
[Machine-Learning] 机器学习中的几个度量指标
Several classification metrics for ML/DM methods.
主要解释下机器学习(或数据挖掘)中的几个度量指标。
1. 关于 "TN/TP/FN/FP"
在预测过程中,经常会出现这几个名词,先是解释下字面意思:
- **TN: ** True Negative (真负),被模型预测为负的样本,模型预测对了
- **TP: ** True Positive (真正),被模型预测为正的样本,模型预测对了
- **FN: ** False Negative (假负),被模型预测为负的样本,模型预测错了
- **FP: ** False Positive (假正),被模型预测为正的样本,模型预测错了
可以看出来,两个字母的后面一个字母(N ** or P ),是模型预测的结果,而第一个字母(T** or **N **) 代表的是这个结果的正确与否;下面用一个表格来表示一下:
| Actual Class: X | Actual Class: not X | |
|---|---|---|
| Predicted Class: X | TP | FP |
| Predicted Class: not X | FN | TN |
Table.1: BINARY CONFUSION MATRIX
从上面这个表格中也能比较直观地分辨这4个指标:横轴代表结果实际的情况,而纵轴代表了该例子被模型预测的情况。
2. 常用于二分类问题(监督学习)的度量指标
2.1 准确率 or 正确比例:
Accuracy or Proportion Correct
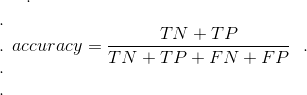
计算方法:(TN + TP) / (TP + TN + FP + FN)
需要注意的是:当分类问题是平衡(blanced)的时候,准确率可以较好地反映模型的优劣程度,但不适用于数据集不平衡的时候。
例如:分类问题的数据集中本来就有97% 示例是属于X,只有另外3%不属于X,所有示例都被分类成X的时候,准确率仍然高达97%,但这没有任何意义。
2.2 PPV or 正预测值:
PPV = Positive Predictive Value 。
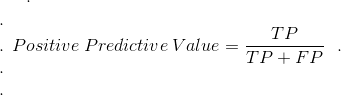
计算方法:TP / ( TP + FP )
模型预测属于X的示例(instance)中,预测正确(真正属于X)的比例。
2.3 召回率 or TP Rate:
Sensitivity(灵敏度) orRecall or True Positive Rate or Probability。
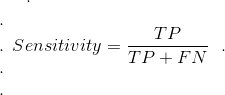
计算方法: TP / (TP + FN)
真正属于X的示例中,成功预测为属于X(TP)的比例。
2.4 NPV or 错误预测正确率:
NPV = Negative Predictive Value
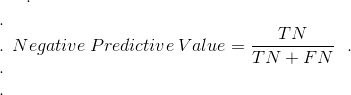
计算方法:TN / (TN + FN)
模型预测不属于X的示例中,预测正确(TN)的比例;
2.5 TN Rate:
Specificity or True Negative Rate
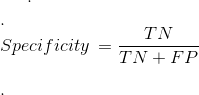
计算方法:TN / (TN + FP)
真正不属于X的示例中,被预测成不属于X的示例所占的比例。
2.6 FP rate or FAR or Fall-out:
FAR = 1-Specificity
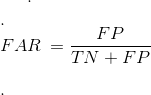
计算方法:FP / (TN + FP)
真正不属于X的示例中,模型预测成属于X的(预测失败)示例所占的比例。
在分类问题中,在灵敏度和FAR两者之间要保持一个平衡(折中)。这种折中要通过ROC曲线来表示,在Y轴上表示灵敏度,在X轴上表示FAR。 较高的FAR导致较高的灵敏度,较低的FAR导致较低的灵敏度。 通常,FAR不能高于某个数,这就是最终分类器的选择。
3. 多分类问题中的度量指标
- Overall Accuracy:被正确分类的示例在数据集中的比例。
- Class detection rate:来自给定类的例子正确地分类占来自给定类的所有样本得比例。
- Class FAR or class FP rate:一个类别中分类错误(未被分到这个类)的示例占所有不是这个类的示例的比例。
在多分类问题中计算PPV和NPV是可行的,但是通常不这么做
reference
- Anna L. Buczak, Erhan Guven, "A Survey of Data Mining and Machine Learning Methods for Cyber Security Intrusion Detection", IEEE COMMUNICATIONS SURVEYS & TUTORIALS VOL. 18, NO. 2, SECOND QUARTER 2016

