
.Net程序员学用Oracle系列(19):导出、导入(备份、还原)
- 1、传统的导出/导入工具
- 1.1、EXP 命令详解
- 1.2、IMP 命令详解
- 1.3、EXP/IMP 使用技巧
- 2、新的导出/导入工具
- 2.1、EXPDP/IMPDP 参数说明
- 2.2、EXPDP/IMPDP 用法示范
- 3、其它导出/导入工具
- 3.1、RMAN
- 3.2、PL/SQL Developer
- 4、总结
我曾开发过某著名医院的 EMR,某天,实验室里单剩我一人,恰好也没啥事儿,想到自己接触 Oracle 好几个月了,却还不知道怎么备份数据库。我原以为 Oracle 中会有像 SQL Server 中备份和还原之类的图形化功能,结果那天悲催的我几乎把 Oracle 和 PL/SQL Developer 中的所有菜单选项都点了个遍,愣是没找着备份功能在哪儿!(当然,实验室里是不能上网的,否则我指定不能这么找啊!)
后来我才逐渐明白,在 Oracle 中根本就没有“备份功能”这一说!Oracle 官方提供了导出工具和导入工具,作用相当于 SQL Server 中的备份功能和还原功能,用于逻辑备份和逻辑还原,但都是命令行工具(安装、使用等的方法与 SQL Plus 相同),并没有图形化的功能。而 PL/SQL Developer 倒是提供了导出用户对象、导出表和导入表等功能,不过我当时完全没把这些功能和备份还原联系到一块儿去。
1、传统的导出/导入工具
导出工具(Export)和导入工具(Import)是 Oracle 很久以前就开始提供的数据提取和加载工具。导出工具的任务是创建一个平台独立的转储文件(后缀一般用.dmp),文件中包含所有必要的元数据,可能还有数据本身,可用于重新创建表、模式甚至整个数据库。转储文件是二进制文件,可以从中抽取信息,但不能用任何文本编辑器修改它。导入工具的作用就是读取这些转储文件,执行其中的 DDL 语句,并加载它找到的所有数据。
1.1、EXP 命令详解
要求执行导出命令的用户具有 DBA 权限或 EXP_FULL_DATABASE 权限。命令语法:
exp userid=username/password file=file_path [rows=y/n] [full=y/n] [owner=schemas] [tables=tables] [query=sql_where]
参数说明:
- userid:用于指定用户名/密码,格式可以是
username/password、username/password@tnsname或username/password@//host:port/instance_name。该参数必须是命令行的第一个参数,参数名可以省略,事实上我一般都会省略。 - file:用于指定输出文件,可以是全路径,也可以是文件名。只写文件名且以操作系统中某个用户的身份打开 cmd 并执行导出命令时,会把数据库文件导出到该用户的文件夹下。
- rows=y:表示导出数据行(反之只导出数据结构),默认导出数据行。
- full=y:表示全库导出(元数据和数据都会被导出),默认非全库导出。
- owner:用于指定要导出那些用户的对象,可以写一个或多个 SCHEMA,若有多个,以逗号分割,且要用一对小括号包裹整个列表。
- tables:用于指定要导出那些表,可以写一个或多个表名,若有多个,以逗号分割,且要用一对小括号包裹整个列表。
- query:用于指定要导出的那些数据行,其实也就是 SQL 语句的 WHERE 条件。
注意:full、owner、tables 这 3 个参数至多可出现 1 个,否则会发生错误——“EXP-00026:指定了冲突模式”。
示例 1,导出全库:
exp demo/test file=d:\example1.dmp full=y
示例 2,导出用户的对象和数据:
exp demo/test file=d:\example2.dmp owner=demo (仅 demo 用户)
exp demo/test file=d:\example2.dmp (所有用户)
示例 3,导出 demo.t_staff 表和 demo.t_course 表:
exp demo/test file=d:\example3.dmp tables=(demo.t_staff,demo.t_course)
示例 4,导出 demo.staff 表中 90 后用户数据:
exp demo/test file=d:\example4.dmp tables=demo.t_staff query=\" WHERE birthday>=TO_DATE('1990-01-01','yyyy-mm-dd')\"
1.2、IMP 命令详解
要求执行导入命令的用户具有 DBA 权限或 IMP_FULL_DATABASE 权限。命令语法:
imp userid=username/password file=file_path [rows=y/n] [ignore=y/n] [full=y/n] [fromuser=user] [touser=user] [tables=tables]
参数说明:
- ignore=y:表示忽略创建(对象的)错误,默认不忽略。
- fromuser:用于指定要导入那些用户的对象,可以写一个或多个 SCHEMA,若有多个,以逗号分割,且要用一对小括号包裹整个列表。
- touser:用于指定要把对象导给那些用户,可以写一个或多个 SCHEMA,若有多个,以逗号分割,且要用一对小括号包裹整个列表。
注意:
- 除 ignore、fromuser 和 touser 外,其它参数的含义和语法请参考 EXP 命令详解。
- full、fromuser、tables 这 3 个参数至少要出现 1 个,否则会发生错误——“IMP-00031:必须指定 FULL=Y 或提供 FROMUSER/TOUSER 或 TABLES 参数”。
- full 不能与 fromuser 或 tables 同时出现,否则会发生错误——“IMP-00024:只能指定一种模式(TABLES,FROMUSER 或 FULL)”。
- tables 参数中的表名不能用 schema.table_name 格式,只能通过 fromuser 参数来指定 SCHEMA。
- 同一个库导出后再导入,需要先把对应的用户、用户对象或表空间等删除后再导入。
示例 1、导入全库:
imp demo/test file=d:\example1.dmp full=y ignore=y
示例 2、导入 demo 用户的对象和数据:
imp demo/test file=d:\example1.dmp fromuser=demo touser=demo ignore=y
imp demo/test file=d:\example1.dmp fromuser=demo ignore=y
示例 3、导入 demo.t_staff 表和 demo.t_course 表:
imp demo/test file=d:\example1.dmp fromuser=demo tables=(t_staff,t_course) ignore=y
imp demo/test file=d:\example1.dmp tables=(t_staff,t_course) ignore=y
1.3、EXP/IMP 使用技巧
写个导出/导入 Oracle 数据库的命令,对 DBA 来说可能只需要几秒钟,So easy!但大多数开发人员是无法做到这一点的,因为他们可能好几个月才用一次导出/导入的命令,很难想起上次是怎么写的。当然,如果这个开发人员有记录问题的习惯,下一次照着笔记敲命令,也能很快搞定。
然而,我这个人是极懒的,既不喜欢记太多东西,也不乐意执行太多机械化(如照抄)的任务。尤其是在用一些我不太喜欢的技术或工具时,我总是尽可能的去寻求更高效的解决方案。我现在负责开发的系统共有 9 个库,有的比较大、有的则很小,如果每次导出/导入都手工写个命令,等它处理玩了再写下一个命令,依次搞定 9 个库的话,显然是即笨又慢还繁琐!我解决这个问题的方法是写两个批处理,一个执行 9 个库的导出,另一个执行 9 个库的导入,需要导出/导入的时候找到对应的批处理双击一下就 OK 了。
导出命令批处理写法:(只写文件名的话,dmp 文件默认会被输出到批处理所属的文件夹里)
set "tnsname=ORCL_127.0.0.1"
exp user1/pwd1@%tnsname% file=user1.dmp owner=user1
exp user2/pwd2@%tnsname% file=user2.dmp owner=user2
exp user3/pwd3@%tnsname% file=user3.dmp owner=user3
pause
导入命令批处理写法:(只写文件名的话,默认会在批处理所属的文件夹里去找 dmp 文件)
set "tnsname=ORCL_127.0.0.1"
imp user1/pwd1@%tnsname% file=user1.dmp fromuser=user1 ignore=y
imp user2/pwd2@%tnsname% file=user2.dmp fromuser=user2 ignore=y
imp user3/pwd3@%tnsname% file=user3.dmp fromuser=user3 ignore=y
pause
2、新的导出/导入工具
Oracle 官方称会逐步废弃 Export,新的数据类型、新的结构以及新的特性都未在该工具中得到支持。Oracle 10g R1 中引入了数据泵(Data Pump)技术,并基于这种技术推出了新的导出工具(IMPDP)和导入工具(EXPDP)。由于使用了 XML,数据泵在体系结构和功能上与传统的导出工具和导入工具相比有了显著的提升;又由于使用了并行技术来读写转储文件,数据泵比原来的 EXP/IMP 技术快 15~45 倍。
2.1、EXPDP/IMPDP 参数说明
新的导出工具/导入工具也都是命令行工具,调用的方法与传统的导出工具/导入工具相同,新的命令分别是EXPDP和IMPDP。从表面来看,EXPDP/IMPDP 命令与 EXP/IMP 命令最显著的不同就是参数变复杂了!本节将从与 EXP/IMP 命令对比的角度,讲述我在使用新命令(参数)时的一些心得体会。
-
userid:无变化,用于指定用户名/口令。依然支持 3 种写法,依然必须是第一个参数,依然可以省略参数名不写。
-
directory:新增,供转储文件和日志文件使用的目录对象。新命令产生的转储文件只能被存放在 directory 对象对应的 OS 目录中,不能直接指定转储文件存放的 OS 目录,因此在执行命令之前需要先创建 directory 对象。如要把转储文件存放在 D 盘的 dump 目录,示例:
CREATE OR REPLACE DIRECTORY dump AS 'D:\dump';。至少要确保在执行命令时 D 盘存在名为 dump 目录,因为 EXPDP/IMPDP 不会自动创建 OS 目录。很多帖子里都说创建 directory 对象之后还得给导出账户赋读写权限,示例:GRANT READ, WRITE ON DIRECTORY dump TO demo;。我从未这样赋权也能导出!也许是那些帖子抄袭了相同的错误,当然,也可能是我遗漏了什么。事实上,directory 参数有个默认值:DATA_PUMP_DIR(Oracle 预定义的 directory 对象),当不显示给 directory 参数赋值时,就会启用该默认值。可通过 all_directories 视图查询与 DATA_PUMP_DIR 实际映射的 OS 目录。示例:SELECT t.directory_path FROM all_directories t WHERE t.directory_name='DATA_PUMP_DIR';。 -
dumpfile:新增,目标转储文件名的列表。若不显示指定,默认值为:EXPDAT.DMP。
-
logfile:新增,日志文件名。若不显示指定,默认值为:export.log。
-
nologfile:新增,不写入日志文件。可选值 y/n,默认为 n,表示写入,即自动在转储文件所在的目录创建日志文件。
-
content:新增,指定要卸载的数据。可选值 all/data_only/metadata_only,默认为 all,表示业务数据和元数据都导出。
-
exclude:新增,排除特定类型对象。下面给出几个典型的排除表达式写法供大家参考:
exclude=statistics排除统计信息。exclude=sequence,trigger排除序列和触发器。exclude=table:\"= 'T_STAFF'\"排除T_STAFF表。exclude=table:\"IN ('T_STAFF','T_COURSE')\"排除T_STAFF表和T_COURSE表。exclude=table:\"> 'T'\"排除开头字母大于T的表。exclude=procedure:\"LIKE 'SP_%'\"排除以SP_开头的存储过程。exclude=index,view,table:\"= 'T_STAFF'\"排除索引、视图和T_STAFF表。
-
include:新增,包含特定类型对象。参数值表达式写法请参考 exclude 参数。
-
full:无变化,导出/入整个数据库。可选值 y/n,默认为 n,表示非全库导出/入。
-
schemas:相当于 owner,要导出/入的方案的列表。
-
tables:无变化,标识要导出/入表的列表。
-
query:无变化,用于导出/入表的子集的谓语子句。
-
tablespaces:无变化,标识要导出/入表空间的列表。相对来说比较少用。
-
estimate:新增,计算作业估计值。可选值 blocks/statistics,默认为 blocks,表示通过数据块数量估算,statistics 表示通过统计信息中记录的内容估算。
-
estimate_only:新增(仅导出),在不执行导出的情况下计算作业估计值。
-
parallel:更改当前作业活动的 worker 的数目。
-
job_name:新增,要创建的导出/入作业的名称。
-
remap_schema:新增(仅导入),将一个方案中的对象加载到另一个方案。
-
remap_tablespace:新增(仅导入),讲表空间对象重新映射到另一个表空间。
-
table_exists_action:新增(仅导入),导入对象已存在时执行的操作。可选值 skip/append/truncate/replace。默认为 skip,表示跳过。append 表示在原基础上增加数据,truncate 表示先 truncate 表,再插入数据,replace 表示先 drop 表,再创建表并插入数据。
-
reuse_datafiles:新增(仅导入),如果表空间已存在,则将其初始化。可选值 y/n,默认为 n。
-
sqlfile:新增(仅导入),将所有 DDL 语句写入指定文件。
2.2、EXPDP/IMPDP 用法示范
1、全库导出/导入
expdp demo/test directory=dump dumpfile=dat1.dmp logfile=log1.log full=y
impdp demo/test directory=dump dumpfile=dat1.dmp logfile=log1.log full=y
2、按用户导出/导入
expdp demo/test directory=dump dumpfile=dat2.dmp logfile=log2.log schemas=demo
impdp demo/test directory=dump dumpfile=dat2.dmp logfile=log2.log schemas=demo
3、按表空间导出/导入
expdp demo/test directory=dump dumpfile=dat3.dmp logfile=log3.log tablespaces=users
impdp demo/test directory=dump dumpfile=dat3.dmp logfile=log3.log tablespaces=users
4、按表导出/导入
expdp demo/test directory=dump dumpfile=dat4.dmp logfile=log4.log tables=t_staff,t_course
impdp demo/test directory=dump dumpfile=dat4.dmp logfile=log4.log tables=t_staff,t_course
5、按查询条件导出/导入
expdp demo/test directory=dump dumpfile=dat5.dmp tables=t_staff query=\" WHERE birthday>=TO_DATE('1990-01-01','yyyy-mm-dd')\"
impdp demo/test directory=dump dumpfile=dat5.dmp tables=t_staff query=\" WHERE birthday>=TO_DATE('1990-01-01','yyyy-mm-dd')\"
6、导出 demo 方案,且不写日志
expdp demo/test directory=dump dumpfile=nolog.dmp schemas=demo nologfile=y
7、导出 demo 方案的业务数据
expdp demo/test directory=dump dumpfile=data.dmp logfile=data.log schemas=demo content=data_only
8、在不执行导出的情况下,估算 demo 方案
expdp demo/test directory=dump logfile=estimate.log schemas=demo estimate=statistics estimate_only=y
9、导出 t_staff 表定义
expdp demo/test directory=dump dumpfile=staff.dmp logfile=staff.log tables=t_staff content=metadata_only
10、并行导出 demo 方案,并指定作业名称为 parallel
expdp demo/test directory=dump dumpfile=parallel.dmp logfile=parallel.log schemas=demo parallel=2 job_name=parallel
11、导入前先清空表空间(不可同时指定 reuse_datafiles 和 schemas 或 tablespaces)
impdp demo/test directory=dump dumpfile=dat2.dmp reuse_datafiles=y
12、按用户导入,且把所有 DLL 语句写入 dat2.sql 文件
impdp demo/test directory=dump dumpfile=dat2.dmp schemas=demo sqlfile=dat2.sql
13、也可以把常用的 EXPDP/IMPDP 命令写到批处理文件中,方便日后快速搞定导出/导入。具体操作可参考 EXP/IMP 使用技巧。
3、其它导出/导入工具
其实可以备份/还原 Oracle 的工具有很多,如同为 Oracle 官方提供,DBA 比较钟爱,开发人员却很少会用的物理备份工具 RMAN,著名的 PL/SQL Developer 也集成了相关功能,还有 CA Brightstor、Veritas、Legato Networker 等第三方工具。这些第三方商业工具我也没用过,有兴趣的朋友请自行了解,本节只简要介绍我相对了解(其实此前也没用过)的 RMAN 和 PL/SQL Developer。
3.1、RMAN
RMAN(Recovery Manager) 是用于备份、还原和恢复 Oracle 数据库的工具。RMAN 也是命令行工具,使用方式与导出工具/导入工具相同,不同的是导出(EXP/EXPDP)是逻辑备份,而 RMAN(rman backup)是物理备份。关于 RMAN 的具体命令和参数,我本人也不太熟悉,有兴趣的读者请自行研究。若有关于 RMAN 的好文,欢迎在文末留言给出链接!
3.2、PL/SQL Developer
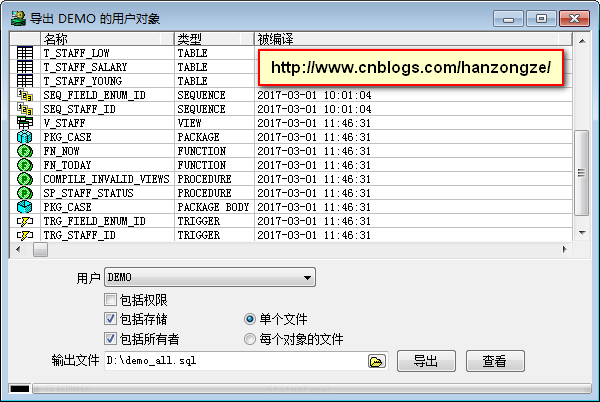
1、导出 DEMO 用户对象,【工具】→【导出用户对象】指定输出文件之后点击导出即可。如下图:
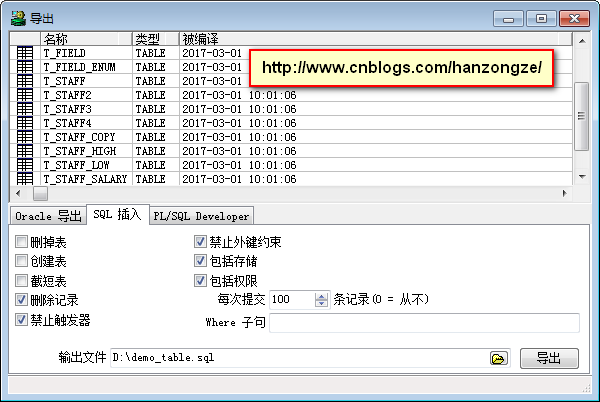
2、导出表数据,【工具】→【导出表】指定输出文件之后点击导出即可。如下图:
3、导入,【工具】→【导入表】指定可执行文件和导入文件之后点击导入即可。如下图:
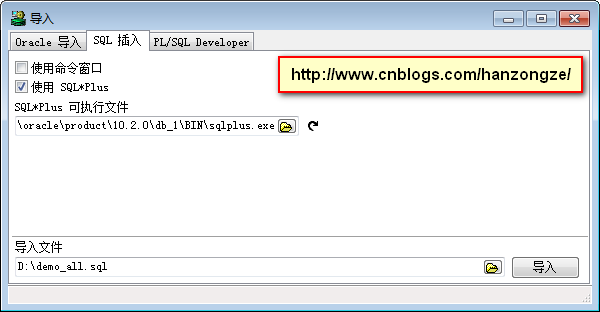
注意:先导入对象定义,再导入表数据。
4、总结
本文主要介绍了用 Oracle 的大多数开发人员日常工作中可能会用到的一些备份工具和使用技巧。无论是 EXP/IMP 还是 EXPDP/IMPDP,如果你想以 sysdba 的身份执行命令,则需要将 userid 的参数值用引号包裹,如userid='sys/test as sysdba'。其实 userid 的参数值也不必非得是uid/pwd格式,还可以只给用户名,如userid=demo,这么写的话,执行该命令的时候命令行工具就会提示你输入密码,只要你输入正确的密码,就会继续执行。
开发人员工作中可能会遇到这样一个典型情况:需要修改某张表的定义,如改字段长度之类的,但有时因为表中已有大量数据就不好直接改了。面对这种情况,大家普遍会想到方法就是先备份表数据,改好之后再还原表数据。当然,导出工具和导入工具绝对可以胜任这个,但其实这种小 case 普通的 SQL 语句就足以搞定,没必要用什么工具。假如现在要修改的是demo.t_staff表,示例:
CREATE TABLE demo.t_staff_backup AS SELECT * FROM demo.t_staff; -- 将`demo.t_staff`表的数据备份至`demo.t_staff_backup`表
INSERT INTO demo.t_staff SELECT * FROM demo.t_staff_backup; -- 将`demo.t_staff_backup`表的数据还原到`demo.t_staff`表
本文链接:http://www.cnblogs.com/hanzongze/p/oracle-export-import.html
版权声明:本文为博客园博主 韩宗泽 原创,作者保留署名权!欢迎通过转载、演绎或其它传播方式来使用本文,但必须在明显位置给出作者署名和本文链接!本人初写博客,水平有限,若有不当之处,敬请批评指正,谢谢!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号