程序员视角:鹿晗公布恋情是如何把微博搞炸的?
作者:13
GitHub:https://github.com/ZHENFENG13
版权声明:本文为原创文章,未经允许不得转载。
微博炸了!
长假的最后一天,躺在床上刷刷微博,想找找搞笑段子乐呵乐呵,玩着玩着微博就卡了起来,起初以为是手机问题,关了应用重新进去还是一样,没办法,只能出去吃饭了,当天应该不止我一个人是这种情况吧,微博卡的不要不要的。当然,后面的事情大家都知道了,中国最历害的黑客竟然在娱乐圈,鹿黑客一句话就黑了大微博(这句话不准确),这次事件IT圈应该无人不识鹿黑客了吧。
微博炸了。
随后微博客服发出公告:
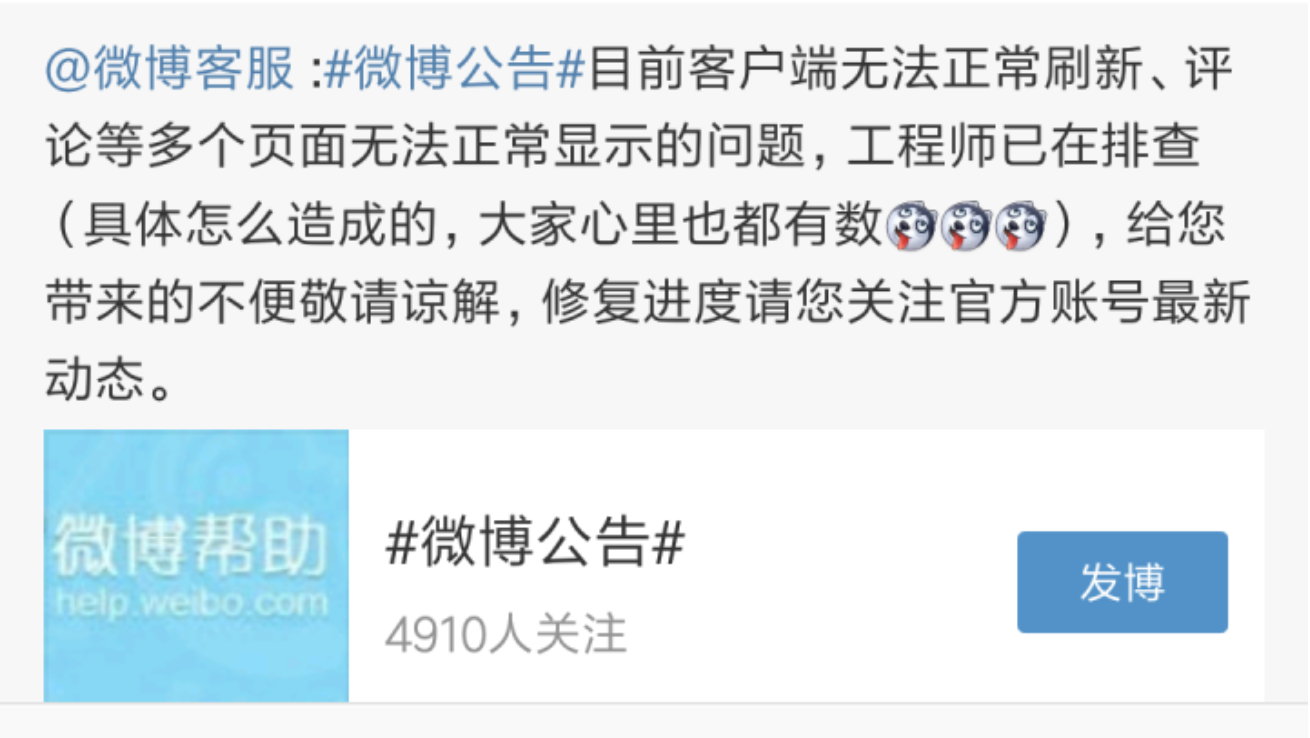
别跑题!
写了几段后发现有点跑题了,技术文章不该这么八卦,就删掉了,哈哈哈哈。
鹿粉丝一片哭天抢地的哀嚎惨相、有人跳楼有人自杀(真假性不确定)、"这是我女朋友"体火遍朋友圈、各种段子层出不穷、吃瓜群众热闹看了个饱、事件的关注度和影响力至今未散....这些我们就不在文章中过多赘述了,毕竟不能跑题,也不能以看热闹的心态去讲这件事,本文主要是讲作为平台方的微博是如何被此次事件所波及的。
印象中微博其实已经挂了好多次了吧,每次一有明星公布一些劲爆的消息都是对微博服务器的考验,也不止一次看到微博的运维朋友们从各种状态中回到公司加班...再次心疼。
微博怎么就炸了?
以下为个人的一些想法,由于知识储备不足所以不能高谈阔论,只能想到什么就写了什么,并没有多少技术含量,如有错误劳烦指出,谢谢勘误。
读操作应该不会拖垮微博
第一个想到的流量问题,被大量请求冲击导致服务器负载过高,一台一台的挂掉了,但是在没有看到微博公布的数据之前,我觉得微博这样的技术架构应该不太可能轻易的被大流量压垮,之前也看到微博技术团队的一些技术分享,宣传他们的服务降级、自动扩容、运维自动化等等之类的文章,以新浪微博这个体量应该不会这么容易就垮了,而且即使服务器负载达到上限,有自动扩容的机制在,应该也可以撑住一段时间,不至于垮了这么久。
这些是一开始的想法的,后面对比微博公布的数据再整理了一下,感觉还是对微博的技术团队有些乐观了,有点过分信任,认为他们无所不能了,但是再优秀的团队也会经历一些意外吧。
数据库出了问题?
否定了第一个想法后,又想到了数据层面,根据当时的微博转发数、评论数、评论的回复数、评论的点赞数及这条微博所关联的其他微博的数据,极大的可能是由于事发当时需要写入数据库的请求太多,写操作到达峰值,以及大部分写都会落到同一条微博(也就是鹿晗的这条微博)上,由于微博的评论设置层级较高,某些写操作还可能会触发其他的写操作,数据库压力过大扛不过来,导致数据库挂了一段时间,根据当时的想法整理了一下草图,(当时画图的时候也没有预料到图中的n竟然是上亿级别的!)
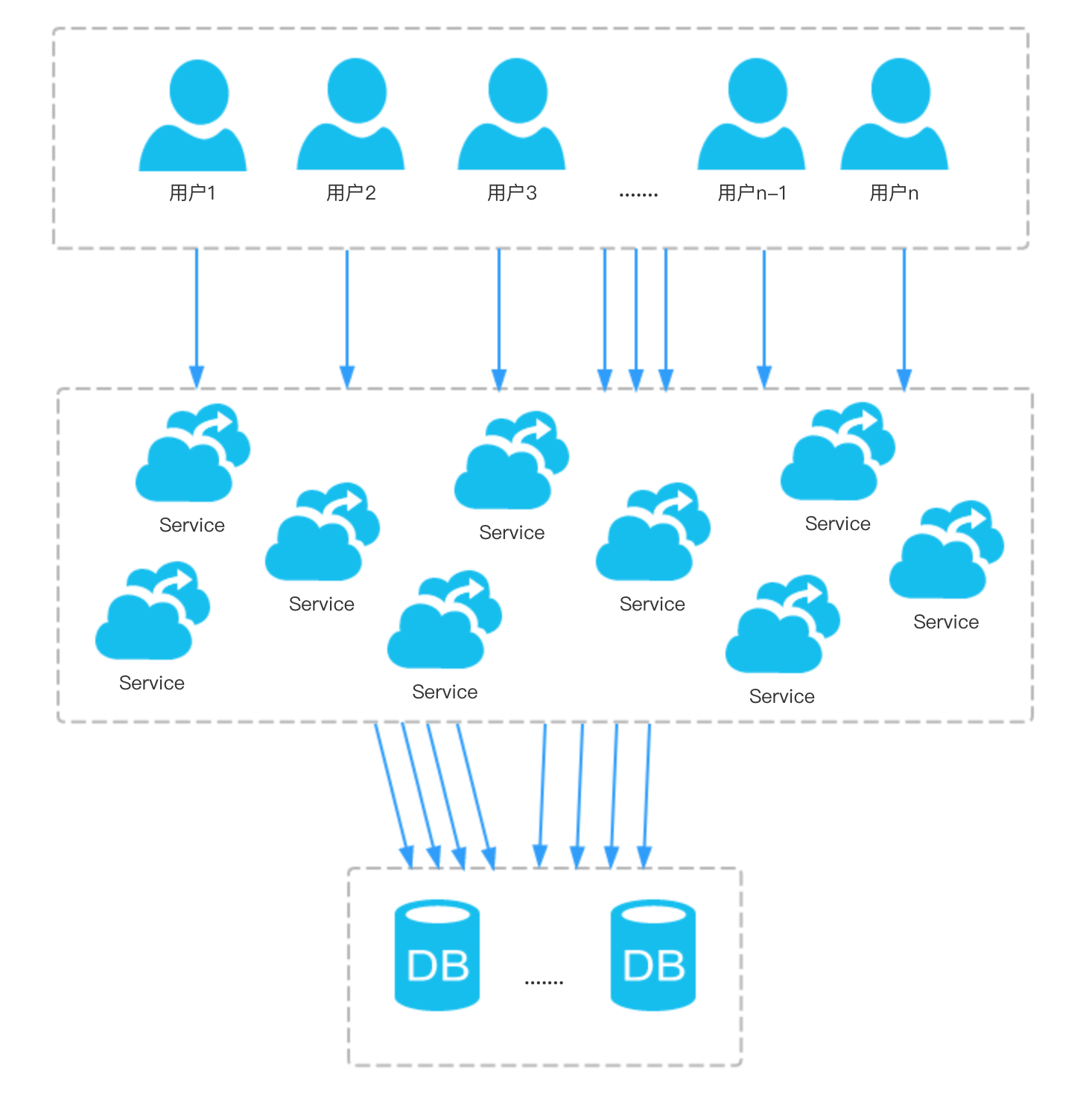
但是微博挂了太久,如果是数据库的问题不可能会导致这么久的服务不可用,而且数据库做了切分及其他的架构优化之后,即使出现问题也不会波及太广,所以这个猜测应该不怎么成立。
缓存或者其他中间件出了问题?
重新缕了一下思路,问题难道在缓存的设计上吗?微博的缓存设计好像一直有些小问题吧,可能是为了服务的高可用及成本考虑刻意舍弃了一些功能,这个就不讨论了。
数据库肯定是出问题了的,但是主要问题应该不是在数据库压力上,毕竟有缓存层,而且评论或者点赞并不一定要完全保证实时性和精准性,有一定的数据丢失和误差也是可以接受的,因此数据库挂掉一段时间是可能存在的,其次,当时无法正常发布评论和点赞,那条微博的评论内容也无法正常显示,比如分页数据就无法正常获取,这里应该是缓存层也出现了问题,可能缓存也被击穿了....
流量冲击是罪魁祸首
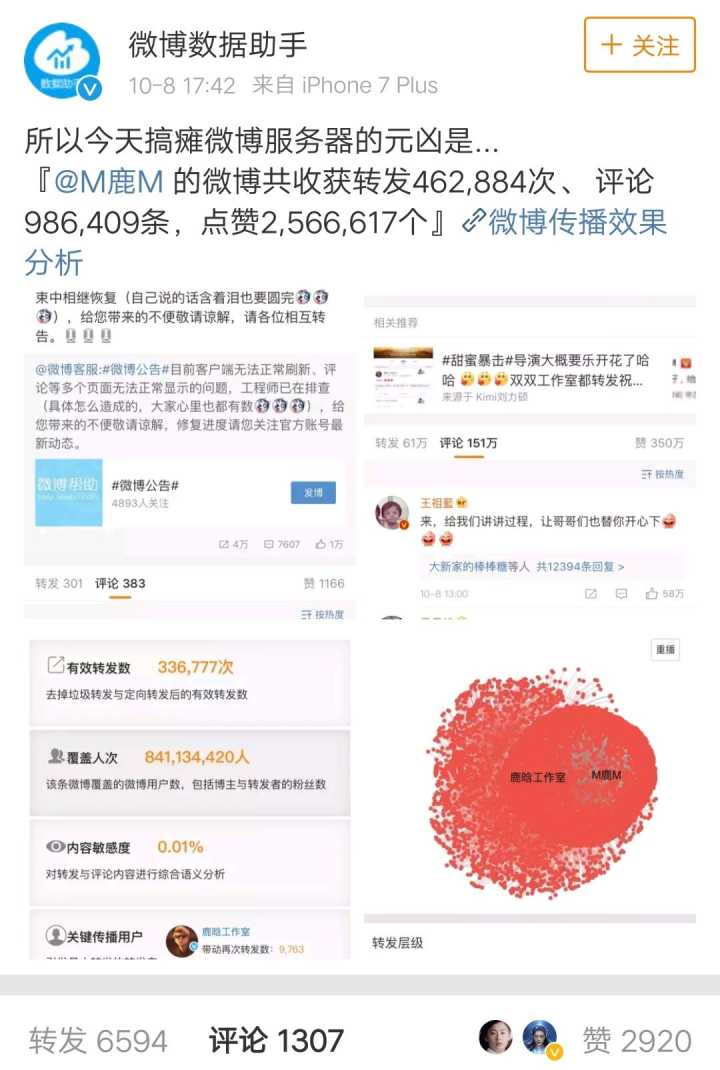
在看了微博公布后的数据后,大致就有了结果,事件发生在放假期间,大家还沉浸在节日的欢快氛围中,服务器明显准备不足,再加上流量确实太大,事件牵涉到了8亿多用户,在这种量级的网络流量冲击下,很难幸免于难吧。
我一开始的思维方向上也有点错误,虽然也考虑到是服务器挂掉了,不过我觉得以微博的技术水平及架构设计上来说应该可以迅速的处理掉,同时也认为读操作不会拖垮服务器集群,更多的应该是写操作导致了一些崩盘,因此更多的考虑的是数据层,觉得可能是数据库或者其他中间件出现问题(肯定也是出现了一些问题,只不过垮掉的主因不是这些,而是服务器资源缺乏导致的),从微博工作人员的处理方案中可以得出结论,主要问题还是在服务器资源上。
在看到下图的数据之前,谁也想不到会有这么高的关注度和这么巨大的流量冲击,在绝对的量级差距面前,即使浑身解数也无法全然施展,只能尽量做到亡羊补牢了。
想起前段时间南朝鲜部署萨德时局座说的一句话,就是在绝对的饱和打击下,萨德这些装备是起不到什么作用的,当然,我们不讨论萨德或者军事,就是通过这么一句评论来总结一下这次微博宕机事件,虽然微博的架构和技术团队很强大,但是在足够大的瞬时流量冲击下,容灾、自动扩容、缓存、负载均衡、吞吐量、架构伸缩性等等一系列的方案或应对措施似乎都被宕机的结果所淡化,冲垮的无影无踪了,流量太大太大了,8亿多用户是一个什么概念大家应该很清楚。
总结
首发于我的个人博客。
虽然通过后续的一些措施最终解决掉这个事故,但是依然暴露出一些问题,不过也没有特别好的应对办法,谁知道他们什么时候心血来潮忽然就公布恋情或者出轨啊。
总结下来此次的主因就是流量小生带来的巨额流量+无预警+资源不足+数据密集度较高进而导致的巨额冲击,耗尽了一台又一台服务器的资源,摧垮了一个又一个的服务,肯定还有其他地方出现故障,但是具体就不得而知了,以上为个人愚见,如有不当,还请见谅。
第一次,当它本可进取时,却故作谦卑;
第二次,当它空虚时,用爱欲来填充;
第三次,在困难和容易之间,它选择了容易;
第四次,它犯了错,却借由别人也会犯错来宽慰自己;
第五次,它自由软弱,却把它认为是生命的坚韧;
第六次,当它鄙夷一张丑恶的嘴脸时,却不知那正是自己面具中的一副;
第七次,它侧身于生活的污泥中虽不甘心,却又畏首畏尾。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!