
Dictionary Learning(字典学习、稀疏表示以及其他)
第一部分 字典学习以及稀疏表示的概要
字典学习(Dictionary Learning)和稀疏表示(Sparse Representation)在学术界的正式称谓应该是稀疏字典学习(Sparse Dictionary Learning)。该算法理论包含两个阶段:字典构建阶段(Dictionary Generate)和利用字典(稀疏的)表示样本阶段(Sparse coding with a precomputed dictionary)。这两个阶段(如下图)的每个阶段都有许多不同算法可供选择,每种算法的诞生时间都不一样,以至于稀疏字典学习的理论提出者已变得不可考。笔者尝试找了Wikipedia和Google Scolar都无法找到这一系列理论的最早发起人。
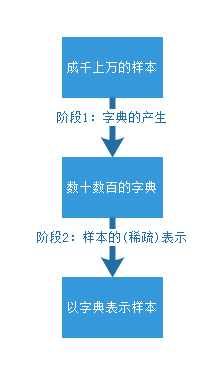
这里有两个问题是必须要预先解释清楚:
问题1:我们为什么需要字典学习?
回答这个问题实际上就是要回答“稀疏字典学习 ”中的字典是怎么来的。做一个比喻,句子是人类社会最神奇的东西,人类社会的一切知识无论是已经发现的还是没有发现的都必然要通过句子来表示出来(从某种意义上讲,公式也是句子)。这样说来,人类懂得的知识可要算是极为浩繁的。有人统计过人类每天新产生的知识可以装满一个2T(2048G)大小的硬盘。但无论有多少句子需要被书写,对于一个句子来说它最本质的特征是什么呢?毫无疑问,是一个个构成这个句子的单词(对英语来说)或字(对汉语来说)。所以我们可以很傲娇的这样认为,无论人类的知识有多么浩繁,也无论人类的科技有多么发达,一本长不过20厘米,宽不过15厘米,厚不过4厘米的新华字典或牛津字典足以表达人类从古至今乃至未来的所有知识,那些知识只不过是字典中字的排列组合罢了!直到这里,我相信相当一部分读者或许在心中已经明白了字典学习的第一个好处——它实质上是对于庞大数据集的一种降维表示。第二,正如同字是句子最质朴的特征一样,字典学习总是尝试学习蕴藏在样本背后最质朴的特征(假如样本最质朴的特征就是样本最好的特征),这两条原因同时也是这两年深度学习之风日盛的情况下字典学习也开始随之升温的原因。题外话:现代神经科学表明,哺乳动物大脑的初级视觉皮层干就事情就是图像的字典表示。
问题2:我们为什么需要稀疏表示?
回答这个问题毫无疑问就是要回答“稀疏字典学习”中稀疏两字的来历。不妨再举一个例子。相信大部分人都有这样一种感觉,当我们在解涉及到新的知识点的数学题时总有一种累心(累脑)的感觉。但是当我们通过艰苦卓绝的训练将新的知识点牢牢掌握时,再解决与这个知识点相关的问题时就不觉得很累了。这是为什么呢?意大利罗马大学的Fabio Babiloni教授曾经做过一项实验,他们让新飞行员驾驶一架飞机并采集了他们驾驶状态下的脑电,同时又让老飞行员驾驶飞机并也采集了他们驾驶状态下的脑电。如下图所示:

随后Fabio教授计算出了两类飞行员的大脑的活跃状态,如下图:
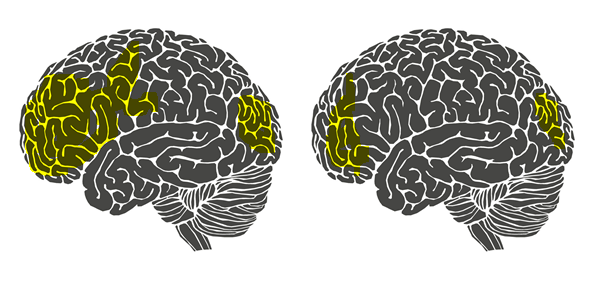
左图是新飞行员(不熟练的飞行员)的大脑。图中黄色的部分,是被认为活跃的脑区。右图是老飞行员(熟练的飞行员)的大脑,黄色区域相比左边的图有明显的减少。换言之,针对某一特定任务(这里是飞行),熟练者的大脑可以调动尽可能少的脑区消耗尽可能少的能量进行同样有效的计算(所以熟悉知识点的你,大脑不会再容易觉得累了),并且由于调动的脑区很少,大脑计算速度也会变快,这就是我们称熟练者为熟练者的原理所在。站在我们所要理解的稀疏字典学习的角度上来讲就是大脑学会了知识的稀疏表示。
稀疏表示的本质:用尽可能少的资源表示尽可能多的知识,这种表示还能带来一个附加的好处,即计算速度快。
在懂得“字典”和“稀疏”各自的那点事儿以后,我们还要再讲讲稀疏和字典共同的那点儿事。或许在大脑中“字典”和“稀疏”是两个不怎么想干的阶段,毕竟“字典”涉及初级视觉皮层,而“稀疏”涉及前额叶皮层。但是在计算机中,“字典”和“稀疏”却是一堆孪生兄弟。在学习样本字典之初的时候,稀疏条件就已经被加入了。我们希望字典里的字可以尽能的少,但是却可以尽可能的表示最多的句子。这样的字典最容易满足稀疏条件。也就是说,这个“字典”是这个“稀疏”私人订制的。
第二部分 稀疏字典学习的Python实现
用Python实现稀疏字典学习需要三个前提条件
1.安装NumPy
2.安装SciPy
3.安装Python机器学习工具包sklearn
为了避免过于麻烦的安装,这里我干脆建议诸位读者安装Python的商业发行版Anaconda,内含python集成开发环境和数百个常用的python支持包。具体安装过程和使用细节参见我的博客附录D Python接口大法。
样例一:图片的稀疏字典学习
这段代码来源于Python的Dictionary Learning的官方文献教材,主要用途是教会用户通过字典学习对图片进行滤波处理。
step1:首先是各种工具包的导入和测试样例的导入
- from time import time
- import matplotlib.pyplot as plt
- import numpy as np
- import scipy as sp
- from sklearn.decomposition import MiniBatchDictionaryLearning
- from sklearn.feature_extraction.image import extract_patches_2d
- from sklearn.feature_extraction.image import reconstruct_from_patches_2d
- from sklearn.utils.testing import SkipTest
- from sklearn.utils.fixes import sp_version
- if sp_version < (0, 12):
- raise SkipTest("Skipping because SciPy version earlier than 0.12.0 and "
- "thus does not include the scipy.misc.face() image.")
- try:
- from scipy import misc
- face = misc.face(gray=True)
- except AttributeError:
- # Old versions of scipy have face in the top level package
- face = sp.face(gray=True)
第1行:导入time模块,用于测算一些步骤的时间消耗
第3~5行:导入Python科学计算的基本需求模块,主要包括NumPy(矩阵计算模块)、SciPy(科学计算模块)和matplotlib.pyplot模块(画图)。有了这三个模块,Python俨然已是基础版的Matlab。
第7~11行:导入稀疏字典学习所需要的函数,下面分行解释
第7行:导入MiniBatchDictionaryLearning,MiniBatch是字典学习的一种方法,这种方法专门应用于大数据情况下字典学习。当数据量非常大时,严格对待每一个样本就会消耗大量的时间,而MiniBatch通过降低计算精度来换取时间利益,但是仍然能够通过大量的数据学到合理的词典。换言之,普通的DictionaryLearning做的是精品店,量少而精,但是价格高。MiniBatchDictionaryLearning做的是批发市场,量大不精,薄利多销。
第8行:导入碎片提取函数extract_patches_2d。调用该函数将一张图片切割为一个一个的pitch。如果一张图片相当于一篇文章的话,那么该函数的目标就是把文章中的每个句子都找到,这样才方便提取蕴藏在每个句子中的字。图片和pitch的关系如下图所示:
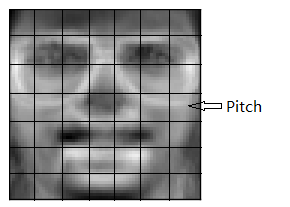
整张头像的照片是个图片,通过对图片的分割可以将图片分割为一个一个的小块,也就是一个个Pitch。如果对pitch仍然不了解,只好请你看这个:http://blog.csdn.net/zouxy09/article/details/8775488
第9行:导入图片复原函数reconstruct_from_patches_2d,它可以通过pitch复原一整张图片。
第10行:导入测试工具nose下的异常抛出函数SkipTest
第11行:导入SciPy版本检测函数sp_version用于检测版本高低,版本低于0.12的SciPy没有我们需要的样本测试用例
第13~15行:检测SciPy版本,如果版本太低就抛出一个异常。程序运行结束
第16~21行:尝试打开样本测试用例,如果打不开就抛出一个异常。
step2:通过测试样例计算字典V
- # Convert from uint8 representation with values between 0 and 255 to
- # a floating point representation with values between 0 and 1.
- face = face / 255.0
- # downsample for higher speed
- face = face[::2, ::2] + face[1::2, ::2] + face[::2, 1::2] + face[1::2, 1::2]
- face = face / 4.0
- height, width = face.shape
- # Distort the right half of the image
- print('Distorting image...')
- distorted = face.copy()
- distorted[:, width // 2:] += 0.075 * np.random.randn(height, width // 2)
- # Extract all reference patches from the left half of the image
- print('Extracting reference patches...')
- t0 = time()
- patch_size = (7, 7)
- data = extract_patches_2d(distorted[:, :width // 2], patch_size)
- data = data.reshape(data.shape[0], -1)
- data -= np.mean(data, axis=0)
- data /= np.std(data, axis=0)
- print('done in %.2fs.' % (time() - t0))
- print('Learning the dictionary...')
- t0 = time()
- dico = MiniBatchDictionaryLearning(n_components=100, alpha=1, n_iter=500)
- V = dico.fit(data).components_
- dt = time() - t0
- print('done in %.2fs.' % dt)
- plt.figure(figsize=(4.2, 4))
- for i, comp in enumerate(V[:100]):
- plt.subplot(10, 10, i + 1)
- plt.imshow(comp.reshape(patch_size), cmap=plt.cm.gray_r,
- interpolation='nearest')
- plt.xticks(())
- plt.yticks(())
- plt.suptitle('Dictionary learned from face patches\n' +
- 'Train time %.1fs on %d patches' % (dt, len(data)),
- fontsize=16)
- plt.subplots_adjust(0.08, 0.02, 0.92, 0.85, 0.08, 0.23)#left, right, bottom, top, wspace, hspace
第3行:读入的face大小在0~255之间,所以通过除以255将face的大小映射到0~1上去
第6~7行:对图形进行采样,把图片的长和宽各缩小一般。记住array矩阵的访问方式 array[起始点:终结点(不包括):步长]
第8行:图片的长宽大小
第12行:将face的内容复制给distorted,这里不用等号因为等号在python中其实是地址的引用。
第13行:对照片的右半部分加上噪声,之所以左半部分不加是因为教材想要产生一个对比的效果
第17行:开始计时,并保存在t0中
第18行:tuple格式的pitch大小
第19行:对图片的左半部分(未加噪声的部分)提取pitch
第20行:用reshape函数对data(94500,7,7)进行整形,reshape中如果某一位是-1,则这一维会根据(元素个数/已指明的维度)来计算这里经过整形后data变成(94500,49)
第21~22行:每一行的data减去均值除以方差,这是zscore标准化的方法
第26行:初始化MiniBatchDictionaryLearning类,并按照初始参数初始化类的属性
第27行:调用fit方法对传入的样本集data进行字典提取,components_返回该类fit方法的运算结果,也就是我们想要的字典V
第31~41行:画出V中的字典,下面逐行解释
第31行:figsize方法指明图片的大小,4.2英寸宽,4英寸高。其中一英寸的定义是80个像素点
第32行:循环画出100个字典V中的字
第41行:6个参数与注释后的6个属性对应
运行程序,查看输出结果:

step3:画出标准图像和真正的噪声,方便同之后字典学习学到的噪声相比较
- def show_with_diff(image, reference, title):
- """Helper function to display denoising"""
- plt.figure(figsize=(5, 3.3))
- plt.subplot(1, 2, 1)
- plt.title('Image')
- plt.imshow(image, vmin=0, vmax=1, cmap=plt.cm.gray,
- interpolation='nearest')
- plt.xticks(())
- plt.yticks(())
- plt.subplot(1, 2, 2)
- difference = image - reference
- plt.title('Difference (norm: %.2f)' % np.sqrt(np.sum(difference ** 2)))
- plt.imshow(difference, vmin=-0.5, vmax=0.5, cmap=plt.cm.PuOr,
- interpolation='nearest')
- plt.xticks(())
- plt.yticks(())
- plt.suptitle(title, size=16)
- plt.subplots_adjust(0.02, 0.02, 0.98, 0.79, 0.02, 0.2)
- show_with_diff(distorted, face, 'Distorted image')
程序输出如下图所示:

step4:测试不同的字典学习方法和参数对字典学习的影响
- print('Extracting noisy patches... ')
- t0 = time()
- data = extract_patches_2d(distorted[:, width // 2:], patch_size)
- data = data.reshape(data.shape[0], -1)
- intercept = np.mean(data, axis=0)
- data -= intercept
- print('done in %.2fs.' % (time() - t0))
- transform_algorithms = [
- ('Orthogonal Matching Pursuit\n1 atom', 'omp',
- {'transform_n_nonzero_coefs': 1}),
- ('Orthogonal Matching Pursuit\n2 atoms', 'omp',
- {'transform_n_nonzero_coefs': 2}),
- ('Least-angle regression\n5 atoms', 'lars',
- {'transform_n_nonzero_coefs': 5}),
- ('Thresholding\n alpha=0.1', 'threshold', {'transform_alpha': .1})]
- reconstructions = {}
- for title, transform_algorithm, kwargs in transform_algorithms:
- print(title + '...')
- reconstructions[title] = face.copy()
- t0 = time()
- dico.set_params(transform_algorithm=transform_algorithm, **kwargs)
- code = dico.transform(data)
- patches = np.dot(code, V)
- patches += intercept
- patches = patches.reshape(len(data), *patch_size)
- if transform_algorithm == 'threshold':
- patches -= patches.min()
- patches /= patches.max()
- reconstructions[title][:, width // 2:] = reconstruct_from_patches_2d(
- patches, (height, width // 2))
- dt = time() - t0
- print('done in %.2fs.' % dt)
- show_with_diff(reconstructions[title], face,
- title + ' (time: %.1fs)' % dt)
- plt.show()
第3行:提取照片中被污染过的右半部进行字典学习。
第10~16行:四中不同的字典表示策略
第23行:通过set_params对第二阶段的参数进行设置
第24行:transform根据set_params对设完参数的模型进行字典表示,表示结果放在code中。code总共有100列,每一列对应着V中的一个字典元素,所谓稀疏性就是code中每一行的大部分元素都是0,这样就可以用尽可能少的字典元素表示回去。
第25行:code矩阵乘V得到复原后的矩阵patches
第28行:将patches从(94500,49)变回(94500,7,7)
第32行:通过reconstruct_from_patches_2d函数将patches重新拼接回图片
该程序输出为四中不同转换算法下的降噪效果:





