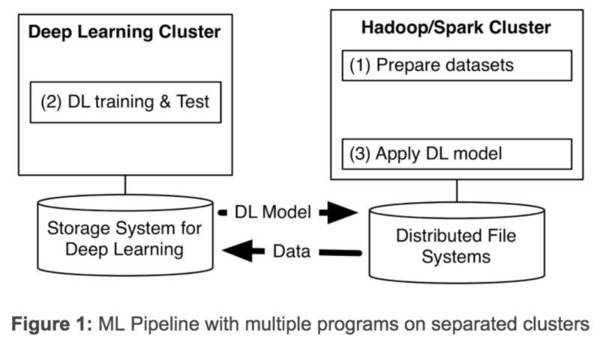
在过去几年中,神经网络已经有了很壮观的进展,现在他们几乎已经是图像识别和自动翻译领域中最强者[1]。为了从海量数据中获得洞察力,需要部署分布式深度学习。现有的DL框架通常需要为深度学习设置单独的集群,迫使我们为机器学习流程创建多个程序(见Figure 1)。拥有独立的集群需要我们在它们之间传递大型数据集,从而引起不必要的系统复杂性和端到端的学习延迟。
TensorFlow是Google公司刚刚发布不久一款用于数值计算和神经网络的深度学习框架。
TensorFlowOnSpark是yahoo今年刚开源的一个项目,目的就是充分发掘TensorFlow在现有的大数据集群上进行高效深度学习的能力,利用TensorFlowOnSpark,数据科学家和工程师们可以直接利用运行于CPU/GPU架构上的Spark或者Hadoop做分布式模型训练。该库支持把现有的TensorFlow程序切换到新的API,同时实现了模型训练的性能提升。
在开源公告里,雅虎说明了TensorFlowOnSpark想解决的问题,比如在深度神经网络训练中管理Spark数据管线之外的其他集群带来的运维负载,以网络I/O为瓶颈的数据集在训练集群的传入和传出,令人讨厌的系统复杂性,以及端到端的整体学习时延。TensorFlowOnSpark的工作和雅虎之前开源的CaffeOnSpark相似。现有的对TensorFlow和Spark的集成所做的努力,有DataBricks的TensorFrame,以及Amp Lab 的SparkNet,这些对于雅虎来说都是在正确方向上的迈进,但是在允许TensorFlow进程之间直接通信方面还是有所欠缺。雅虎的目标之一,是让TensorFlowOnSpark成为一个完全对Spark兼容的API,在一个Spark处理工作流里,其集成能力能跟SparkSQL、MLib以及其他Spark核心库一样好。
在架构上,它把给定TensorFlow算法和TensorFlow core放在一个Spark Executor中,并让TensorFlow任务能够通过TensorFlow的文件阅读器和QueueRunners直接获取HDFS数据,这是一种有着更少网络I/O以及“把计算带给数据”的方案。TensorFlowOnSpark在语义上就支持对执行器的端口预留和监听,对数据和控制函数的消息轮询,TensorFlow主函数的启动,数据注入,直接从HDFS读取数据的阅读器和queue-runner机制,通过feed_dict向TensorFlow注入Spark RDD,以及关机。
除了TensorFlowOnSpark,yahoo还在他们自己的分支上扩展了TensorFlow核心C++引擎以在Infiniband里使用RDMA,这个需求在TensorFlow主项目里被提出过还产生了相关讨论。雅虎的Andy Feng注意到,使用RDMA而不是gRPC来做进程间通信,在不同的网络里会带来百分之十到百分之两百不等的训练速度的提升[2]。
2.TensorFlowOnSpark核心技术点
- 轻松迁移所有现有的TensorFlow程序,<10行代码更改;
- 支持所有TensorFlow功能:同步/异步训练,模型/数据并行,推理和TensorBoard;
- 服务器到服务器的直接通信在可用时实现更快的学习;
- 允许数据集在HDFS和由Spark推动的其他来源或由TensorFlow拖动;
- 轻松集成您现有的数据处理流水线和机器学习算法(例如,MLlib,CaffeOnSpark);
- 轻松部署在云或内部部署:CPU和GPU,以太网和Infiniband[3]。
3.基于Hadoop分布式群YARN模式的搭建
官方指导链接:https://github.com/yahoo/TensorFlowOnSpark/wiki/GetStarted_YARN,这篇文章过于简略,很多地方都没有说明白,初学者会绕很多弯路,也许是因为这个项目刚刚开源不久,很多指导性的说明都没有。简言之,官网的 Instructions 略坑,搭建成功与否靠人品。
以下是本人实践成功的步骤:
3.1 环境准备
已经安装了 Spark 的 Hadoop 分布式集群环境(安装于 Ubuntu Server 系统),下表显示了我的集群环境( Spark 已经开启):
| 主机名 | ip | 用途 |
| master | 192.168.0.20 |
ResourceManager NameNode SecondaryNameNode Master |
| node1 | 192.168.0.21 |
DataNode NodeManager Worker |
| node2 | 192.168.0.22 |
DataNode NodeManager Worker |
这里给大家推荐一个超详细的关于部署 Hadoop 完全分布式集群的博客:http://blog.csdn.net/dream_an/article/details/52946840[4]
3.2 在 Master 节点上进行:
(1) 安装 Python 2.7
这一步的是在本地文件夹里下载安装 Python ,目的是在进行任务分发的时候能够把这个 Python 和其他依赖环境(这里指的是包含 TensorFlow)同时分发给对应的 Spark executor ,所以这一步不是单纯的只安装 Python 。
#下载解压 Python 2.7
export PYTHON_ROOT=~/Python curl -O https://www.python.org/ftp/python/2.7.12/Python-2.7.12.tgz tar -xvf Python-2.7.12.tgz rm Python-2.7.12.tgz
#在编译 Python 之前,需要完成以下工作,否则编译产生的 python 会出现没有 zlib 、没有 SSL 模块等错误
#安装 ruby , zlib , ssl 相关包
sudo apt install ruby
sudo apt install zlib1g,zlib1g.dev
sudo apt install libssl-dev
#进入刚才解压的 Python 目录,修改 Modules/Setup.dist文件,该文件是用于产生 Python 相关配置文件的
cd Python-2.7.12
sudo vim Modules/Setup.dist
#去掉 ssl , zlib 相关的注释:
#与 ssl 相关:
#SSL=/usr/local/ssl
#_ssl _ssl.c \
# -DUSE_SSL -I$(SSL)/include -I$(SSL)/include/openssl \
# -L$(SSL)/lib -lssl -lcrypto
#与 zlib 相关:
#zlib zlibmodule.c -I$(prefix)/include -L$(exec_prefix)/lib -lz
#编译 Python 到本地文件夹 ${PYTHON_ROOT}
pushd Python-2.7.12
./configure --prefix="${PYTHON_ROOT}" --enable-unicode=ucs4
#./configure 这一步如果提示 "no acceptable C compiler" , 需要安装 gcc : sudo apt install gcc
make
make install
popd
rm -rf Python-2.7.12
#安装 pip
pushd "${PYTHON_ROOT}"
curl -O https://bootstrap.pypa.io/get-pip.py
bin/python get-pip.py
rm get-pip.py
#安装 pydoop
${PYTHON_ROOT}/bin/pip install pydoop
#这里安装 pydoop,若是提示错误:LocalModeNotSupported,直接下载资源包通过 setup 安装:
#资源包下载:https://pypi.python.org/pypi/pydoop
#tar -xvf pydoop-1.2.0.tar.gz
#cd pydoop-1.2.0
#python setup.py build
#python setup.py install
#安装 TensorFlow
${PYTHON_ROOT}/bin/pip install tensorflow
#这里安装 tensorflow ,不需要从源码进行编译安装,除非你需要 RDMA 这个特性
popd
(2) 安装 TensorFlowOnSpark
git clone https://github.com/yahoo/TensorFlowOnSpark.git
git clone https://github.com/yahoo/tensorflow.git
#从 yahoo 下载的 TensorFlowOnSpark 资源包里面 tensorflow 是空的文件夹,git 上该文件夹连接到了 yahoo/tensorflow ,这里需要我们将 tensorflow 拷贝到 TensorFlowO#nSpark 下面:
sudo rm -rf TensorFlowOnSpark/tensorflow/
sudo mv tensorflow/ TensorFlowOnSpark/
#上面 tensorflow 和 TensorFlowOnSpark 文件目录根据自己的实际情况修改,我的是在根目录下面,所以如上
(3) 安装编译 Hadoop InputFormat/OutputFormat for TFRecords
#安装以下依赖工具:
sudo apt install autoconf,automake,libtool,curl,make,g++,unzip,maven
#先安装 protobuf
# git 上有详细说明:github上有详细的安装说明:https://github.com/google/protobuf/blob/master/src/README.md
#也可以参考链接:http://www.itdadao.com/articles/c15a1006495p0.html
#编译 TensorFlow 的 protos:
git clone https://github.com/tensorflow/ecosystem.git
cd ecosystem/hadoop
protoc --proto_path=/opt/TensorFlowOnSpark/tensorflow/ --java_out=src/main/java/ /opt/TensorFlowOnSpark/tensorflow/tensorflow/core/example/{example,
feature}.proto
mvn clean package
mvn install
#将上一步产生的 jar 包上传到 HDFS
cd target
hadoop fs -put tensorflow-hadoop-1.0-SNAPSHOT.jar
(4) 为 Spark 准备 Python with TensorFlow 压缩包
pushd "${PYTHON_ROOT}" zip -r Python.zip * popd #将该压缩包上传到 HDFS hadoop fs -put ${PYTHON_ROOT}/Python.zip
(5) 为 Spark 准备 TensorFlowOnSpark 压缩包
pushd TensorFlowOnSpark/src zip -r ../tfspark.zip * popd
环境基本搭建完成。
4. 测试[5]
1)准备数据
下载、压缩mnist数据集
mkdir ${HOME}/mnist
pushd ${HOME}/mnist >/dev/null
curl -O "http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz"
curl -O "http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz"
curl -O "http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz"
curl -O "http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz"
zip -r mnist.zip *
popd >/dev/null
2)feed_dic方式运行,步骤如下
# step 1 设置环境变量 export PYTHON_ROOT=~/Python export LD_LIBRARY_PATH=${PATH} export PYSPARK_PYTHON=${PYTHON_ROOT}/bin/python export SPARK_YARN_USER_ENV="PYSPARK_PYTHON=Python/bin/python" export PATH=${PYTHON_ROOT}/bin/:$PATH export QUEUE=default # step 2 上传文件到hdfs hdfs dfs -rm /user/${USER}/mnist/mnist.zip hdfs dfs -put ${HOME}/MLdata/mnist/mnist.zip /user/${USER}/mnist/mnist.zip # step 3 将图像文件(images)和标签(labels)转换为CSV文件 hdfs dfs -rm -r /user/${USER}/mnist/csv ${SPARK_HOME}/bin/spark-submit \ --master yarn \ --deploy-mode cluster \ --queue ${QUEUE} \ --num-executors 4 \ --executor-memory 4G \ --archives hdfs:///user/${USER}/Python.zip#Python,hdfs:///user/${USER}/mnist/mnist.zip#mnist \ TensorFlowOnSpark/examples/mnist/mnist_data_setup.py \ --output mnist/csv \ --format csv # step 4 训练(train) hadoop fs -rm -r mnist_model ${SPARK_HOME}/bin/spark-submit \ --master yarn \ --deploy-mode cluster \ --queue ${QUEUE} \ --num-executors 3 \ --executor-memory 8G \ --py-files ${HOME}/TensorFlowOnSpark/tfspark.zip,${HOME}/TensorFlowOnSpark/examples/mnist/spark/mnist_dist.py \ --conf spark.dynamicAllocation.enabled=false \ --conf spark.yarn.maxAppAttempts=1 \ --conf spark.yarn.executor.memoryOverhead=6144 \ --archives hdfs:///user/${USER}/Python.zip#Python \ --conf spark.executorEnv.LD_LIBRARY_PATH="$JAVA_HOME/jre/lib/amd64/server" \ ${HOME}/TensorFlowOnSpark/examples/mnist/spark/mnist_spark.py \ --images mnist/csv/train/images \ --labels mnist/csv/train/labels \ --mode train \ --model mnist_model # step 5 推断(inference) hadoop fs -rm -r predictions ${SPARK_HOME}/bin/spark-submit \ --master yarn \ --deploy-mode cluster \ --queue ${QUEUE} \ --num-executors 3 \ --executor-memory 8G \ --py-files ${HOME}/TensorFlowOnSpark/tfspark.zip,${HOME}/TensorFlowOnSpark/examples/mnist/spark/mnist_dist.py \ --conf spark.dynamicAllocation.enabled=false \ --conf spark.yarn.maxAppAttempts=1 \ --conf spark.yarn.executor.memoryOverhead=6144 \ --archives hdfs:///user/${USER}/Python.zip#Python \ --conf spark.executorEnv.LD_LIBRARY_PATH="$JAVA_HOME/jre/lib/amd64/server" \ ${HOME}/TensorFlowOnSpark/examples/mnist/spark/mnist_spark.py \ --images mnist/csv/test/images \ --labels mnist/csv/test/labels \ --mode inference \ --model mnist_model \ --output predictions # step 6 查看结果(可能有多个文件) hdfs dfs -ls predictions hdfs dfs -cat predictions/part-00001 hdfs dfs -cat predictions/part-00002 hdfs dfs -cat predictions/part-00003 #网页方式,查看spark作业运行情况,这里的 ip 地址是 master 节点的 ip http://192.168.0.20:8088/cluster/apps/
3) queuerunner方式运行,步骤如下
# step 1 设置环境变量 export PYTHON_ROOT=~/Python export LD_LIBRARY_PATH=${PATH} export PYSPARK_PYTHON=${PYTHON_ROOT}/bin/python export SPARK_YARN_USER_ENV="PYSPARK_PYTHON=Python/bin/python" export PATH=${PYTHON_ROOT}/bin/:$PATH export QUEUE=default # step 2 上传文件到hdfs hdfs dfs -rm /user/${USER}/mnist/mnist.zip hdfs dfs -rm -r /user/${USER}/mnist/tfr hdfs dfs -put ${HOME}/MLdata/mnist/mnist.zip /user/${USER}/mnist/mnist.zip # step 3 将图像文件(images)和标签(labels)转换为TFRecords ${SPARK_HOME}/bin/spark-submit \ --master yarn \ --deploy-mode cluster \ --queue ${QUEUE} \ --num-executors 4 \ --executor-memory 4G \ --archives hdfs:///user/${USER}/Python.zip#Python,hdfs:///user/${USER}/mnist/mnist.zip#mnist \ --jars hdfs:///user/${USER}/tensorflow-hadoop-1.0-SNAPSHOT.jar \ ${HOME}/TensorFlowOnSpark/examples/mnist/mnist_data_setup.py \ --output mnist/tfr \ --format tfr # step 4 训练(train) hadoop fs -rm -r mnist_model ${SPARK_HOME}/bin/spark-submit \ --master yarn \ --deploy-mode cluster \ --queue ${QUEUE} \ --num-executors 4 \ --executor-memory 4G \ --py-files ${HOME}/TensorFlowOnSpark/tfspark.zip,${HOME}/TensorFlowOnSpark/examples/mnist/tf/mnist_dist.py \ --conf spark.dynamicAllocation.enabled=false \ --conf spark.yarn.maxAppAttempts=1 \ --conf spark.yarn.executor.memoryOverhead=4096 \ --archives hdfs:///user/${USER}/Python.zip#Python \ --conf spark.executorEnv.LD_LIBRARY_PATH="$JAVA_HOME/jre/lib/amd64/server" \ ${HOME}/TensorFlowOnSpark/examples/mnist/tf/mnist_spark.py \ --images mnist/tfr/train \ --format tfr \ --mode train \ --model mnist_model # step 5 推断(inference) hadoop fs -rm -r predictions ${SPARK_HOME}/bin/spark-submit \ --master yarn \ --deploy-mode cluster \ --queue ${QUEUE} \ --num-executors 4 \ --executor-memory 4G \ --py-files ${HOME}/TensorFlowOnSpark/tfspark.zip,${HOME}/TensorFlowOnSpark/examples/mnist/tf/mnist_dist.py \ --conf spark.dynamicAllocation.enabled=false \ --conf spark.yarn.maxAppAttempts=1 \ --conf spark.yarn.executor.memoryOverhead=4096 \ --archives hdfs:///user/${USER}/Python.zip#Python \ --conf spark.executorEnv.LD_LIBRARY_PATH="$JAVA_HOME/jre/lib/amd64/server" \ ${HOME}/TensorFlowOnSpark/examples/mnist/tf/mnist_spark.py \ --images mnist/tfr/test \ --mode inference \ --model mnist_model \ --output predictions # step 6 查看结果(可能有多个文件) hdfs dfs -ls predictions hdfs dfs -cat predictions/part-00001 hdfs dfs -cat predictions/part-00002 hdfs dfs -cat predictions/part-00003 #网页方式,查看spark作业运行情况,这里的 ip 地址是 master 节点对应的 ip http://192.168.0.20:8088/cluster/apps/
5. 参考资料
[1] https://databricks.com/blog/2016/01/25/deep-learning-with-apache-spark-and-tensorflow.html
[2] https://www.infoq.com/news/2017/03/tensorflow-spark
[3] http://blog.csdn.net/sinat_34233802/article/details/68942780
[4] http://blog.csdn.net/dream_an/article/details/52946840
[5] http://blog.csdn.net/hjh00/article/details/64439268
版权声明:本文未特殊标注为原创,未经博主允许不得转载。

