
福大软工1816 · 第五次作业 - 结对作业2
结对同学的博客链接
本作业博客的链接
Github项目地址
附加功能代码
代码规范链接
-
具体分工
胡绪佩:词组词频统计功能+字符及有效行数目、单元测试、性能分析、博客撰写
庄卉:爬虫、词频权重计算+自定义统计输出、附加功能、博客撰写
-
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 30 |
| · Estimate | · 估计这个任务需要多少时间 | 30 | 30 |
| Development | 开发 | 1770 | 1740 |
| · Analysis | · 需求分析 (包括学习新技术) | 120 | 150 |
| · Design Spec | · 生成设计文档 | 30 | 30 |
| · Design Review | · 设计复审 | 30 | 30 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 30 | 60 |
| · Design | · 具体设计 | 120 | 90 |
| · Coding | · 具体编码 | 900 | 720 |
| · Code Review | · 代码复审 | 180 | 180 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 360 | 480 |
| Reporting | 报告 | 120 | 120 |
| · Test Repor | · 测试报告 | 60 | 30 |
| · Size Measurement | · 计算工作量 | 30 | 20 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 70 |
| | 合计 | 1920|1890
-
解题思路描述与设计实现说明
-
爬虫使用
用urllib.request抓取顶会论文列表网址得到源代码,beautifulsoup配合正则(附加功能爬虫使用到)即可得到论文列表的基本信息。 -
f = open("result.txt", 'a', encoding='utf-8')
html1 = urllib.request.urlopen("http://openaccess.thecvf.com/CVPR2018.py").read()
bf1 = BeautifulSoup(html1)
texts1 = bf1.select('.ptitle')
a_bf = BeautifulSoup(str(texts1))
a = a_bf.find_all('a')
urls = []
for each in a:
urls.append("http://openaccess.thecvf.com/" + each.get('href'))
for i in range(len(urls)):
f.write(str(i))
f.write("\n")
html2 = urllib.request.urlopen(urls[i]).read()
bf = BeautifulSoup(html2)
texts2 = bf.find_all('div', id='papertitle')
f.write("Title: " + texts2[0].text.lstrip('\n') + "\n")
texts3 = bf.find_all('div', id='abstract')
f.write("Abstract: " + texts3[0].text.lstrip('\n') + "\n\n\n")
-
代码组织与内部实现设计
代码文件组织
031602114&031602444
|- src
|- WordCount.sln
|- WordCount
|- CharCount.cpp
|- CharCount.h
|- LineCount.cpp
|- LineCount.h
|- WeightTypeNE.cpp
|- WeightTypeNE.h
|- SortTopN.cpp
|- SortTopN.h
|- Word_Group_Cnt.cpp
|- Word_Group_Cnt.h
|- WordCount.cpp
|- WordCount.h
|- pch.cpp
|- pch.h
|- main.cpp
|- WordCount.vcxproj
|- cvpr
|- Crawler.py
|- result.txt
关系图
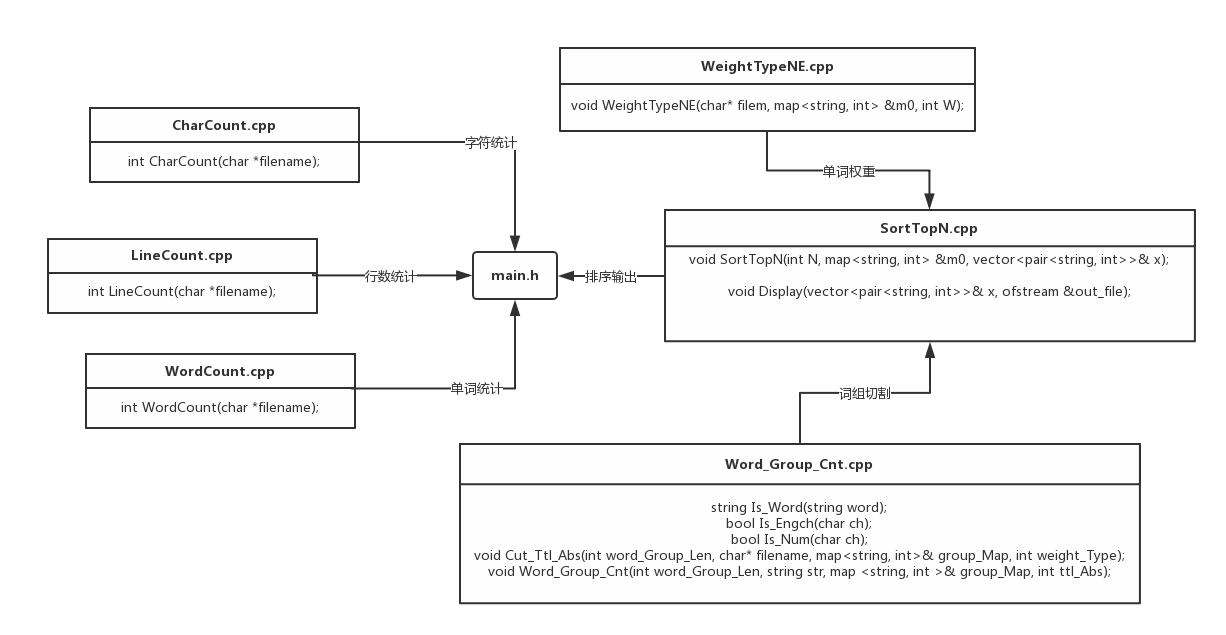
-
说明算法的关键与关键实现部分流程图
单词权重计算
根据个人项目判断有效单词的算法进行改进,讲按字符串读取改成按行读取,判断该行是title还是absract,通过存储分割符的位置进行切割读取有效词并计算权重。
**词组切割 **
根据用户输入决定词组切割长度,切割过程中借用队列辅助存储每一个合法单词的长度,遇到不合法单词则可以将队列que清空即可,否则就根据词组单词组成长度以及队列存储的单词长度进行进队出队操作,达到更新string后进行截取(使用substr库函数)得到新的词组存入map容器。
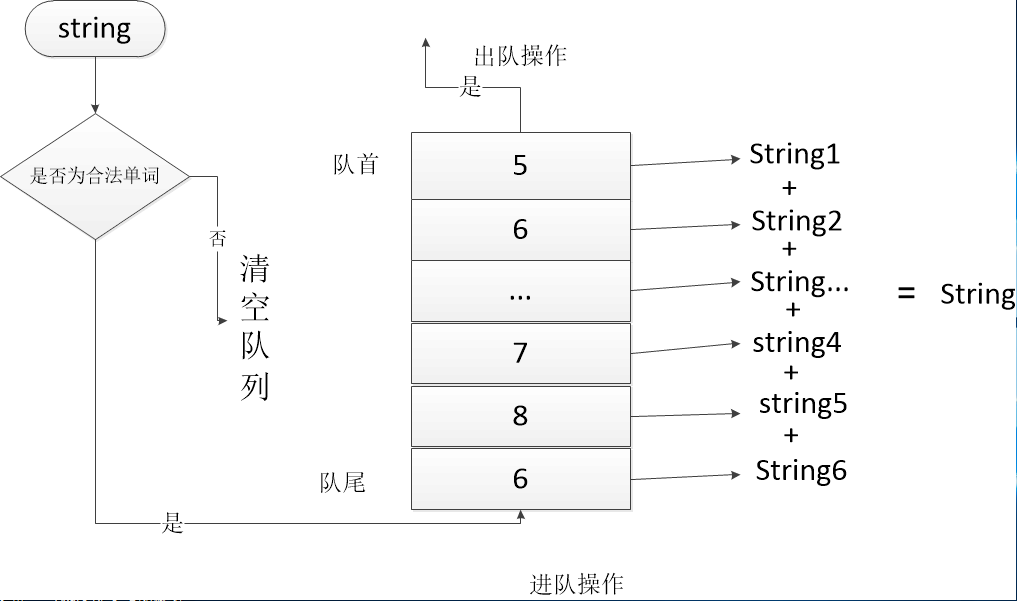
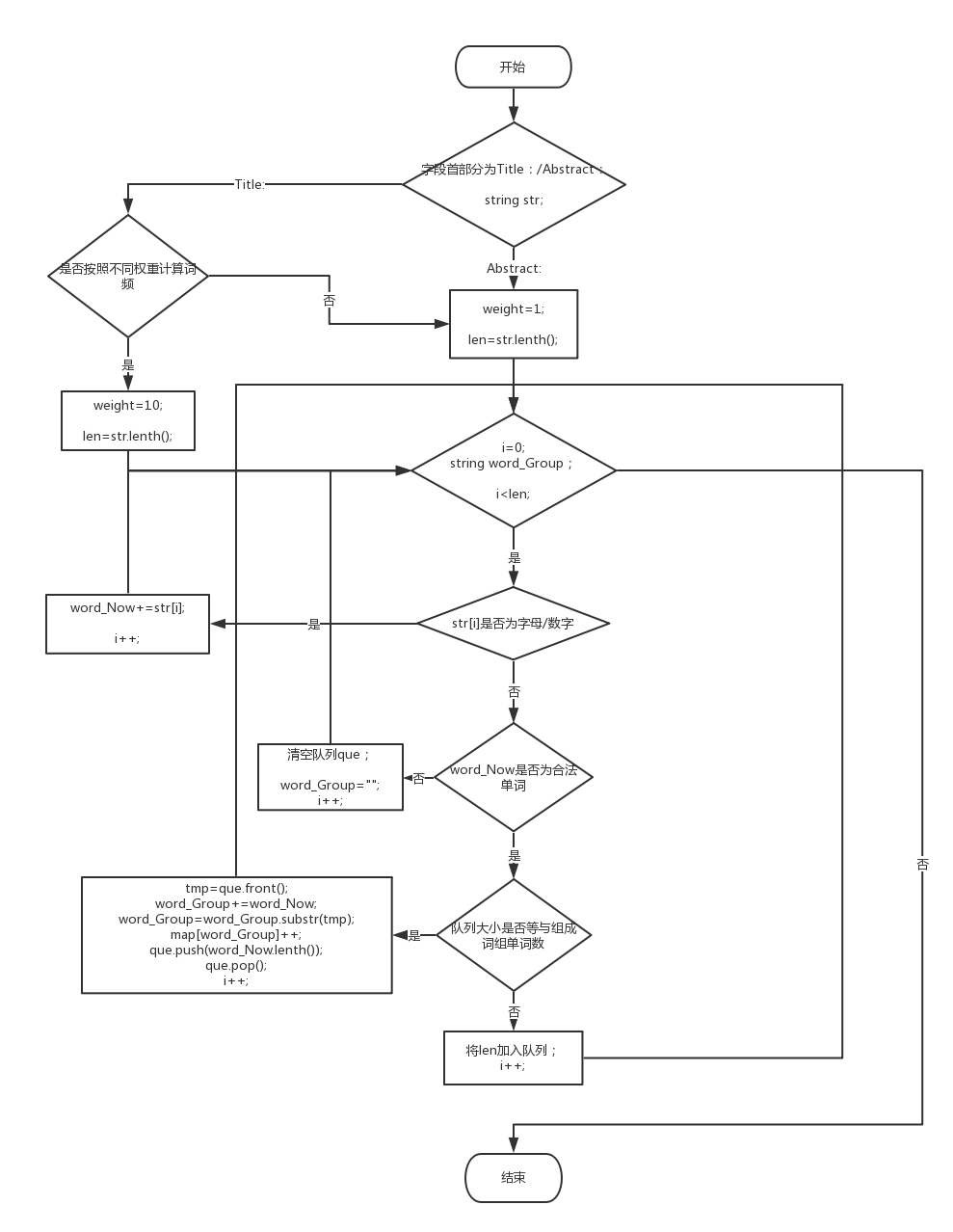
-
附加题设计与展示
-
爬虫能力有限orz,只从网站综合爬取论文的除题目、摘要外其他信息。爬虫语言使用python。额外爬取信息有:作者、PDF链接、SUPPPDF链接、ARXIV链接。
txt文件如图:

-
想象力有限orz,我们分析了论文列表中各位作者之间的关系,论文A的第一作者可能同时是论文B的第二作者,不同论文多位作者之间可能存在着联系,并将关系可视化。
我们从附加功能1的txt文件提取了发表在2018cvpr顶会上的所有论文的第一作者和第二作者,使用分析工具NodeXL做出了关系图谱。
图谱全貌如下:

逐渐剔除较少联系点的图谱如下:
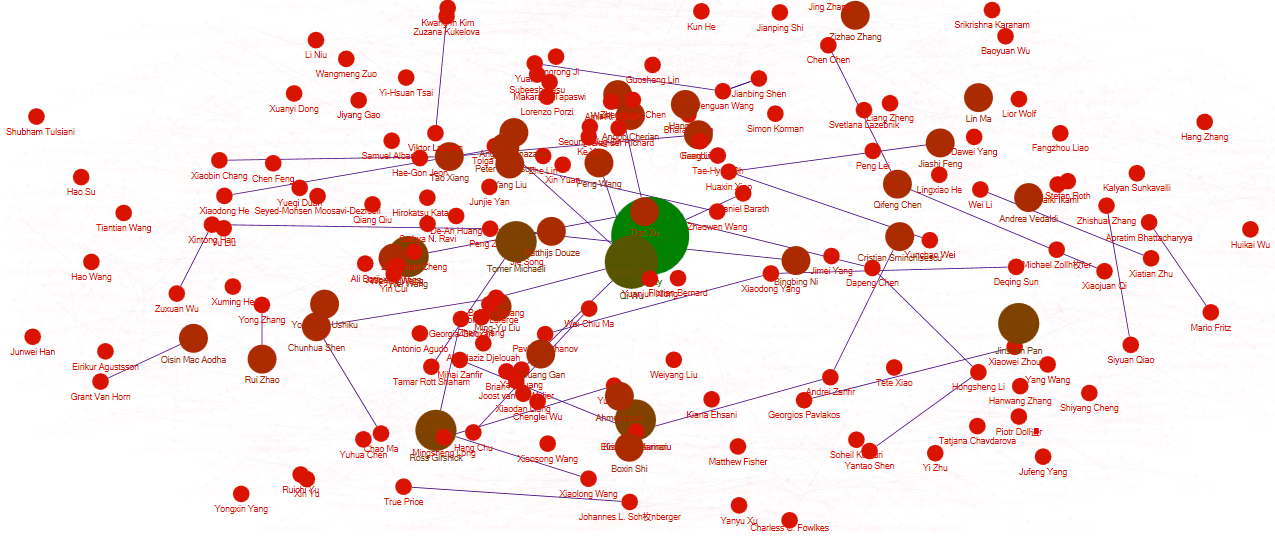
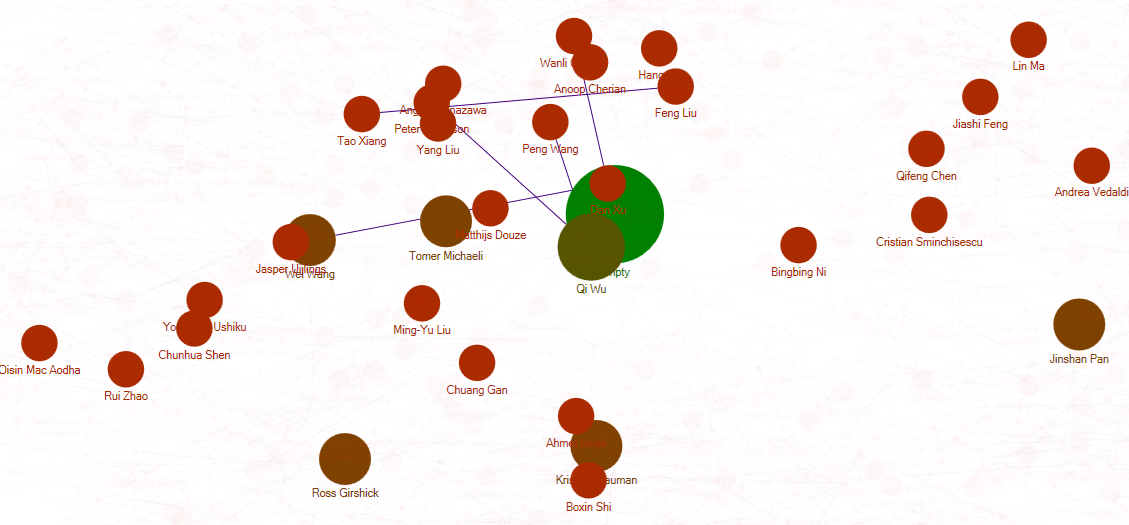
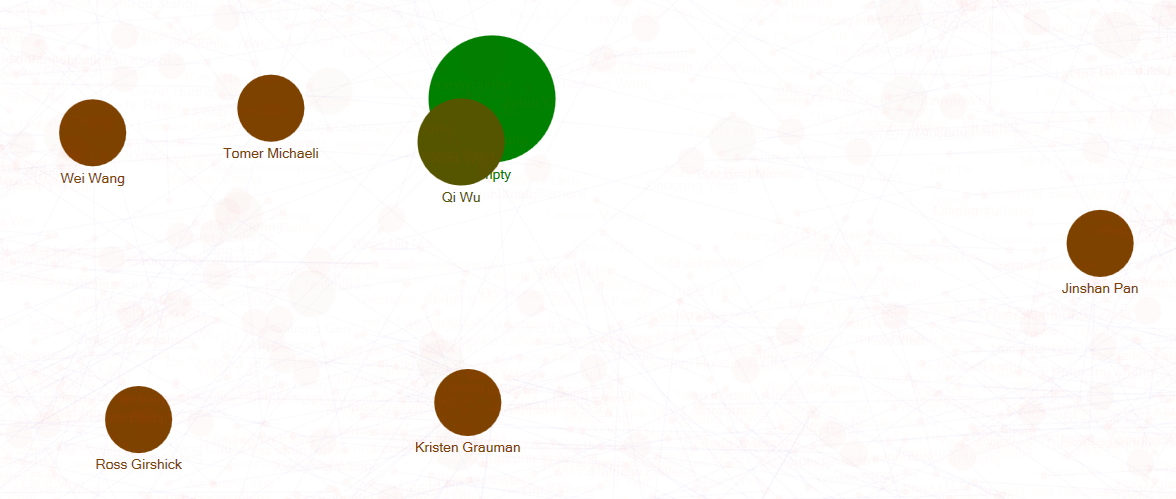
(没有第二作者时在第二作者处填empty)可以看出在2018cvpr上发表论文且是主要作者的大神就是——Qi Wu,紧接着还有Wei Wang,Tomer Michaeli,Ross Girshick等等。(然后发表数目多的主要作者们互相之间都不合作的吗……
3. 修改了了基本功能的代码,输出了发表最多论文的作者top10并将其可视化。
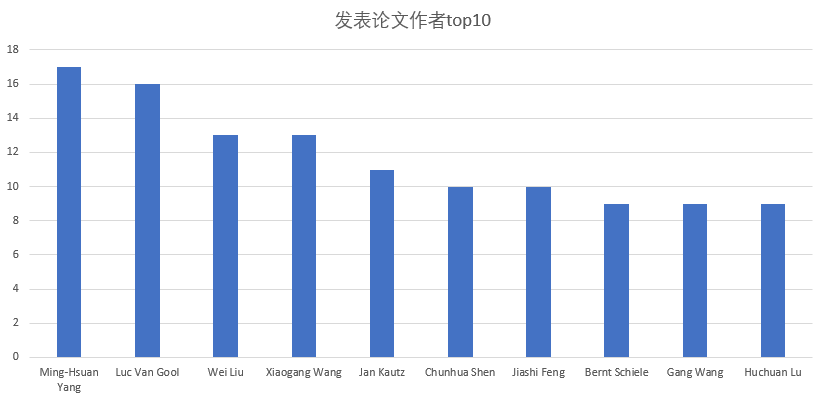
可以看出发表论文最多的作者是Ming-Hsuan Yang,在2018cvpr上一共发表了17篇论文。
-
-
关键代码解释
具体解释: 使用辅助队列存储每个合法单词的长度,通过入队和出队操作更新string进行截取不断获得新的词组;函数详情在以下.h文件中均有描述。
- 词组统计.h文件
- 词频排序.h文件
- 单词统计.h文件
/*统计指定长度的合法单词量形成的词组词频*/
void Word_Group_Cnt(int word_Group_Len, string str, map <string, int > &group_Map,int ttl_Abs)
{
string word_Now = "";
string word_Group = "";
int lenth = str.length();
queue <int> que;
for (int i = 0; i < lenth; i++)
{
if (Is_Num(str[i]) || Is_Engch(str[i]) && i != lenth - 1) //字符是字母或数字就将其连接到word_Now
{
word_Now += str[i];
continue;
}
else if (Is_Num(str[i]) || Is_Engch(str[i]) && i == lenth - 1) //字符是字母或数字且为字段末位连接后就需要对末尾的单词判断是否为合法单词,否则会跳出循环漏掉末尾一个单词;
{
word_Now += str[i];
word_Now = Is_Word(word_Now);
int word_Len = word_Now.length();
if (word_Len >= 4)
{
word_Group += word_Now;
if (que.size() == word_Group_Len - 1)
{
group_Map[word_Group] += ttl_Abs;
}
else if (que.size() > word_Group_Len - 1)
{
word_Group = word_Group.substr(que.front());
group_Map[word_Group] += ttl_Abs;
}
}
else if (word_Len >= 0 && word_Len < 4)
{
continue;
}
}
else
{
word_Now = Is_Word(word_Now);
int word_Len = word_Now.length();
if (word_Len >= 4)
{
word_Group += word_Now;
if (que.size() < word_Group_Len - 1) //队列大小比所需合法单词数word_Group_Len-1小情况
{
word_Group += str[i];
word_Len += 1;
while (!Is_Num(str[i + 1]) && !Is_Engch(str[i + 1]) && i + 1 < lenth)
{
word_Group += str[i + 1];
word_Len += 1;
i += 1;
}
que.push(word_Len);
word_Now = "";
}
else if (que.size() == word_Group_Len - 1) //队列大小=所需合法单词数word_Group_Len-1情况
{
group_Map[word_Group] += ttl_Abs;
word_Group += str[i];
word_Len += 1;
while (!Is_Num(str[i + 1]) && !Is_Engch(str[i + 1]) && i + 1 < lenth)
{
word_Group += str[i + 1];
word_Len += 1;
i += 1;
}
que.push(word_Len);
word_Now = "";
}
else if (que.size() > word_Group_Len - 1) //队列大小等于词组所需合法单词数量,则对队列进行进队和出队操作更新string并进行截取
{
word_Group = word_Group.substr(que.front());
group_Map[word_Group] += ttl_Abs;
que.pop();
word_Group += str[i];
word_Len += 1;
while (!Is_Num(str[i + 1]) && !Is_Engch(str[i + 1]) && i + 1 < lenth)
{
word_Group += str[i + 1];
word_Len += 1;
i += 1;
}
que.push(word_Len);
word_Now = "";
}
}
else if (word_Len > 0 && word_Len < 4) //遇到不合法单词且不是分隔符或空串的,则返回为no,将队列清空
{
while (que.empty() != 1)
{
que.pop();
}
word_Now = "";
word_Group = "";
}
else if (word_Len == 0)
{
continue;
} //是否要判断在输入到函数中
}
}
}
-
性能分析与改进
-
描述你改进的思路
-
展示性能分析图和程序中消耗最大的函数
-
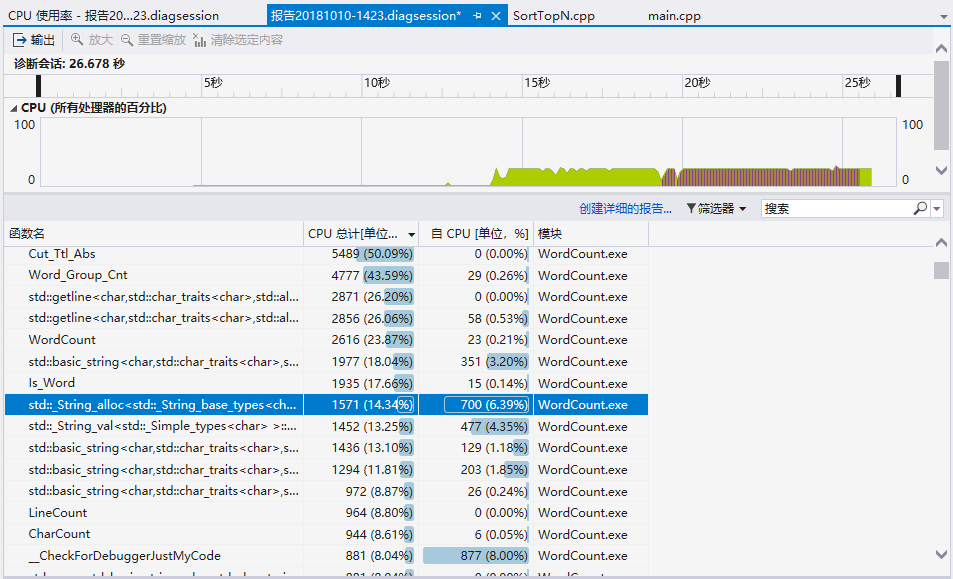
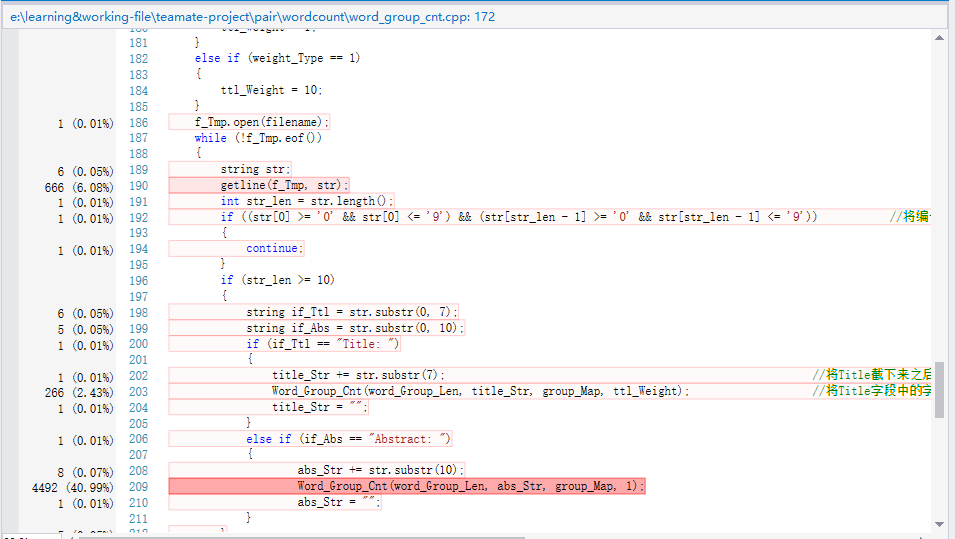
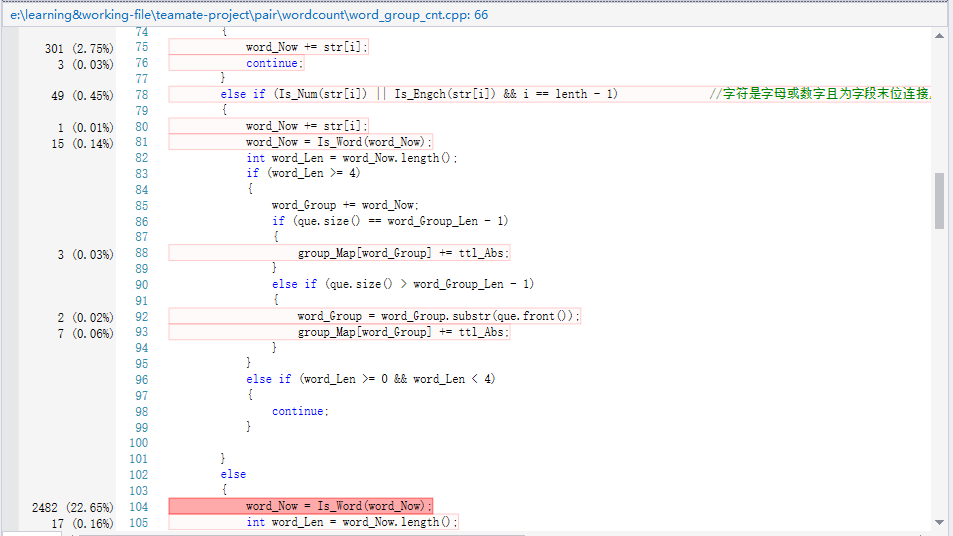
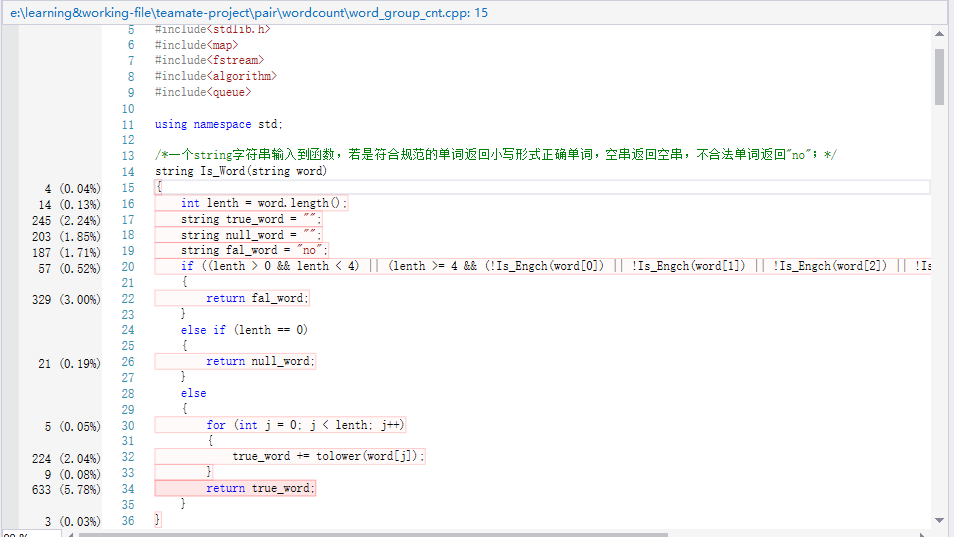
-
单元测试
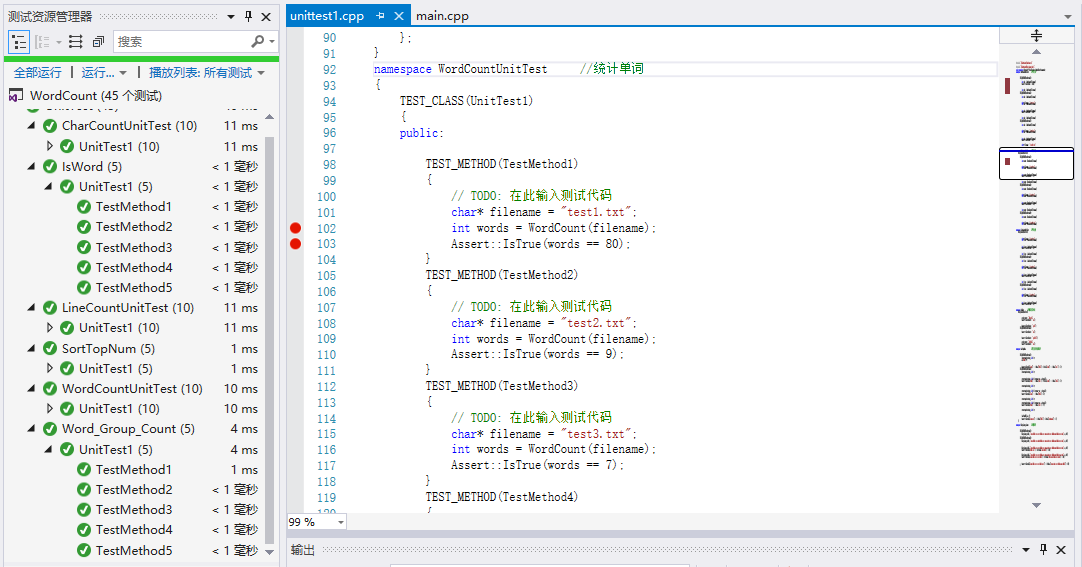

测试的函数及其测试数据构造思路:
-
LineCount(计算行数):
构造思路:
- 中间增加空白行;
- 当字符串长度大小超过1024,txt则会在视觉上显示两行但其实是一行;
- 多(十)个测试数据文件防止偶然性
-
WordCount(计算单词数):
构造思路:
- 多种不合法单词,如123ahkjk,kkk3jkljk,kkk,lll等等;
- 通过特殊分隔符分隔的一长串单词视为两个单词,如title-task,github--parent等等;
- 标题摘要的两个关键字可能不仅只在首端“Title:”、“Abstract:”形式出现,后续摘要标题内容也可能存在这两个单词;
- 多(十)个测试数据文件防止偶然性;
-
CharCount(计算字符数):
构造思路:
- 编号长度不固定,比如1、23、978、976、46,这些字符统计长度会变化;
- 两篇论文间或者论文列表后面有多余空白行,即不止只有两行空行时,应该计算其字符数;
- 多(十)个测试数据文件防止偶然性;
-
IsWord(判断是否为合法单词):
构造思路:
- 输入有大写字母返回时应将其转化为小写形式输出;
- 输入为多种不合法单词,如123,123llllk,kkk,kkk1235,llk2lk等等输出为no;
- 输入为空串时返回依旧为空串;
-
Word_Group_Count(词组切割统计):
构造思路:
- 合法单词之间可能存在多个分隔符;
- 合法单词之间存在不合法单词;
- 连续合法单词个数超过用户定义组成词组单词个数;
- 同一词组出现多次;
-
SortTopNum(对前Num单词或词组进行词频排序):
构造思路:
- 不同单词的数量不同;
- 单词数量相同但是其字典序不同;
- Num数量变化词组合法单词数变化;
对于其他一些函数,因为在计算行数、计算单词数、计算字符数、词组切割统计以及词频排序中都有调用,而这些函数测试均正确,因此那些简易的函数的没有做出测试,通过复杂函数的正确测试间接反应其正确性。
部分代码展示:
namespace IsWord //判断是否是单词
{
TEST_CLASS(UnitTest1)
{
public:
TEST_METHOD(TestMethod1)
{
string word = "123ajlk";
word = Is_Word(word);
Assert::IsTrue(word == "no");
}
TEST_METHOD(TestMethod2)
{
string word = "Ajlk";
word = Is_Word(word);
Assert::IsTrue(word == "ajlk");
}
TEST_METHOD(TestMethod3)
{
string word = "Ajl";
word = Is_Word(word);
Assert::IsTrue(word == "no");
}
TEST_METHOD(TestMethod4)
{
string word = "Ajlk123";
word = Is_Word(word);
Assert::IsTrue(word == "ajlk123");
}
TEST_METHOD(TestMethod5)
{
string word = "jl12k23";
word = Is_Word(word);
Assert::IsTrue(word == "no");
}
};
}
namespace Word_Group_Count //词组切割统计
{
TEST_CLASS(UnitTest1)
{
public:
TEST_METHOD(TestMethod1)
{
map<string, int> m;
Word_Group_Cnt(3, "aaaa bbbb cccc cccc bbbb cccc aaaa dddd cccc bbbb aaaa bbbb cccc dddd", m, 10);
Assert::IsTrue(m["aaaa bbbb cccc"] == 20 && m["bbbb cccc cccc"] == 10);
}
TEST_METHOD(TestMethod2)
{
map<string, int> m;
Word_Group_Cnt(4, "aaaa bbbb cccc dddd bbbb cccc aaaa dddd cccc bbbb aaaa bbbb cccc dddd", m, 10);
Assert::IsTrue(m["aaaa bbbb cccc dddd"] == 20 && m["bbbb cccc dddd bbbb"] == 10);
}
TEST_METHOD(TestMethod3)
{
map<string, int> m;
Word_Group_Cnt(2, "aaaa bbbb cccc cccc bbbb cccc aaaa dddd cccc bbbb aaaa bbbb cccc dddd", m, 10);
Assert::IsTrue(m["bbbb cccc"] == 30 && m["aaaa bbbb"] == 20);
}
TEST_METHOD(TestMethod4)
{
map<string, int> m;
Word_Group_Cnt(5, "aaaa (bbbb) cccc cccc bbbb cccc aaaa dddd cccc bbbb aaaa bbbb cccc dddd", m, 10);
Assert::IsTrue(m["aaaa (bbbb) cccc cccc bbbb"] == 10 && m["bbbb aaaa bbbb cccc dddd"] == 10);
}
TEST_METHOD(TestMethod5)
{
map<string, int> m;
Word_Group_Cnt(6, "aaaa (bbbb)-cccc cccc bbbb cccc aaaa dddd cccc bbbb aaaa bbbb cccc dddd", m, 10);
Assert::IsTrue(m["aaaa (bbbb)-cccc cccc bbbb cccc"] == 10 && m["aaaa dddd cccc bbbb aaaa bbbb"] == 10);
}
};
}
代码覆盖率:

-
贴出Github的代码签入记录
(两人提交记录)
-
遇到的代码模块异常或结对困难及解决方法
① 佩佩
-
问题描述:
- (已解决)词组切割时题意不清楚,对作业的分隔符也要输出的要求感觉太不友好和助教联系请教了一段时间,最终敌不过大家都没意见,本人势单力薄,而助教说的投票杳无音信,于是,恭喜自己决定有无分隔符的都写个函数,这样便不受影响了;
- (已解决)对Title和Abstract进行切割的时候一度以为满了txt一行所示的1024个字符便算一行,因此切割时做了许多额外的满1024个字符考虑行与行之间的拼接组成总的abstract字段,但其实getline就是读取一行遇到换行符才会停下;
- (已解决)单元测试时遇到模块计算机x86和目标计算机x64冲突的问题,即库文件32位和项目文件64位之间存在冲突,一直不能正确测试;
- (已解决)在进行测试的时候txt文件首部莫名会添上3个编码头字符(隐藏着看不见的),将其编码改成UTF-8就好了。
-
做过哪些尝试:
- 直接需要输出分隔符和不需要输出分隔符函数分别写一个,就不存在这样的焦虑了,替自己的机智鼓掌!
- 最后在做单元测试的时候出现挺多错误,进行函数断点调试时发现原来getline读取的string直接就达到1058!(然后感慨于自己的sb,分什么1024)于是对代码进行修改删除;
- 敲重点!!! 琢磨了一个晚上下午下课至晚上8、9点不间断4 、5个小时查阅众多资料和寻求大佬未果(在此谢谢畅畅同学的分析和帮忙),最终仔细分析其根源,灵感将至,发现原来是obj文件路径设置的时候,其实创建一个Visual Studio项目会有x64和Debug和WordCount好几个文件夹,其中.exe和.obj文件在x64文件夹和Debug文件夹中都有,而我定的路径是Debug中的(个人看法:其实是32位产生的obj),因此会一直报错,将路径修改为x64里面的obj文件即可;关于这个问题详情可以参考我记录的纠错博客
- 询问温柔美丽的助教雨勤姐姐,得知我的问题所在并做出修改。在此谢过雨勤姐姐!!!
-
有何收获:
- 没有什么不友好要求,有的只是自己侥幸想方便想偷懒的心理,所有可能要求做一遍就easy soso了;
- 做单元测试真是一件需要时间,十分重要,任务繁琐的活,个人认为单元测试的目的便在于对于不同的函数进行多种情况覆盖考虑,测试其正确性,而不仅仅是为了完成单元测似的要求每个函数写一个简单的例子测试正确便视作测试完毕;单元测试是可以帮助确保函数的正确性,项目的正确性。
- 对于碰到的bug就应该多问多查多试探多琢磨,你会发现总是能解决的,虽然时间花费的不确定性蛮大(偷笑),这个自然就看手法了;
- 一直以来都觉得为什么要画流程图,流程图怎么画?总觉得很繁琐和没有必要,这次从头画了一遍流程图收获了很多!(当然画了蛮久)确实流程图可以帮助一个即使没有接触具体代码的人也能很快的了解实现的思路和框架。并且可以在自己画的过程中帮助理清代码的逻辑,对自己写的代码更清晰的认识。
②沸沸
-
问题描述:
(已解决)在附加功能的实现上,我们一开始爬到了作者和论文pdf网址等信息就止步于此,对更多信息的抓取和分析上产生了困难。 -
做过哪些尝试:
- 从google学术上意外发现了作者的个人资料,详尽到有与作者关系密切的其他作者,我们因此有了直接爬取现有分析结果的想法。失败的原因有很多,主要原因还是因为技术问题,作为刚刚入门python的小白对google的反爬封锁实在苦手,还有存在作者重名的问题难以检索,放弃。
- 尝试爬虫软件,不会用,失败。
- 爬取作者使用数据分析软件NodeXL大获成功,一举生成关系图谱。
-
有何收获:
爬虫能力提升,搜索能力提升 -
评价你的队友
胡绪佩
值得学习的地方
佩佩,有太多值得我学习的地方了……比如遇到bug不放弃坚持持续打码n小时解决,比如遇到问题钻研求知的精神,比如知难而进的性格,比如在我睡觉的时候把博客发了……好队友!!!
需要改进的地方
基本上没有,除了让我不要偷偷背着他打代码hhhhhhh
庄卉
值得学习的地方
沸沸,有太多值得我学习的地方了+1......比如看到项目便知道体谅队友把难点(附加功能)揽下力肝(卉:表示并没有完成得很好),比如写代码速度总是莫名其妙超快的不知道有何秘诀!比如善于和队友沟通交流的团队精神,解决未知困难的能力plusplus,完美解决了本次作业第一第二作者图谱的这个难点,比如温柔美丽的气质......棒队友!!!
需要改进的地方
基本上没有,再有机会紧抱大腿我定紧紧不放xixixixixi
-
学习进度条
| 第N周 | 新增代码(行) | 累计代码(行) | 本周学习耗时(小时) | 累计学习耗时(小时) | 重要成长 |
|---|---|---|---|---|---|
| 1 | 391 | 391 | 25 | 25 | 复习c++,学习单元测试和代码覆盖率,更熟悉Visual Studio的使用 |
| 2 | 100 | 491 | 5 | 30 | 在优化代码和改bug |
| 3 | 0 | 0 | 15 | 45 | 阅读《构建之法》第三章和第八章,学习使用Axure RP8,对UI设计有进一步了解和认识,对项目开发架构进一步的理解 |
| 4 | 441 | 932 | 25 | 70 | 对爬虫初步认识,还有待学习(队友负责模块),Debug能力++; |

