转载请标明出处http://www.cnblogs.com/haozhengfei/p/c9f211ee76528cffc4b6d741a55ac243.html
FPGrowth算法_挖掘商品之间的关联规则
1.1FPGrowth算法可以做什么?
商品之间关联性强度如何,由三个概念——支持度、置信度、提升度来控制和评价,以下将通过例子介绍这三个概念。
1.2FPGrowth_原理剖析
FP-Growth(频繁模式增长)算法是韩家炜老师在2000年提出的关联分析算法,它采取如下分治策略:将提供频繁项集的数据库压缩到一棵频繁模式树(FP-Tree),但仍保留项集关联信息;该算法和Apriori算法最大的不同有两点:第一,不产生候选集,第二,只需要两次遍历数据库,大大提高了效率。
(1)按以下步骤构造FP-树
(a) 扫描事务数据库D一次。收集频繁项的集合F和它们的支持度。对F按支持度降序排序,结果为频繁项表L。
(b) 创建FP-树的根结点,以“null”标记它。对于D 中每个事务Trans,执行:选择 Trans 中的频繁项,并按L中的次序排序。设排序后的频繁项表为[p | P],其中,p 是第一个元素,而P 是剩余元素的表。调用insert_tree([p | P], T)。该过程执行情况如下。如果T有子女N使得N.item-name = p.item-name,则N 的计数增加1;否则创建一个新结点N将其计数设置为1,链接到它的父结点T,并且通过结点链结构将其链接到具有相同item-name的结点。如果P非空,递归地调用insert_tree(P, N)。
(2)FP-树的挖掘
通过调用FP_growth(FP_tree, null)实现。该过程实现如下:
FP_growth(Tree, α)
(1) if Tree 含单个路径P then
(2) for 路径 P 中结点的每个组合(记作β)
(3) 产生模式β ∪ α,其支持度support = β中结点的最小支持度;
(4) else for each ai在Tree的头部(按照支持度由低到高顺序进行扫描) {
(5) 产生一个模式β = ai ∪ α,其支持度support = ai .support;
(6) 构造β的条件模式基,然后构造β的条件FP-树Treeβ;
(7) if Treeβ ≠ ∅ then
(8) 调用 FP_growth (Treeβ, β);}
end
1.1.3 FP-Growth算法演示—构造FP-树
(1)事务数据库建立
原始事务数据库如下:
|
Tid |
Items |
|
1 |
I1,I2,I5 |
|
2 |
I2,I4 |
|
3 |
I2,I3 |
|
4 |
I1,I2,I4 |
|
5 |
I1,I3 |
|
6 |
I2,I3 |
|
7 |
I1,I3 |
|
8 |
I1,I2,I3,I5 |
|
9 |
I1,I2,I3 |
扫描事务数据库得到频繁1-项目集F。
|
I1 |
I2 |
I3 |
I4 |
I5 |
|
6 |
7 |
6 |
2 |
2 |
定义minsup=20%,即最小支持度为2,重新排列F。
|
I2 |
I1 |
I3 |
I4 |
I5 |
|
7 |
6 |
6 |
2 |
2 |
重新调整事务数据库。
|
Tid |
Items |
|
1 |
I2, I1,I5 |
|
2 |
I2,I4 |
|
3 |
I2,I3 |
|
4 |
I2, I1,I4 |
|
5 |
I1,I3 |
|
6 |
I2,I3 |
|
7 |
I1,I3 |
|
8 |
I2, I1,I3,I5 |
|
9 |
I2, I1,I3 |
(2)创建根结点和频繁项目表

(3)加入第一个事务(I2,I1,I5)
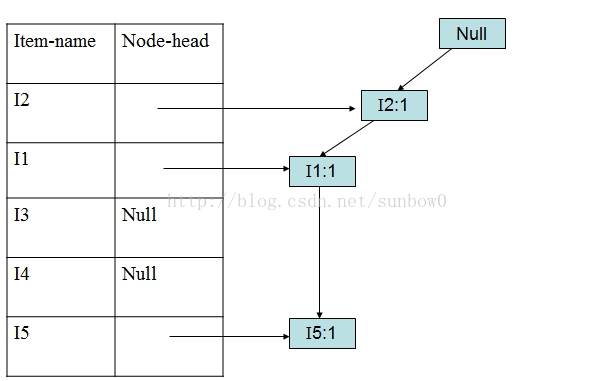
(4)加入第二个事务(I2,I4)

(5)加入第三个事务(I2,I3)

以此类推加入第5、6、7、8、9个事务。
(6)加入第九个事务(I2,I1,I3)
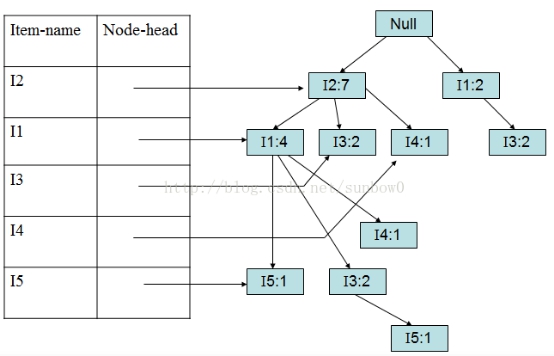
1.1.4 FP-Growth算法演示—FP-树挖掘
FP-树建好后,就可以进行频繁项集的挖掘,挖掘算法称为FpGrowth(Frequent Pattern Growth)算法,挖掘从表头header的最后一个项开始,以此类推。本文以I5、I3为例进行挖掘。
(1)挖掘I5:
对于I5,得到条件模式基:<(I2,I1:1)>、<I2,I1,I3:1>
构造条件FP-tree:
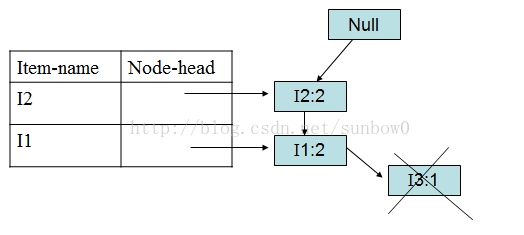
得到I5频繁项集:{{I2,I5:2},{I1,I5:2},{I2,I1,I5:2}}
I4、I1的挖掘与I5类似,条件FP-树都是单路径。
(1)挖掘I3:
I5的情况是比较简单的,因为I5对应的条件FP-树是单路径的,I3稍微复杂一点。I3的条件模式基是(I2 I1:2), (I2:2), (I1:2),生成的条件FP-树如下图:

I3的条件FP-树仍然是一个多路径树,首先把模式后缀I3和条件FP-树中的项头表中的每一项取并集,得到一组模式{I2 I3:4, I1 I3:4},但是这一组模式不是后缀为I3的所有模式。还需要递归调用FP-growth,模式后缀为{I1,I3},{I1,I3}的条件模式基为{I2:2},其生成的条件FP-树如下图所示。
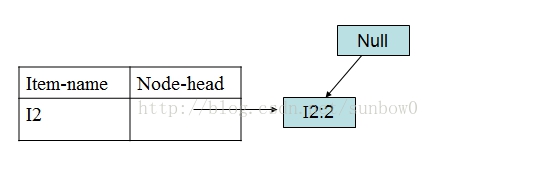
在FP_growth中把I2和模式后缀{I1,I3}取并得到模式{I1 I2 I3:2}。
理论上还应该计算一下模式后缀为{I2,I3}的模式集,但是{I2,I3}的条件模式基为空,递归调用结束。最终模式后缀I3的支持度>2的所有模式为:{ I2 I3:4, I1 I3:4, I1 I2 I3:2}。
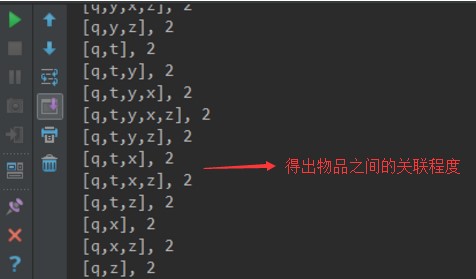
1.3FPGrowth_code


1 import org.apache.log4j.{Level, Logger} 2 import org.apache.spark.{SparkConf, SparkContext} 3 import org.apache.spark.mllib.fpm.FPGrowth 4 import org.apache.spark.rdd.RDD 5 6 /** 7 * Created by hzf 8 */ 9 object FPGrowth_new { 10 // E:\IDEA_Projects\mlib\data\FPgrowth\train\sample_fpgrowth.txt E:\IDEA_Projects\mlib\data\FPgrowth\model 0.2 10 local 11 def main(args: Array[String]) { 12 Logger.getLogger("org.apache.spark").setLevel(Level.ERROR) 13 if (args.length < 5) { 14 System.err.println("Usage: FPGrowth <inputPath> <modelPath> <support> <partitions> <master> [<AppName>]") 15 System.exit(1) 16 } 17 val appName = if (args.length > 5) args(5) else "FPGrowth" 18 val conf = new SparkConf().setAppName(appName).setMaster(args(4)) 19 val sc = new SparkContext(conf) 20 val data = sc.textFile(args(0)) 21 val transactions: RDD[Array[String]] = data.map(s => s.trim.split(' ')) 22 val fpg = new FPGrowth().setMinSupport(args(2).toDouble).setNumPartitions(args(3).toInt) 23 val model = fpg.run(transactions) 24 model.freqItemsets.collect().foreach { itemset => 25 println(itemset.items.mkString("[", ",", "]") + ", " + itemset.freq) 26 } 27 model.freqItemsets.saveAsTextFile(args(1)) 28 } 29 }
E:\IDEA_Projects\mlib\data\FPgrowth\train\sample_fpgrowth.txt E:\IDEA_Projects\mlib\data\FPgrowth\model 0.2 10 local