
[LeetCode] 83. Remove Duplicates from Sorted List 删除排序链表中的重复元素
Given the head of a sorted linked list, delete all duplicates such that each element appears only once. Return the linked list sorted as well.
Example 1:
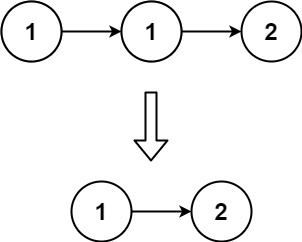
Input: head = [1,1,2] Output: [1,2]
Example 2:
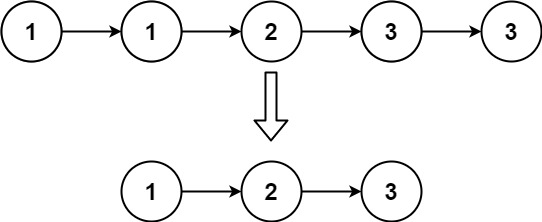
Input: head = [1,1,2,3,3] Output: [1,2,3]
Constraints:
- The number of nodes in the list is in the range
[0, 300]. -100 <= Node.val <= 100- The list is guaranteed to be sorted in ascending order.
这道题让我们移除给定有序链表的重复项,那么可以遍历这个链表,每个结点和其后面的结点比较,如果结点值相同了,只要将前面结点的 next 指针跳过紧挨着的相同值的结点,指向后面一个结点。这样遍历下来,所有重复的结点都会被跳过,留下的链表就是没有重复项的了,代码如下:
解法一:

class Solution { public: ListNode* deleteDuplicates(ListNode* head) { ListNode *cur = head; while (cur && cur->next) { if (cur->val == cur->next->val) { cur->next = cur->next->next; } else { cur = cur->next; } } return head; } };
我们也可以使用递归的方法来做,首先判断是否至少有两个结点,若不是的话,直接返回 head。否则对 head->next 调用递归函数,并赋值给 head->next。这里可能比较晕,先看后面一句,返回的时候,head 结点先跟其身后的结点进行比较,如果值相同,那么返回后面的一个结点,当前的 head 结点就被跳过了,而如果不同的话,还是返回 head 结点。可以发现了,进行实质上的删除操作是在最后一句进行了,再来看第二句,对 head 后面的结点调用递归函数,那么就应该 suppose 返回来的链表就已经没有重复项了,此时接到 head 结点后面,在第三句的时候再来检查一下 head 是否又 duplicate 了,实际上递归一直走到了末尾结点,再不断的回溯回来,进行删除重复结点,参见代码如下:
解法二:
class Solution { public: ListNode* deleteDuplicates(ListNode* head) { if (!head || !head->next) return head; head->next = deleteDuplicates(head->next); return (head->val == head->next->val) ? head->next : head; } };
Github 同步地址:
https://github.com/grandyang/leetcode/issues/83
类似题目:
Remove Duplicates from Sorted List II
Remove Duplicates From an Unsorted Linked List
参考资料:
https://leetcode.com/problems/remove-duplicates-from-sorted-list/












【推荐】还在用 ECharts 开发大屏?试试这款永久免费的开源 BI 工具!
【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET制作智能桌面机器人:结合BotSharp智能体框架开发语音交互
· 软件产品开发中常见的10个问题及处理方法
· .NET 原生驾驭 AI 新基建实战系列:向量数据库的应用与畅想
· 从问题排查到源码分析:ActiveMQ消费端频繁日志刷屏的秘密
· 一次Java后端服务间歇性响应慢的问题排查记录
· 互联网不景气了那就玩玩嵌入式吧,用纯.NET开发并制作一个智能桌面机器人(四):结合BotSharp
· Vite CVE-2025-30208 安全漏洞
· 《HelloGitHub》第 108 期
· MQ 如何保证数据一致性?
· 一个基于 .NET 开源免费的异地组网和内网穿透工具