
cadence indago简单使用说明
参考博文:http://www.lujun.org.cn/
1,indago系列工具介绍
indago工具,是cadence工具,推出的一系列debug工具。在启动simvision工具时,就会弹出一个窗口,里面就提到了indago工具。

这套工具,非常的强大,但是就是网上介绍的资料不多。因为,有很多人,都不知道这个工具。

主要包括3个工具:
-
debug analyzer app
-
protocol debug app
-
embedded software debug app,简称eswd工具
这三个工具,我只用过debug analyzer app(之后,均简称为indago)和eswd,这两个工具,后面,就对这个两个工具进行详细的介绍。
对于indago,主要用来debug uvm验证环境,会非常有用,当然也可以用来debug RTL。因为该工具,可以查看仿真过程中任意时刻的仿真状态。除了可以往后单步,还能往前单步。因为需要在仿真过程中,将整个仿真过程给记录,因此带来的一个问题,就是造成仿真速度较慢。
而eswed工具,我认为是针对cpu,最强的软件debug工具。该工具,可以将cpu执行的trace流(需要自己开发monitor,从RTL中,将cpu的执行流抓出来),和elf程序,进行一一对应,并且还能和波形进行对应,让我们可以清晰的指导,cpu在每个时刻,在执行什么程序,以及当前的cpu状态。
2,如何产生indago database
首先介绍下indago工具,也就是debug analyzer app。
在debug uvm验证环境时,我们一般是通过增加打印,然后仿真,根据仿真打印的log,来确定问题。如果打印加得不够,还得修改源代码,增加代码代码。
有了indago工具之后,就再也不需要在环境中,增加额外的打印代码。因为indago工具,可以查看仿真时刻的任意状态。
那indago是如何实现的了?其中的关键,就在于,使用irun工具仿真的时候,需要产生indago database,将仿真过程中的信息,给记录下来。最后使用indago工具,载入这个database,实现信息的回看。
下面,就说一下,如何生成这个indago database。
一、编译阶段
在编译阶段,要加入如下三个选项:
-
-ida: 使能indago debug analyzer。 如果使用xrun工具,不需要加该选项。
-
-linedebug:支持代码行调试,必加
-
-uvmlinedebug: 支持uvm库代码行调试,可选
二、仿真阶段
在仿真阶段,需要加入 +UVM_HYPERLINKS=ON 选项,和-input run.tcl 选项,来指定仿真所需要的tcl文件。
在run.tcl中,可以精细化的控制indago database生成。因为产生indago database会降低仿真速度,因此需要使用run.tcl,来精细化控制,database的生成过程。
下面是一个参考的run.tcl脚本。
|
1
2
3
|
ida_probe -log -sv_flow -uvm_reg -log_objects -sv_modules -wave -wave_probe_args="top_tb -depth all –all memories"runexit |
三、ida_probe命令
ida_probe,指定database中记录产生的数据。
这个命令很重要,因为后面indago能回看的数据,完全是由这个命令,来指定的。比如,ida_probe,指定了database要记录波形,那么将来在indago工具中,才可以看到波形。
下图,是ida_probe命令的说明:
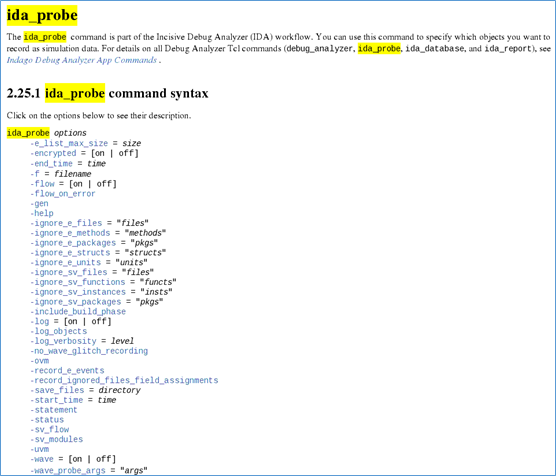
这里,说明一下这个命令的一些常用选项:
1、-start_time/-end_time
指定database记录仿真状态的起始时间和结束时间。主要用来,记录关键一段仿真过程的状态。
2、-log
记录打印的信息
3、-log_objects
记录打印信息中的,动态对象。
4、-uvm
记录uvm package信息。如果使用这个选项,需要编译带上 –linedebug 选项。
开启这个选项,会将uvm的基类,比如uvm_test,uvm_env等这些基类进行记录,这样将来在indago工具中,可以在这些基类中,回看仿真过程。
如果不关心uvm基类的底层过程,可以不用加这个选项。
5、-uvm_reg
记录uvm_reg的信息,需要在编译选项,加入 –uvmlinedebug。当uvm环境中,有uvm寄存器模型,需要将该选项加上。
6、-wava/-wave_probe_args=xxx
-wave开启波形记录。 -wave_probe_args,指定波形记录的形式。xxx参数,是传递给probe的参数。
对于probe命令,其说明如下:
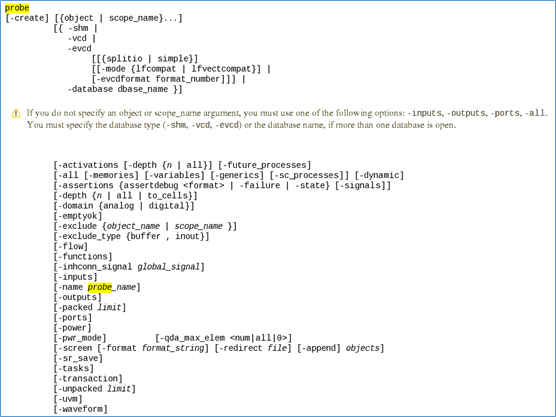
如-wave_probe_args= "dut_top -depth all –all memories",表示记录dut_top模块的内部信号波形,以及该模块之下所有模块的内部波形。因为还有-all选项,因此还会记录memory的波形。
7、-sv_files
允许记录systemverilog文件
8、-sv_flow
允许记录systemverilog信息
9、-sv_modules
允许记录systemverilog的module信息。默认为是不记录systemverilog的module信息的。
10、-sv_packages= "pkg"
记录指定systemverilog package的信息
11、-include_build_phase
记录systemverilog flow中,build phase的信息。默认为uvm,不记录build phase的信息,如果想要记录,需要加入这个选项。
12、-ignore_sv_files= "files"
不记录,指定的sv文件。可以使用匹配表达式
13、-ignore_sv_instances= "insts"
不记录,指定的sv的模块。
-ignore_sv_instances= "top.router",不记录top下router模块的信息。top.router必须是module,而不能是动态对象(比如class对象)。
14、-ignore_sv_packages= "pkgs"
不记录,指定的systemverilog package信息。
15、-ignore_sv_functions= "functs"
不记录,指定systemverilog的function和task。
例如,-ignore_sv_functions= "bar*" ,不记录bar开头的函数和任务
16、例子
|
1
|
ida_probe –log –sv_flow –ignore_sv_packages="cdn_gpio cdn_mem" |
表示,记录log,以及systemverilog,但是不记录cnd_gpio和cdn_mem这2个package。
|
1
|
ida_probe –log –start_time=100ns –end_time=20000ns –wave –wave_probe_args="dut_top –depth all" |
表示,记录从100ns开始,200000ns结束,在这一段时间中,记录log,和波形,波形记录dut_top模块以及这个模块之下的所有信息。
17、ida_probe命令小结
因为使用ida_probe之后,会降低仿真速度,因此需要合理的使用提供的选项,记录关键的信息。而不是全记录。
比如不需要记录RTL波形,那么就不要加-wave选项。
比如,关心一段时间的仿真状态,那么就要使用-start_time/-end_time,这两个选项。来限定记录的时间。
四、indago启动
通过run.tcl脚本,指定产生database的信息。irun工具仿真完毕后,会在当前目录下,生成ida.db文件夹。
直接使用indago命令,启动indago工具,indago会自动载入ida.db文件夹内容。
界面如下所示:
3,indago工具的使用
启动indago工具之后,indago的界面,如下图所示:

下面,就介绍一些,indago的炫酷技能。
一、smartlog
smartlog,显示log,并且可以将打印的一行log,和仿真状态进行关联。
在每行log的开头,有一个向前或者向后的按钮,点击,表示,将仿真状态,定义到这一时刻,此时,代码窗口,显示打印这行log的代码处。
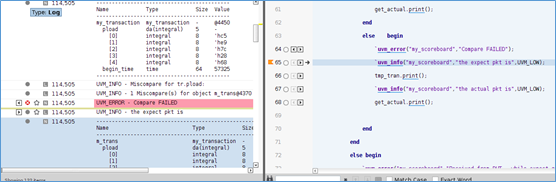
在smartlog的界面,可以配置,打印log的verbosity级别,以及log的类型。便于查看自己想要看的log。
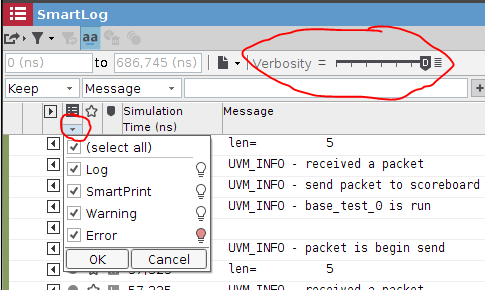
在代码处,右键,选择add smartprint to log。
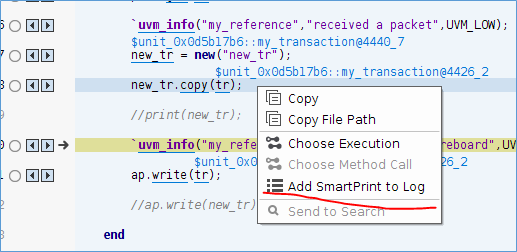
输入想打印的变量,然后选择时间范围,如果不选择,就默认为整个仿真时间,在设置打印的verbosity。
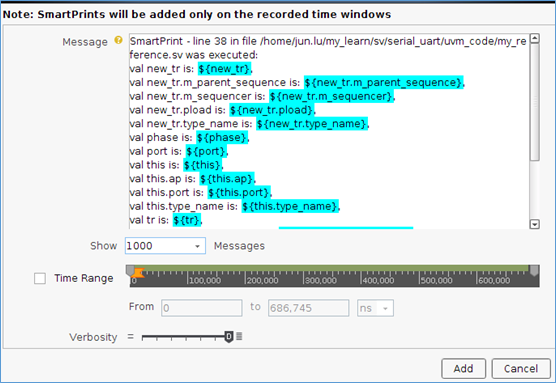
点击add之后,就会发现神奇的一幕出现了。
在smartlog界面,会将代码被调用的时刻,把设置的变量全部打印出来。这就意味着,将来再也不需要在环境中,增加额外的打印代码,来帮助调试了。

二、代码区
在代码区,可以查看代码,包括RTL和tb,都可以。
如果代码行,前面有向前或者向后的按钮,表示,这行代码,在仿真过程中,有执行过,可以点击按钮,将当前的仿真状态,恢复到执行这一行代码的状态。

上图中的红色框的按钮,是控制仿真过程的按钮,可以执行:
-
向前单步
-
向后单步
-
向前跳过
-
向后跳过
indago的一个很炫酷的功能,是可以支持向后跳转,也就是我们可以知道,当前仿真状态的前一个仿真状态是什么。
点击左上角的 Files,可以加载指定的文件。
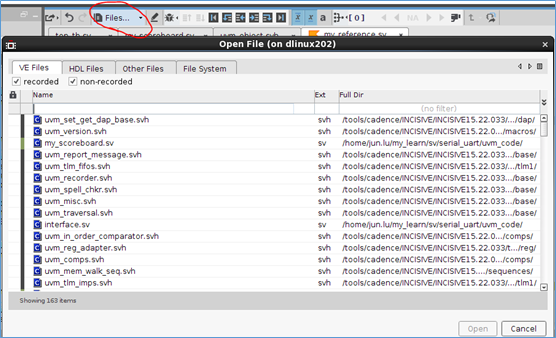
文件前面的黄色标志,表示,当前仿真状态在执行这个文件。代码行前的黄色标志,表示当前仿真状态,要执行这一行代码。

如果打开,variable界面,那么在该界面,会自动显示各个变量的值。
三、top界面
在top界面,可以查看design和test bench的代码。对于rtl代码,可以选择信号,加入到波形中。
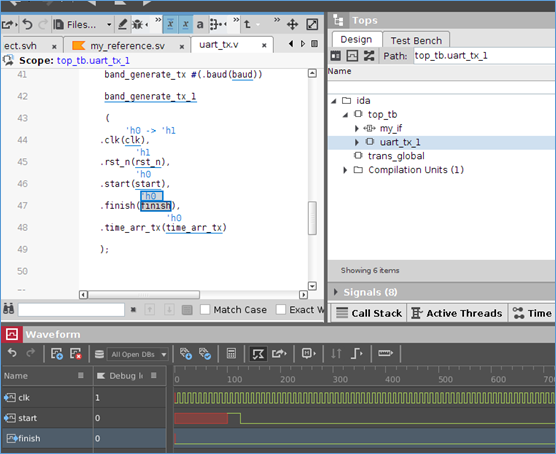
在波形窗口中,对波形信号,双击,会跳转到rtl代码中,并且将仿真状态,切换到该波形时刻。
四、active threads
在active threads窗口,点击刷新按钮,可以查看激活的线程,有哪一些。选择任意一个线程,就可以跳转到代码处。

五、call stack
call stack界面,用来查看调用栈,也就是函数的调用关系层次是怎么样的。
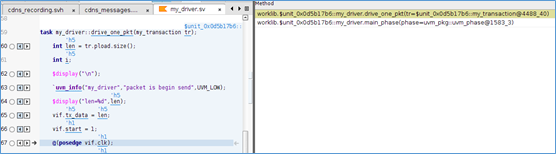
对于my_driver中的driver_one_pkt函数,是由my_driver中的main_phase函数调用的。
六、diagnostics
诊断窗口,会显示,在产生indago database过程中,影响仿真速度的一些文件和代码。

从该界面中,可以知道哪些文件影响了仿真速度,如果该文件,对查看状态不影响,可以在ida_probe命令中,将这个文件ingore掉。从而提高仿真速度。
七、总结
该工具,还有其他的一些功能,这个就需要大家自己去使用的时候,研究了。这里,只是给大家简单介绍indago工具的使用。
总的来说,indago工具,根据仿真得到的database,以图形化界面呈现给我们,让我们能够回看仿真的任意时刻状态,从而方便我们去debug。
4,仿真加速indago database
indago工具很强大,对于debug环境,非常好用。但是因为仿真过程中,会产生indago database,而database,会记录仿真的所有状态,因此必然就会造成仿真速度慢。如果环境非常复杂,那么仿真速度会奇慢无比。
因此,就需要一些手段,来限制indago database的生成,不能记录仿真所有的状态,而是记录关键的状态,以提高仿真速度。
indago database的产生,是依赖于仿真执行的sim.tcl文件中的ida_probe命令,来指定的,因此就需要在这个命令上,做些文章。
一、去掉-log选项
-log选项,会将仿真打印的log,和代码以及仿真状态进行关联。这个feature,在熟悉环境的时候,其实是不需要的,因为我们知道,打印的log,是在什么地方打印的。因此可以考虑去掉。以提高仿真速度。
二、去掉-wave
我们一般使用verdi工具,查看波形,因此将-wave选项去掉,database中不产生波形。
三、-ignore_sv_instances="dut顶层的层次"
RTL的波形,可以在verdi工具中查看,因此也不需要在indago database中,记录rtl的状态,直接将rtl从顶层到底层,都给ignore掉,均不记录。
四、-ignore_sv_files="files"
对于一些不关心的文件,通过-ingore_sv_files选项,将这些文件,也ignore掉,不记录。
五、-uvm –uvm_reg
如果不调试底层的UVM代码,那么去掉-uvm选项。如果环境中,没有register model,去掉-uvm_reg选项。
六、总结
因为indago工具,仿真过程会产生database,降低了仿真速度。为了不让仿真速度太慢,需要我们自己控制,产生database的记录条件。
5,最强cpu debug工具-eswd
我们在编写c程序,在调试的时候,希望能够使用visual studio工具,或者eclipse工具,实现单步调试,让我们能够查看c程序的执行状态,从而帮助我们去调试我们写的c程序。
那在soc验证或cpu core验证(以下简称core验证)的时候。我们也是写了c程序(或者汇编程序,以下不区别),在验证环境中运行,怎么能够知道程序在core上的执行结果呢?我们也希望能有像eclipse这样的工具,能够通过IDE工具,能够知道程序的执行过程以及执行结果。
这个时候,indago中的embedded software debug app(以下简称eswd)工具横空出世,解决了上述问题。
一、eswd工具
首先上图,以下是eswd的界面。cpu的名字,叫xxx。支持aarch64和aarch32两种arm架构指令集。包含8个core。

左上角是源代码区,中间是反汇编区,右上角是状态区(用来查看core状态,以及切换core),最下面界面是波形区,显示各个core指令流的波形(只记录了pc)。
通过这个工具,就能够知道,我们编写的程序,在cpu上的执行过程,以及执行结果。还能够,单步仿真,单步跳过。而单步功能,不仅仅支持向前跳转,还可以向后跳转。
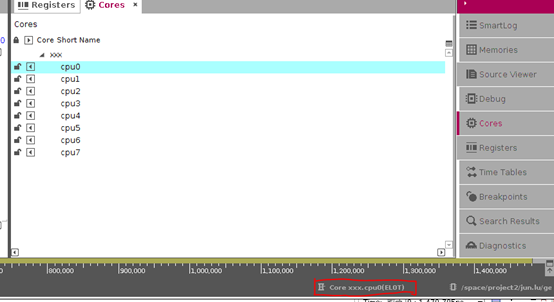
eswd工具,支持多个core,可以分别查看每个core的执行过程,在状态窗口的状态栏,会显示,当前查看的是哪一个core,以及该core的EL。
在源代码窗口,可以加载源文件。

对于加载的源代码,如果代码有执行过,那么在代码行的前面会有向前向后的按钮,点击该按钮,可以将当前的状态,恢复到执行该行代码的状态。
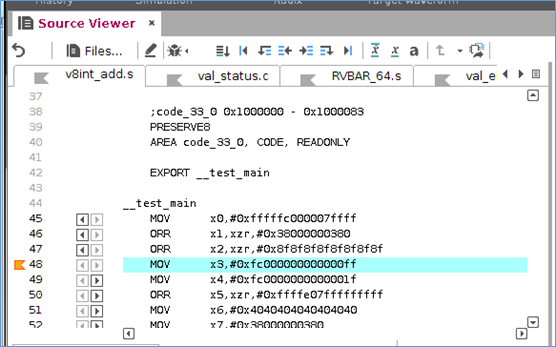
在debug界面,可以查看变量的值,以及调用栈。
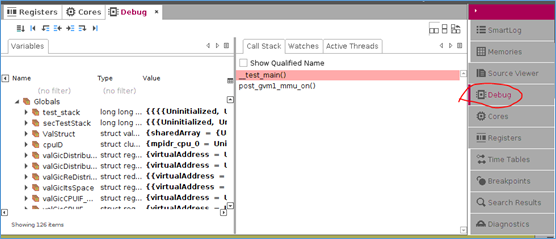
在代码处,右键,选择 choose execution。
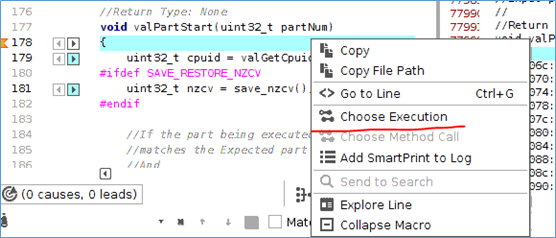
会弹出time tables窗口,显示,这个函数,在那些时刻有执行过。
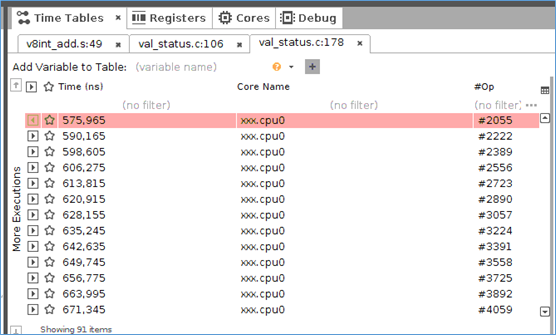
在波形窗口,能够看到各个core的执行pc,以及该pc,所在的函数。
二、总结
该工具,可以让我们知道,程序在cpu上的执行过程,以及执行结果,方便我们去定位问题。而不需要去分析波形,才能得到cpu的执行过程与执行结果。
要想使用eswd工具,显示出这些信息,需要我们去做一些工作,产生database,给eswd工具来分析。
产生database,需要如下的一些文件:
-
程序的elf文件
-
cpu架构的描述
-
trace的配置文件
-
cpu的执行结果trace
后面,就要详细来说明一下,如何得到上面的文件,最终产生database,并使用eswd工具进行分析。
6,eswd工具配置与仿真
上一文介绍了eswd工具的使用,该工具,可以将cpu的执行流,与elf程序对应起来,让我们方便的去debug。
下面,就说一下,怎么实现上述过程。
需要三个文件
-
cpu架构描述文件
-
cpu执行的指令流文件,下文简称tarmac文件
-
eswd配置文件
一、cpu架构的描述
eswd工具,需要cpu架构的描述文件。我们使用自定义架构的方式,传递给eswd工具。
这款自定义架构的处理为xxx(基于ARMv8)。定义xxx_eswd.conf文件。
首先是xxx(架构的名字),随后跟着一个大括号,描述这款架构的信息。
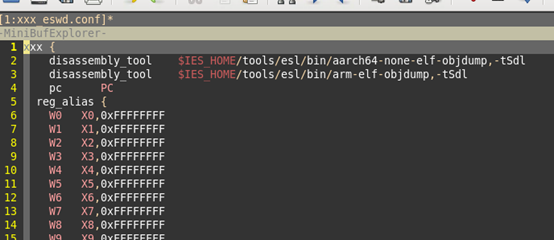
-
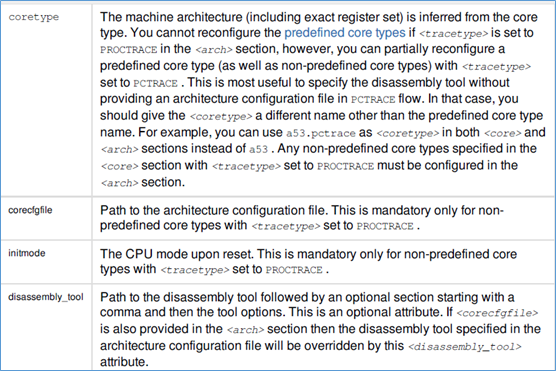
disassembly_tool:定义反汇编工具,因为ARMv8支持aarch64和aarch32两种架构,因此这里有2个反汇编工具。
-
pc:定义pc寄存器的名字,后面程序的对应,就根据该名字进行对应
-
reg_alias: 寄存器的别名,ARMv8有X和W寄存器的区别,W寄存器,其实就是X寄存器的低32bit。

ARMv8架构,包括了aarch32的R寄存器,因此在reg_alias中,也需要进行定义。
1、reg_banks
reg_banks,定义寄存器。需要查看的寄存器,需要在这里定义。格式如下图:

这里定义了系统寄存器,向量寄存器,通用寄存器。图中的。。。,是省略的寄存器描述,需要自己填写完整。

对于寄存器描述,需要如下的描述信息
寄存器的名字 "寄存器位宽,寄存器描述"
-
寄存器的名字:该寄存器将来显示在eswd工具上的寄存器的名字,eswd工具,会从cpu仿真log中,查找该寄存器名字,并将值进行关联。
-
寄存器位宽:指定寄存器的位宽
-
寄存器描述:该寄存器的功能
如 CPSR "32,program status register"
表示,有一个系统寄存器CPSR,32bit寄存器,是program status register。
将自己关心的寄存器,给描述出来。不关心的寄存器,可以不用描述。寄存器描述多了,会减慢eswd分析的过程。
有描述的寄存器,在eswd工具的registers子界面,就可以看到寄存器的值。

2、modes
modes,定义cpu允许的模式。其格式如下:
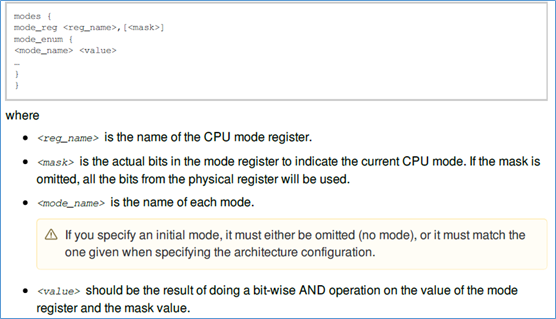
对于ARMv8,使用CPSR,来判断当前cpu的模式。

mode_reg,指定cpu mode,关联的寄存器,后面的0x1f,表示取该寄存器的低5个bit。
mode_enum:对cpu的mode的枚举描述,第一列是cpu的模式,第二列是对应寄存器的值,也就是 CPSR & 0x1f的值。
对于cpu架构,描述这些信息,就已足够了。更多的内容,要查看eswd工具的userguide。
3、dwarf_regs
dwarf_regs段,用来描述cpu的不同mode下,dwarf寄存器与物理寄存器的映射关系。
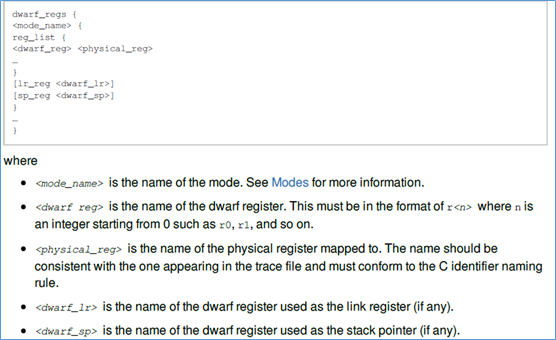
在xxx架构中,描述如下:
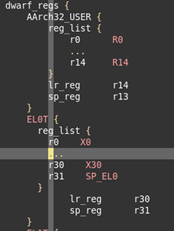
上图是dwarf_regs段描述的一部分,对于modes段,指定的每个cpu模式,都需要进行定义。
4、event
event的定义如下,可以用来追踪一些event。

如果tarmac文件中,有相应的event关键字,那么会在波形文件中,有显示。
如以下,定义了三个event。mode_change是自带的event。
|
events mode_change,RESET_EVENT,CALL_EXCEPTION |
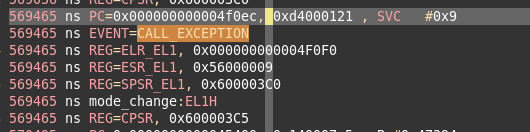
indago工具中,显示如下。

在569465ns,出现过CALL_EXCEPTION这个event。和tarmac文件中一致。

二、cpu执行的指令流
要将cpu的仿真指令流,最终转化成tarmac文件。将来提供给eswd工具使用。
tarmac文件的格式如下图:

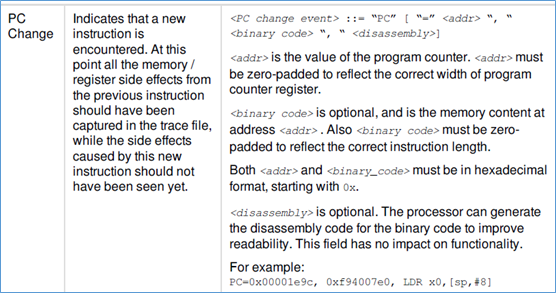
1、pc change
对于pc change,格式如下图:
2、寄存器访问
对于寄存器,格式如下图:
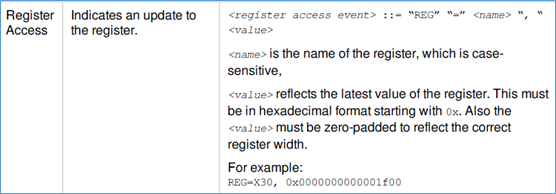
有了寄存器的信息,indago界面,才可以显示出寄存器的值。
3、memory访问
对于memory访问,格式要复杂一些:

有了memory的信息,我们就可以在indago界面中,看到c代码的各个变量的值。
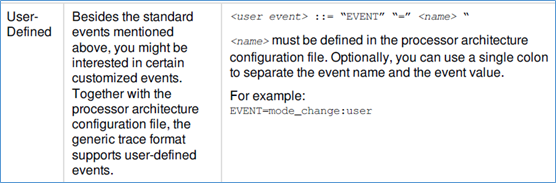
4、event
对event,格式如下图:
5、自己实现
只有tarmac的格式,符合上面定义的格式,eswd工具,才能够将tarmac的结果,与elf程序给对应起来。
打印的tarmac的格式如下图所示:
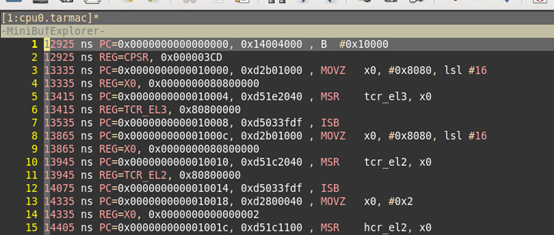
第一列,表示仿真时间,第二列是时间单位。
如果是指令的信息,PC表示指令的PC,后续跟指令码。最后跟反汇编。反汇编信息这一列,可以不要。
如果是指令的执行结果,REG表示寄存器,后续跟寄存器的值。这里的寄存器,要和cpu架构描述文件中的寄存器描述的名字要一致。
如果是EVENT,EVENT表示事件,后面跟时间的名字,名字要和cpu架构描述文件中,event指定的事件一致。
对于CPSR,在17905ns,值是0x600003cd,和0x1f与,结果是0x0000000d。从cpu架构描述文件中,可以知道,当前cpu处于EL3H模式。
时间,最好和波形中的时间一致,这样当发现问题后,可以很快的定位到波形的位置。
cpu仿真打印的log,可能和eswd要求的log格式不一致,因此需要脚本进行处理,将cpu仿真打印的log,和eswd要求的log格式一致。
三、eswd配置文件
在提供了cpu架构描述文件,cpu执行指令流log(以下简称tarmac文件)后,还需要配置文件。
配置文件,以config关键字开始,配置的描述,都在config包围的大括号中。
tarmacfile_optional 1:如果该core的tarmac文件不存在,那么忽略该core的分析。xxx是一个8core的cpu,在某些情况下,可能只有某几个cpu在跑。
1、archs段
描述架构信息,格式如下图:
我实现的如下图:
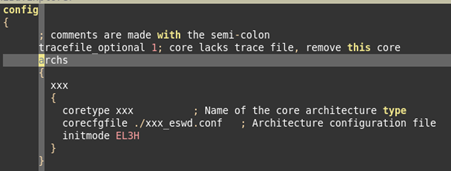
archs段,描述cpu的架构信息。corecfgfile,指定cpu架构描述文件,initmode指定cpu在初始时刻,的cpu模式。archs段中,可以描述多个cpu的架构信息。
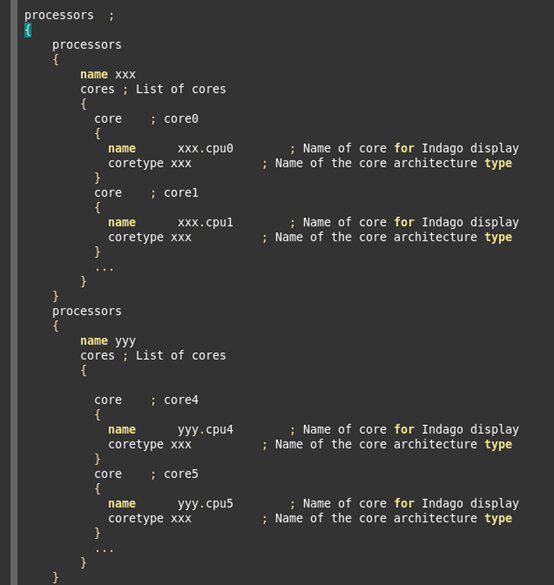
2、processors段
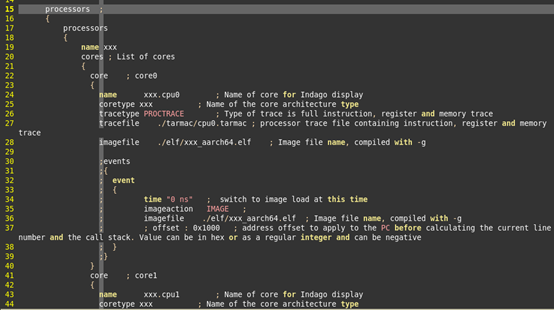
processors段,指定处理器的配置信息。processor中,可以嵌套多个processors。
对于嵌套的每一个processors,name表示该processors的名字,cores,表示该processors中包含的core。
对于每个core:
-
name表示该core的名字
-
coretype,指定archs段中的cpu架构
-
tarmactype:PROCTARMAC,表示使用tarmac文件的方式进行追踪,还有一种是使用shm波形文件方式。
-
tarmacfile:cpu执行的指令流log文件
-
imagefile:core上执行的elf文件
-
events:指定event,eswd工具,支持在不同的时刻,载入不同的elf程序。如果有这样的需求,就在events中指定。
上面的描述,在eswd的cores界面如下:
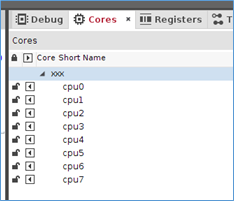
如果processors描述如下:
那么eswd工具上,cores的子界面如下图所示:
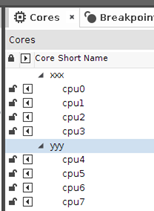
通过该配置文件,就告诉了eswd工具,追踪的cpu架构,cpu架构文件,tarmac文件,elf文件。
四、仿真
完成上述工作后,就是用使用irun工具,搭配-esw选项,产生eswd database,之后使用eswd工具分析。
|
irun -log logfile -64bit -esw arch_config:./xxx_eswd.conf -esw config:./config_proctarmac_aarch64.in |
-
-esw arch_config: 指定cpu架构描述文件
-
-esw config: 指定eswd配置文件
仿真完毕后,会生成ida.db,esw.db,eswtarmac.shm这3个文件夹。这些就是eswd database。

指定indago -64bit命令,就会启动indago工具。
3、总结
要使用cadence公司提供的eswd工具,需要进行一些配置。配置比较花时间与精力,但是花费的时间与精力是值得的。因为通过这个工具,我们能够看到软件,在cpu上的执行流程以及执行结果,从而方便我们去debug。
eswd还有其他的一些更高级的功能,这部分,我就不介绍了,大家可以看到eswd的userguide。
到这里,cadence indago征程,就结束了,主要是介绍了indago系列的2个工具,debug app与eswd。至于另外一个协议分析,我没有用过,因此就不再介绍。
