

监控——《微服务设计》读书笔记
系列文章目录:
在单块应用的世界里,当我们遇到问题时,我们至少清楚从哪里开始调查。网站访问速度?网站访问异常?CPU占用过高?这些都是单块应用程序的问题,单一的故障点会极大地简化对问题的排查。
而现在我们面对了多个微服务,我们需要多个服务器、多个服务来完成我们的功能。那么如果现在生产服务延迟了,我们该从何查起呢?其实很简单:监控单台小的服务,然后聚合起来看整体。
监控模型
1.单一服务&单台服务器
这种情况最简单。
如果我们想监控主机本身如CPU、内存等这些物理指标,当它超出边界时就会发生警告,我们可以使用Nagios、New Relic等这样的服务来帮助我们。
如果我们想监控服务器记录的日志,我们可以在单台服务器使用命令行扫描日志,或者使用logrotate来管理日志就好了。
如果我们想监控服务器上的单个服务时,我们可以查看Web服务器或者应用程序的服务器就可以做到这一点。
2.单一服务&多台服务器
这种情况稍微复杂了一点,如前所述,如果我们想监控CPU,当CPU占用率过高时,如果这个问题发生在所有的服务器上,有可能是微服务本身的问题,但如果只发生在一台,则有可能是主机本身的问题。
我们需要关注每台服务器的日志数据,我们既想把数据聚合起来,又想深入分析每台主机,Nagios允许以这样的方式组织我们的主机。
对于像时间这样的监控,我们可以负载均衡器中进行追踪,很容易就能拿到聚合后的数据,不过负载均衡器本身也需要监控,如果它的行为异常,也会导致问题。
3.多个服务&多台服务器
这个情况就更复杂了,我们如何在多个主机上,成千上万行的日志中定位错误的原因?如果确定是一个服务器异常,还是一个系统性的问题?如何在多个主机跟踪一个错误的调用链,找出引起错误的原因?
答案是:从日志到应用程序指标,集中收集和聚合更可能多的数据。
收集多服务器的日志
我们需要将日志能够集中到一起方便使用,logstash可以解析多种日志格式,将将它们发送给下游系统,比如发给Kibana,它是一个基于ElasticSearch查看日志的系统,你可以使用查询语法、指定时间和日志范围、正则表达式来搜索日志。它还可以把你的日志生成图表。
收集多服务器的主机指标
我们有时还想了解各台服务器的硬件指标信息,如CPU平均负载,单台CPU的使用情况。我们可以使用Graphite来帮助我们,它允许你实时发送指标数据给它,它可以生成图表或表格来呈现指标结果。Graphite允许你做跨样本做聚合,或深入到某个部分,这样就可以查看整个系统、一组服务或一个单独实例的响应时间。
收集多服务器上应用程序的指标
收集应用程序的指标不仅可以帮助我们改变程序,还可以帮助我们改变产品,我们可以知道哪些页面被访问,哪些是真正重要的功能。
语义监控
我们可以在生产环境运行一些测试用例,当这些案例如果没有达到我们预期的值时,我们会认为生产环境的某个环境出问题了,甚至,我们可以在生产环境设置一组假用户和一些已经的数据集。
关联标识
请求的调用可以涉及到多个微服务,更为复杂的可能是一个请求链,并且以异步的方式触发。我们如何才能重建请求流,以重现和解决这个问题呢?
使用关联标识来解决,在触发第一个调用时,生成一个唯一标识,然后把它传递给所有的后续调用。当然,使用这种方式,需要在团队内部达成一致,或者形成一种标准,而现实是,我们可能是在碰到这样的问题时才会想到这个办法,或者即使有这个办法,很难保证大家都会以正确的试调用。如果我们决定使用这样一种特性,我们需要确定它不要太复杂且不依赖提供的任何特定服务,我们可以选择在HTTP头传递关联标识即可。
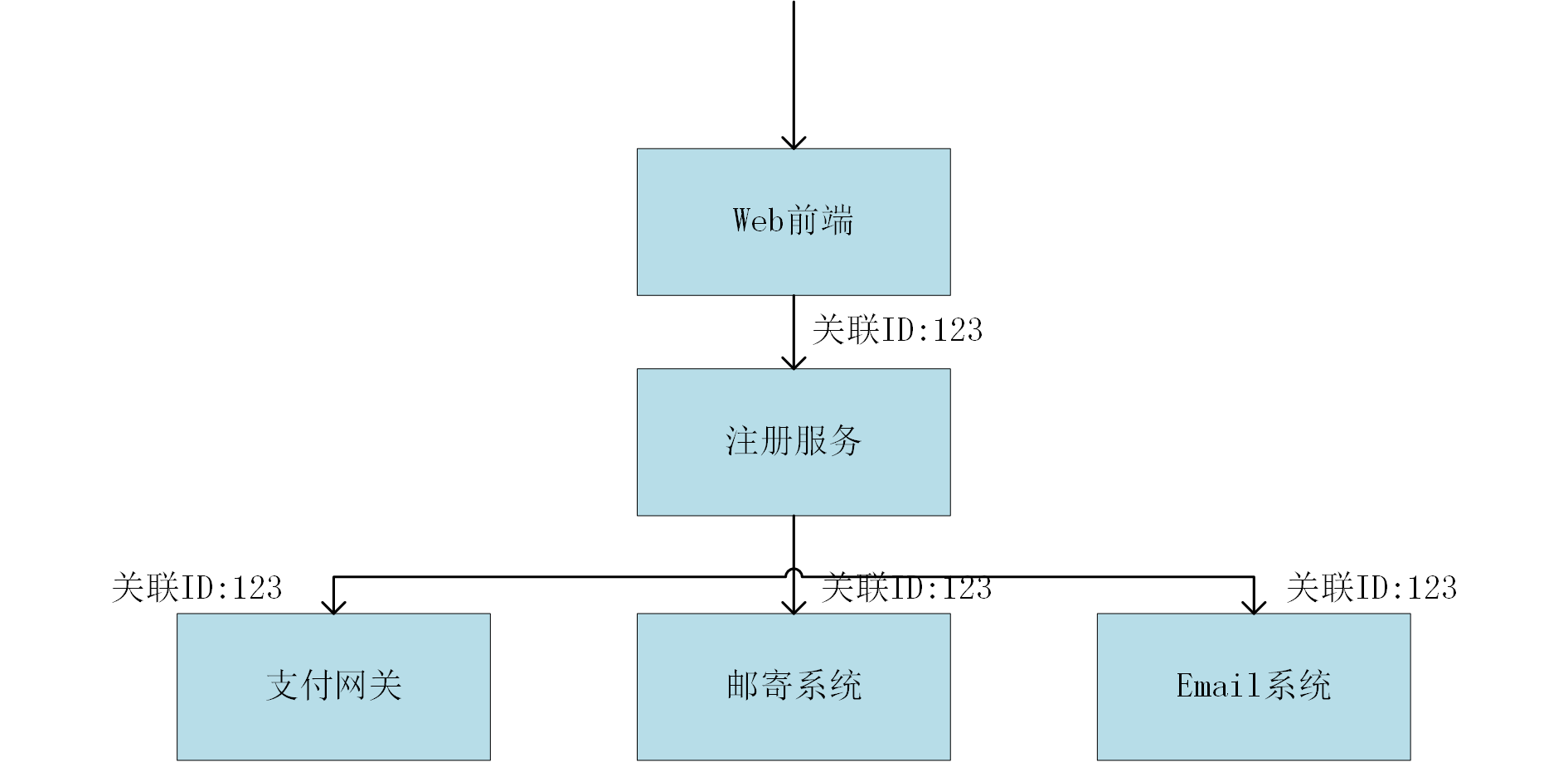
Zipkin和Dapper这样的跟踪系统值得我们去尝试。
级联
如果两个服务单独来看都是正常的,相互调用则不行,这又应该如何处理?因此,监控系统之间的集成点非常关键,每个服务的实例都应该追踪和显示其下游服务的健康状态,从数据库到其他合作服务。
标准化
监控这个领域的标准化是到头重要的。
参考
《微服务设计》(Sam Newman 著 / 崔力强 张骏 译)

