SQLServer查询和删除表中重复数据;SQLServer 一列或多列重复数据的查询和删除;SQLServer分组去重
业务需求
最近给公司做一个小工具,把某个数据库(数据源)的数据导进另一个数据(目标数据库)。要求导入目标数据库的数据不能出现重复。但情况是数据源本身就有重复的数据。所以要先清除数据源数据。
于是就把关于重复数据的查询和处理总结一下。这里只可虑基于数据库解决方案。不考虑程序的实现。
环境为:SQL Server 2008
基于数据库的解决方案
数据库测试表dbo.Member
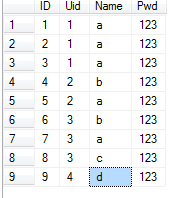
一、单列重复
一,带有having条件的分组查询方法
(1)查询某一列重复记录
语句:
SELECT Name FROM dbo.Member t WHERE Name IN (SELECT Name FROM dbo.Member GROUP BY Name HAVING COUNT(Name)>1 ) ORDER BY t.Name
查询结果:

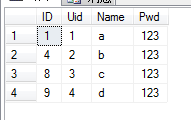
(2)查询某一列不重复的记录
语句:
SELECT * FROM dbo.Member WHERE ID IN (SELECT MIN(ID) FROM dbo.Member GROUP BY Name)
查询结果:
(3)清除某一列重复的数据
语句:
DELETE FROM dbo.Member WHERE ID NOT IN (SELECT MIN(ID) FROM dbo.Member GROUP BY Name)
执行结果:
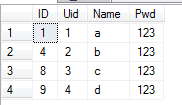
解释:上面的例子只保存了各自Name的最小值。
二,DISTINCT 的用法
温馨提醒:
不支持多列统计
Oracle和DB2数据库也适用
利用distinct关键字返回唯一不同的值
(1)查询某一列不重复数据
语句:
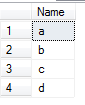
SELECT DISTINCT Name FROM dbo.Member
结果集:
(2)DISTINCT 查询多列不重复(如果查询的列有任何一个不重复,则这条记录视为不重复)
语句:
SELECT DISTINCT Name,Uid FROM dbo.Member
查询结果

DISTINCT 用于统计
语句
SELECT COUNT(DISTINCT(Name)) FROM dbo.Member
(3)sql分组去重
转载来源:https://blog.csdn.net/weixin_35750483/article/details/129077221
例如,假设有一张名为 orders 的表,其中有两个字段:customer_id 和 product_id。要查询每个客户订购的不同的产品数量,可以使用以下查询:
SELECT customer_id, COUNT(DISTINCT product_id)
FROM orders
GROUP BY customer_id;
这个查询会对每个 customer_id 分组,并统计每组内不同的 product_id 的数量。
要注意,如果在 SELECT 中使用了 DISTINCT 关键字,它会在整个查询结果中去除重复行。因此,如果要去重,应该将 DISTINCT 放在聚合函数(如 COUNT)的参数中,而不是将它放在 SELECT 中。
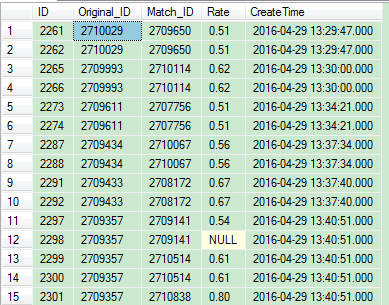
二、多列重复
数据表结构
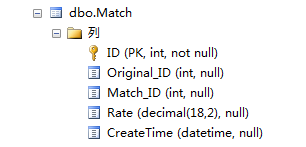
查找Original_ID和Match_ID这两列值重复的行
SQL语句
SELECT m.* FROM dbo.Match m,(
SELECT Original_ID,Match_ID
FROM dbo.Match
GROUP BY Original_ID,Match_ID
HAVING COUNT(1)>1
) AS m1
WHERE m.Original_ID=m1.Original_ID AND m.Match_ID=m1.Match_ID
查询结果