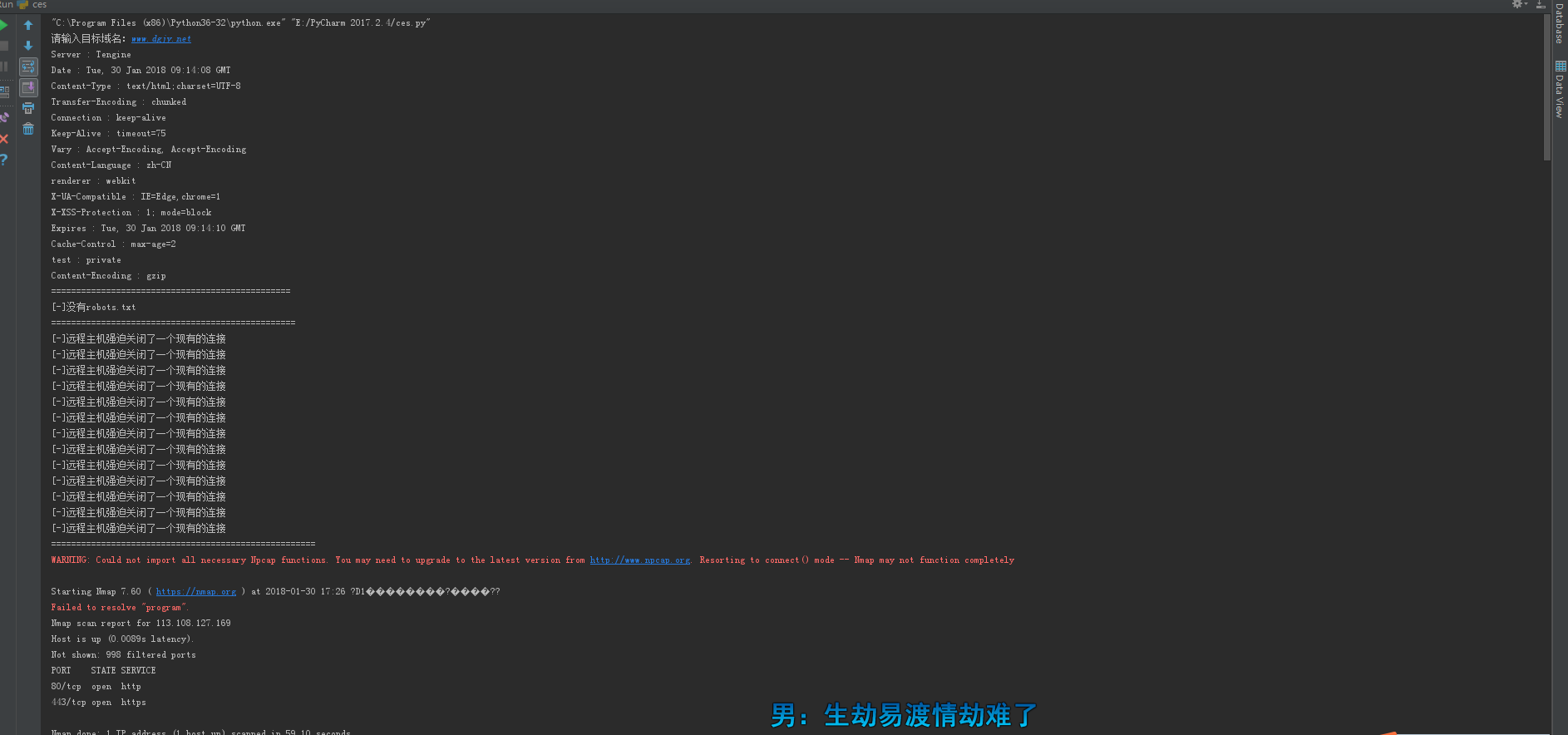
python web指纹获取加目录扫描加端口扫描加判断robots.txt
前言:
总结上几次的信息收集构造出来的。
0x01:
首先今行web指纹识别,然后在进行robots是否存在。后面是目录扫描
然后到使用nmap命令扫描端口。(nmap模块在windows下使用会报停止使用的鬼鬼)
0x02:
代码:
import requests
import os
import socket
from bs4 import BeautifulSoup
import time
def Webfingerprintcollection():
global lgr
lgr=input('请输入目标域名:')
url="http://{}".format(lgr)
header={'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
r=requests.get(url,headers=header)
xyt=r.headers
for key in xyt:
print(key,':',xyt[key])
Webfingerprintcollection()
print('================================================')
def robots():
urlsd="http://{}/robots.txt".format(lgr)
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
gf=requests.get(urlsd,headers=header,timeout=8)
if gf.status_code == 200:
print('robots.txt存在')
print('[+]该站存在robots.txt',urlsd)
else:
print('[-]没有robots.txt')
robots()
print("=================================================")
def Webdirectoryscanner():
dict=open('build.txt','r',encoding='utf-8').read().split('\n')
for xyt in dict:
try:
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
urljc="http://"+lgr+"{}".format(xyt)
rvc=requests.get(urljc,headers=header,timeout=8)
if rvc.status_code == 200:
print('[*]',urljc)
except:
print('[-]远程主机强迫关闭了一个现有的连接')
Webdirectoryscanner()
print("=====================================================")
s = socket.gethostbyname(lgr)
def portscanner():
o=os.system('nmap {} program'.format(s))
print(o)
portscanner()
print('======================================================')
def whois():
heads={'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
urlwhois="http://site.ip138.com/{}/whois.htm".format(lgr)
rvt=requests.get(urlwhois,headers=heads)
bv=BeautifulSoup(rvt.content,"html.parser")
for line in bv.find_all('p'):
link=line.get_text()
print(link)
whois()
print('======================================================')
def IPbackupdomainname():
wu=socket.gethostbyname(lgr)
rks="http://site.ip138.com/{}/".format(wu)
rod={'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
sjk=requests.get(rks,headers=rod)
liverou=BeautifulSoup(sjk.content,'html.parser')
for low in liverou.find_all('li'):
bc=low.get_text()
print(bc)
IPbackupdomainname()
print('=======================================================')