新手学信息检索2:倒排表与存储
这篇就说一个信息检索里面理解最简单的一个东西吧,它就叫做倒排表或者倒排索引。但是这只是个名字,我想大家都知道它是什么就行了,不必纠结于名称。先说说倒排表张什么样子吧!
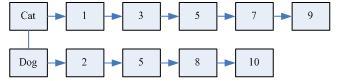
倒排表以词做索引,内容为包含该词的文档编号。对于上图可知,文档1、3、5、7、9包含词"Cat",文档2、5、8、10包含词"Dog"。你可能问这么简单的东西能干啥?其实他就是搜索引擎中的最关键的核心数据结构。那么搜索引擎如何根据用户的查询来找到相关的文档呢?如果用户查询“Cat”,那么只要顺着Cat链把文档1、3、5、7、9返回给用户就行了。如果用户想得到同时包含“Cat”与“Dog“的文档怎么办?这个过程就类似于我们归并排序时合并两个有序段的过程,利用两个指针分别指向Cat链的第一个元素和Dog链的第一个元素,之后通过比较两个指针处文档编号的大小进行相应的移动,找到两个链中共同的文档。整个过程的时间复杂度是线性的。上面介绍的是一种简化版的倒排表,实际搜索引擎中使用的倒排表要比这个复杂一些,也有可能使用多个不同的倒排表来完成不同的搜索任务,但是本质上都差不多。
那么如何建立这个倒排表呢?其实大概过程很简单:提出文档中的每一个词,并把该文档编号插入到该词索引的链上。这里的主要问题在于提取词上,英文文档词与词之间是由空格以及标点符号隔开的,但是汉语里面没有这么明显的分割标志,所以有一门学问叫做自然语言处理,里面专门研究了汉语的分词方法,现在的大多数分词方法都能够达到90%多的正确率。
对于逻辑上这么容易理解倒排表,在实际上实现并不容易。除了分词外,不容易就不容易在这个倒排表的规模将是相当之大,以至于一台计算机的内存空间甚至一台计算机的磁盘空间都不足以存下整个倒排表。实际中的搜索引擎索引的网页数目可达到百亿,以每个网页平均1000个词来计算,每个文档编号按照4字节整数来存储,那么粗略算下来倒排表也至少需要10000000000*1000*4B=40TB的存储空间,那么对于怎么存储这个倒排表确实是一个棘手的问题。
解决大数据存储的形式有两种,一种是分布式存储,一种是压缩。前一种方式很好理解,意思就是一台机器存不下的东西,那么就把它存在多台机器上,这里面也需要有一些复杂的技术。当然,如果倒排表存储在多台机器上,对用户的请求的处理也就变得复杂了一些。后一种压缩技术就是把数据的规模变小,用更加紧凑的表现形式对源数据进行表示,达到内容不变但是存储空间变小的目的,实际中我们常用的压缩软件就是这个道理。比如Linux下的Gzip利用的就是LZ77算法和哈夫曼曼编码来对任意的二进制数据进行压缩的。
分布式存储本人不太了解,所以这些技术的介绍就得大家自己找找园子里的牛人的博客了。而数据压缩相对比较简单,本文就介绍一下倒排表的压缩算法。有人会说,那用现成的压缩工具对倒排表压缩不就可以了吗?虽然可以减少倒排表的存储空间,但是这种平时用的压缩工具压缩出的数据的访问效率比较低。
例如:“我是中国人”在Gzip压缩之后,在压缩数据中找是否有“中”字,你就不得不把所有的数据解压之后才能得到。如果是在压缩之后的倒排表中去找一个文档,那么不得不把倒排表全部解压,而这个解压过程本身就是一个费时的过程,所以不划算。
现在回到倒排表的压缩问题上来,解决一个问题必须理论联系实际才能得到令人满意的效果。
在介绍倒排表数据压缩算法之前,先介绍几个常用的技术,也能够有效的减少倒排表的大小。
这里先从实际应用背景作为切入点来优化倒排表。这个系统是给人用的,那么一个人会输入什么样的查询词呢?
对于英文来说,会不会有人去查”the”,”a”, “an”等等这些词?显然这些词没有什么实际意义。人们往往更喜欢查询一些名字、动词。所以倒排表没有必为”the”,”a”, “an”这些词建立索引,这样倒排表的规模会明显减少不小。”the”, “a”, “an”这种词叫做停用词。有人专门去研究什么样的词可以当成停用词,以至于找到了几百个可以认为是停用词的词。而这些词我们会经常用到。大家可以随便找一篇英文文章,把其中所有的停用词去掉,之后看看还有多少个词。所以不对停用词做索引能够有效减少倒排表的大小。汉语也有相应的停用词表,所以这个技术对中文检索也同样适用。
还有一个技术叫做词干化。这个技术貌似只对欧洲的文字才有作用,对汉字作用不大。这里也介绍一下。比如单词“cars”是“car”的复数形式,但是对于我们来说这两个词的意思都一样,所以把“cars”用“car”代替是一个好方法。“car”可以认为是“cars”的词干。实际上一个词的单复数、时态等都能够进行词干化。这种方法甚至比去除停用词的效果还要好。大家也可以试试随便找一篇文章,之后把所有的词都词干化看看还有多少个不同的词。和上面的技术一样,也有人专门研究英文单词的词干化,提供词干化的服务。
以上两个技术联合起来用就可以很大程度上的减少倒排表的大小,虽然这两个技术也对检索带来些负面的问题,但是始终认为利大于弊。
现在回到正题,如果利用了上面两个方法后,倒排表还是很大怎么办?那么压缩算法开始上场了。这里我们不使用Gzip等复杂的算法,由于倒排表的形式简单,所以对简单的问题有着简单的解决方法。
文档数目必须用4字节整数表示,但是一个索引之中的文档编号相邻间隔不会太大,可以用少于4字节表示。例如,如果我们确定文档编号间隔不会超过两个字节表示的范围,那么对于一个倒排表我们只把第一个文档编号用4字节表示,其它的用2字节间隔来表示,这种方法可以使倒排表的大小为原来的一半。如本文一开始给的数字来说,倒排表大小可以由40TB变成20TB。上面给这个思想可行也很诱人,只不过还存在一个必须解决的问题:文档间隔有可能和文档编号是一个量级的,用两字节无法表示。
下面介绍一种可变字节编码方式:利用整数个字节对文档间隔进行编码。每个字节的第1个比特代表延续位,后7个比特代表编码比特。如果第一个比特位1,代表这个字节是编码的最后一个字节,否则不是最后一个字节。
例如:
5表示成可变字节编码二进制形式为: 10000101
214577表示成可变字节编码二进制形式为: 00001101 00001100 10110001。
对于第二个例子给出其还原方式:拿出每个字节的低七位组合得到一个21比特二进制数,这个数字就是214577。这种编码方式的编解码过程都非常简单,而且时间开销很小,相比于Gzip这种方法要好的多。
这种编码方式出奇的简单,以致于你认为它的实际效果能好到哪去。有人在权威的文档集合(大概包含800000篇文档)上构建倒排表,原始大小为250MB,而经过变长编码得到的倒排表大小只有116MB。要解释这种现象就可能需要Zipf定律了,这个定律大家可以有兴趣查一查。
除了可变长编码,还有诸如γ编码等等,这些编码方式操作存储单元的粒度要比一个字节要小,所以编码方式比可变长编码复杂,能得到更好的理论压缩效率和实际压缩效率。但是同样在这800000文档机上构建倒排表,编码使倒排表的大小变为101MB,仅仅比可变长编码少13%。
假设通过词干化,去除停用词能够使倒排表大小降低1/10,之后可变长编码又使倒排表大小降低1/2,那么现在我们的倒排表大小就为18TB左右了。虽然这么大的数据还是得需要分布式存储的方法,但是这样可以减少对机器数量的需求,是比较节省成本的。而对于一个程序员来说,想要做一个单台机器索引几百万网页的搜索引擎来说,也是一件可能的事了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号