
web-harvest 编写脚本 读取 百度 博客 实例
web-harvest简介:
Web-Harvest 是一个用Java 写的开源的Web 数据提取工具。它提供了一种从所需的页面上提取有用数据的方法。为了达到这个目的,你可能需要用到如XSLT,XQuery,和正则表达式等操作text/xml 的相关技术。Web-Harvest 主要着眼于目前仍占大多数的基于HMLT/XML 的页面内容。另一方面,它也能通过写自己的Java 方法来轻易扩展其提取能力。
Web-Harvest 的主要目的是加强现有数据提取技术的应用。它的目标不是创造一种新方法,而是提供一种更好地使用和组合现有方法的方式。它提供了一个处理器集用于处理数据和控制流程,每一个处理器被看作是一个函数,它拥有参数和执行后同样有结果返回。而且处理是被组合成一个管道的形式,这样使得它们可以以链式的形式来执行,此外为了更易于数据操作和重用,Web-Harvest 还提供了变量上下方用于存储已经声明的变量。
web-harvest 启动,可以直接双击jar包运行,不过该方法不能指定web-harvest java虚拟机的大小。第二种方法,在cmd下切到web-harvest的目录下,敲入命令“java -jar -Xms400m webharvest_all_2.jar” 即可启动并设置起java虚拟机大小为400M。
翻看博文的时候看到之前写的这个了,是帮大学生在线写的,整个项目组成员来自大江南北,也就没问什么时候可以上线,现在把上线后的图贴上来吧,由于个人是实名认证的,所以都擦除了
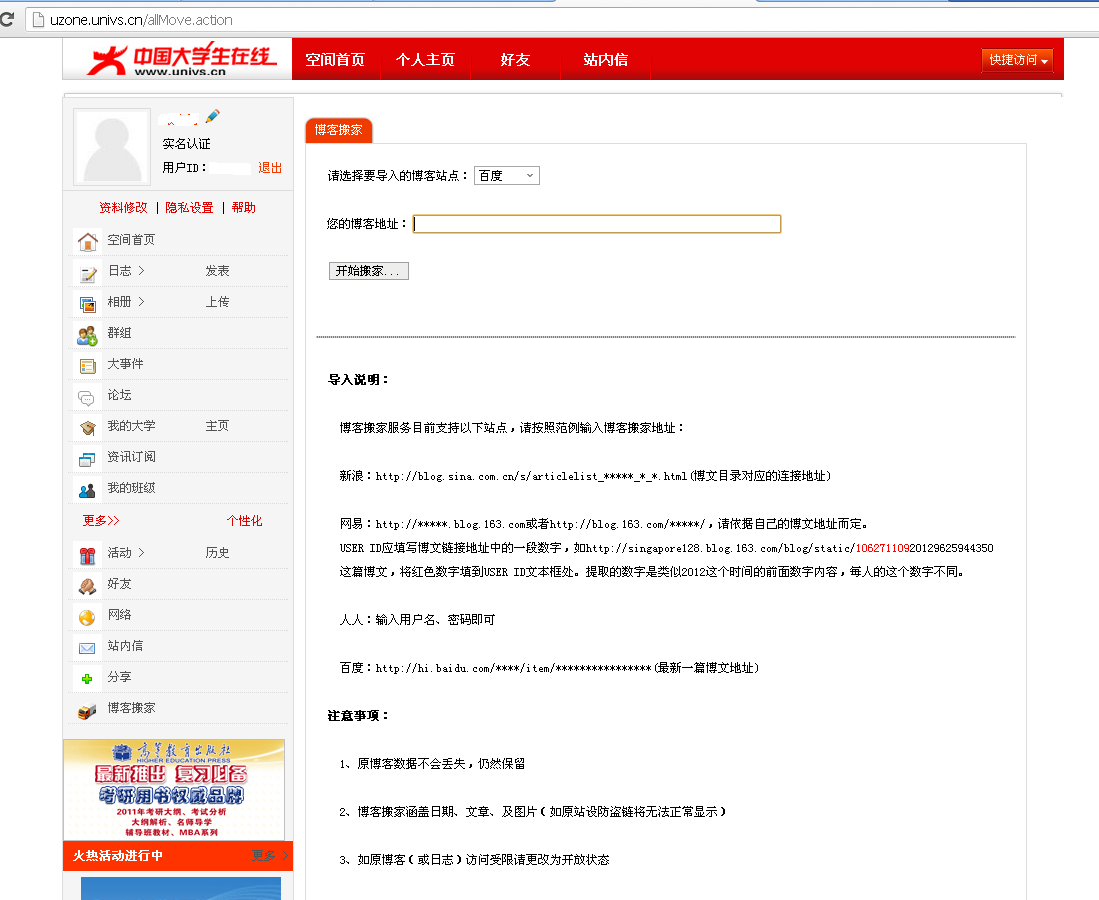
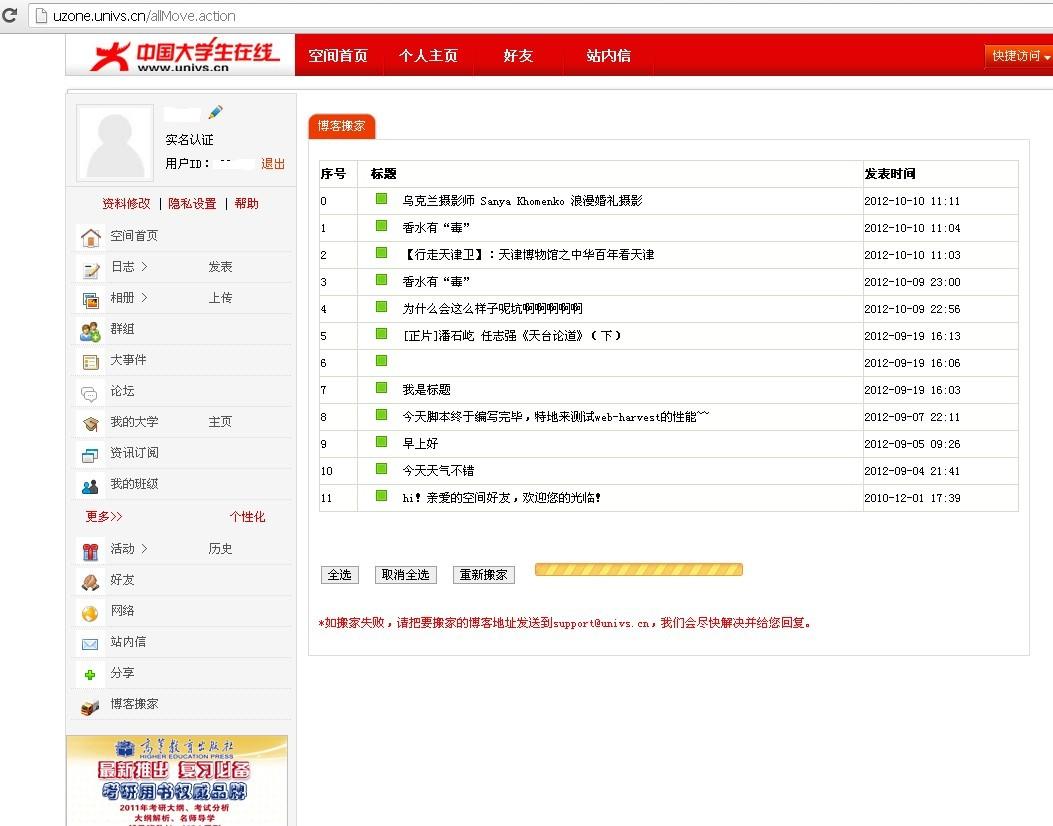
下面是项目的代码:其中用xpath匹配节点xquery获取内容,然后匹配下一篇的链接用html-to-xml获取下一篇,继续上面的循环,整个空间内容就扒下来了
1 <?xml version="1.0" encoding="UTF-8"?> 2 <config charset="UTF-8"> 3 <!-- 4 var-def path 存放路径 5 var-def maxloops 取出数目 填写0则为无限制 取出所有blog 6 var-def nextLinkUrl 第一篇链接 7 --> 8 <var-def name="path">/home/shaopeng/webharvest/axiong2007_12.xml</var-def> 9 <var-def name="maxloops">15</var-def> 10 <var-def name="nextLinkUrl"><template>http://hi.baidu.com/shaopeng1131/item/fc9f240e75f8eed0dde5b07a</template></var-def> 11 <file action="write" path="${path}" charset="utf-8"> 12 <![CDATA[ 13 <?xml version="1.0" encoding="UTF-8"?> 14 <bolgList> 15 16 ]]> 17 </file> 18 19 <while condition="${nextLinkUrl.toString().length() != 0}" maxloops="${maxloops}" index="i"> 20 <empty> 21 <var-def name="content"> 22 <html-to-xml> 23 <http url="${nextLinkUrl}" charset="utf8"/> 24 </html-to-xml> 25 </var-def> 26 <var-def name="pageUrl"> 27 <var name="nextLinkUrl"/> 28 </var-def> 29 <var-def name="nextLinkUrl"> 30 <xpath expression="//div[@class='detail-nav-pre']/a/@href"> 31 <var name="content"/> 32 </xpath> 33 </var-def> 34 </empty> 35 <var-def name="ulList"> 36 37 <xpath expression="//div[@class='mod-blogpage-wraper']"> 38 <var name="content"/> 39 </xpath> 40 </var-def> 41 <loop item="item" index="i"> 42 <list><var name="ulList"/></list> 43 <body> 44 <file action="append" path="${path}" charset="utf-8"> 45 46 <xquery> 47 <xq-param name="blogURL" type="string"> 48 <var name= "pageUrl"/> 49 </xq-param> 50 <xq-param name="item" type="node()"><var name="item"/></xq-param> 51 <xq-expression><![CDATA[ 52 declare variable $item as node() external; 53 declare variable $blogURL as xs:string+ external; 54 let $date := data($item//div[@class='content-other-info']/span/text()) 55 let $title := data($item//h2[@class='title content-title']/text()) 56 let $content := data($item//div[@id='content']) 57 58 return 59 <blog> 60 <blogURL>{data($blogURL)}</blogURL> 61 <blogTitle>{data($title)}</blogTitle> 62 <blogDate>{data($date)}</blogDate> 63 <blogContent>{data($content)}</blogContent> 64 </blog> 65 66 ]]></xq-expression> 67 </xquery> 68 </file> 69 </body> 70 </loop> 71 </while> 72 <file action="append" path="${path}" charset="utf-8"><![CDATA[ 73 </bolglist> ]]></file> 74 </config>
下面是测试出来的结果:http://hi.baidu.com/new/shaopeng1131
<?xml version="1.0" encoding="UTF-8"?> <bolgList><blog> <blogURL>http://hi.baidu.com/shaopeng1131/item/09c4dff06e0603ce0dd1c887</blogURL> <blogTitle>今天脚本终于编写完毕,特地来测试web-harvest的性能~~</blogTitle> <blogDate>2012-09-07 22:11</blogDate> <blogContent> 经历了这么多天我写的脚本终于可以上阵了,虽然有的地方还是不太好 比如图片不支持,等等一系列问题, 好在可以备份文字内容了, 有需要的可以和我说一声哈~~, 帮你把所有的博客下载下来 </blogContent> </blog><blog> <blogURL>http://hi.baidu.com/shaopeng1131/item/fc9f240e75f8eed0dde5b07a</blogURL> <blogTitle>早上好</blogTitle> <blogDate>2012-09-05 09:26</blogDate> <blogContent> 早上好啊 </blogContent> </blog><blog> <blogURL>http://hi.baidu.com/shaopeng1131/item/68a77e147edc0d6271d5e8bf</blogURL> <blogTitle>今天天气不错</blogTitle> <blogDate>2012-09-04 21:41</blogDate> <blogContent> 今天天气不错今天天气不错 </blogContent> </blog><blog> <blogURL>http://hi.baidu.com/shaopeng1131/item/ec7b2fbb7f68024e2aebe3fd</blogURL> <blogTitle>hi!亲爱的空间好友,欢迎您的光临!</blogTitle> <blogDate>2010-12-01 17:39</blogDate> <blogContent> 亲爱的hier们, 今天是个值得纪念的日子,因为我在百度空间上安了家。 我来自百度空间,很高兴成为空间大家庭的一员,今后我会在空间上用文字、图片、动感影集记录和展示一个最真实的我;我也会与真诚的hier们交流分享我的心情和身边趣闻,我希望能在这里认识新朋友,开始一段新的旅程! 希望大家常来看看,我一定会回访哦^_^!如果觉得不错,就把我加为您的好友吧,我期待认识更多新朋友! 我的主页网址是http://hi.baidu.com/shaopeng1131,欢迎常来! </blogContent> </blog></bolglist>
这是刚刚接触这个行业所进行的第一个项目,虽然那时候啥也不懂,都是在网上找各种介绍,看web-harvest 的文档,花费了好多时间,不过都值得,
仍然有一点儿,就是不知道web-harvest怎么整合进去的,通过web运行后台的程序抓取?
web-harvest下载链接 http://web-harvest.sourceforge.net/download.php
