
常用模块学习
-
模块介绍
模块,用一砣代码实现了某个功能的代码集合。
类似于函数式编程和面向过程编程,函数式编程则完成一个功能,其他代码用来调用即可,提供了代码的重用性和代码间的耦合。而对于一个复杂的功能来,可能需要多个函数 才能完成(函数又可以在不同的.py文件中),n个 .py 文件组成的代码集合就称为模块。
如:os 是系统相关的模块;file是文件操作相关的模块
模块分为三种:
- 自定义模块
- 内置标准模块(又称标准库)
- 开源模块
自定义模块 和开源模块的使用参考 http://www.cnblogs.com/wupeiqi/articles/4963027.html
-
time &datetime模块

#_*_coding:utf-8_*_
__author__ = 'Alex Li'
import time
# print(time.clock()) #返回处理器时间,3.3开始已废弃 , 改成了time.process_time()测量处理器运算时间,不包括sleep时间,不稳定,mac上测不出来
# print(time.altzone) #返回与utc时间的时间差,以秒计算\
# print(time.asctime()) #返回时间格式"Fri Aug 19 11:14:16 2016",
# print(time.localtime()) #返回本地时间 的struct time对象格式
# print(time.gmtime(time.time()-800000)) #返回utc时间的struc时间对象格式
# print(time.asctime(time.localtime())) #返回时间格式"Fri Aug 19 11:14:16 2016",
#print(time.ctime()) #返回Fri Aug 19 12:38:29 2016 格式, 同上
# 日期字符串 转成 时间戳
# string_2_struct = time.strptime("2016/05/22","%Y/%m/%d") #将 日期字符串 转成 struct时间对象格式
# print(string_2_struct)
# #
# struct_2_stamp = time.mktime(string_2_struct) #将struct时间对象转成时间戳
# print(struct_2_stamp)
#将时间戳转为字符串格式
# print(time.gmtime(time.time()-86640)) #将utc时间戳转换成struct_time格式
# print(time.strftime("%Y-%m-%d %H:%M:%S",time.gmtime()) ) #将utc struct_time格式转成指定的字符串格式
#时间加减
import datetime
# print(datetime.datetime.now()) #返回 2016-08-19 12:47:03.941925
#print(datetime.date.fromtimestamp(time.time()) ) # 时间戳直接转成日期格式 2016-08-19
# print(datetime.datetime.now() )
# print(datetime.datetime.now() + datetime.timedelta(3)) #当前时间+3天
# print(datetime.datetime.now() + datetime.timedelta(-3)) #当前时间-3天
# print(datetime.datetime.now() + datetime.timedelta(hours=3)) #当前时间+3小时
# print(datetime.datetime.now() + datetime.timedelta(minutes=30)) #当前时间+30分
#
# c_time = datetime.datetime.now()
# print(c_time.replace(minute=3,hour=2)) #时间替换
__author__ = 'Alex Li' import time # print(time.clock()) #返回处理器时间,3.3开始已废弃 , 改成了time.process_time()测量处理器运算时间,不包括sleep时间,不稳定,mac上测不出来 # print(time.altzone) #返回与utc时间的时间差,以秒计算\ # print(time.asctime()) #返回时间格式"Fri Aug 19 11:14:16 2016", # print(time.localtime()) #返回本地时间 的struct time对象格式 # print(time.gmtime(time.time()-800000)) #返回utc时间的struc时间对象格式 # print(time.asctime(time.localtime())) #返回时间格式"Fri Aug 19 11:14:16 2016", #print(time.ctime()) #返回Fri Aug 19 12:38:29 2016 格式, 同上 # 日期字符串 转成 时间戳 # string_2_struct = time.strptime("2016/05/22","%Y/%m/%d") #将 日期字符串 转成 struct时间对象格式 # print(string_2_struct) # # # struct_2_stamp = time.mktime(string_2_struct) #将struct时间对象转成时间戳 # print(struct_2_stamp) #将时间戳转为字符串格式 # print(time.gmtime(time.time()-86640)) #将utc时间戳转换成struct_time格式 # print(time.strftime("%Y-%m-%d %H:%M:%S",time.gmtime()) ) #将utc struct_time格式转成指定的字符串格式 #时间加减 import datetime # print(datetime.datetime.now()) #返回 2016-08-19 12:47:03.941925 #print(datetime.date.fromtimestamp(time.time()) ) # 时间戳直接转成日期格式 2016-08-19 # print(datetime.datetime.now() ) # print(datetime.datetime.now() + datetime.timedelta(3)) #当前时间+3天 # print(datetime.datetime.now() + datetime.timedelta(-3)) #当前时间-3天 # print(datetime.datetime.now() + datetime.timedelta(hours=3)) #当前时间+3小时 # print(datetime.datetime.now() + datetime.timedelta(minutes=30)) #当前时间+30分 # # c_time = datetime.datetime.now() # print(c_time.replace(minute=3,hou

#_*_coding:utf-8_*_ __author__ = 'Alex Li' import time # print(time.clock()) #返回处理器时间,3.3开始已废弃 , 改成了time.process_time()测量处理器运算时间,不包括sleep时间,不稳定,mac上测不出来 # print(time.altzone) #返回与utc时间的时间差,以秒计算\ # print(time.asctime()) #返回时间格式"Fri Aug 19 11:14:16 2016", # print(time.localtime()) #返回本地时间 的struct time对象格式 # print(time.gmtime(time.time()-800000)) #返回utc时间的struc时间对象格式 # print(time.asctime(time.localtime())) #返回时间格式"Fri Aug 19 11:14:16 2016", #print(time.ctime()) #返回Fri Aug 19 12:38:29 2016 格式, 同上 # 日期字符串 转成 时间戳 # string_2_struct = time.strptime("2016/05/22","%Y/%m/%d") #将 日期字符串 转成 struct时间对象格式 # print(string_2_struct) # # # struct_2_stamp = time.mktime(string_2_struct) #将struct时间对象转成时间戳 # print(struct_2_stamp) #将时间戳转为字符串格式 # print(time.gmtime(time.time()-86640)) #将utc时间戳转换成struct_time格式 # print(time.strftime("%Y-%m-%d %H:%M:%S",time.gmtime()) ) #将utc struct_time格式转成指定的字符串格式 #时间加减 import datetime # print(datetime.datetime.now()) #返回 2016-08-19 12:47:03.941925 #print(datetime.date.fromtimestamp(time.time()) ) # 时间戳直接转成日期格式 2016-08-19 # print(datetime.datetime.now() ) # print(datetime.datetime.now() + datetime.timedelta(3)) #当前时间+3天 # print(datetime.datetime.now() + datetime.timedelta(-3)) #当前时间-3天 # print(datetime.datetime.now() + datetime.timedelta(hours=3)) #当前时间+3小时 # print(datetime.datetime.now() + datetime.timedelta(minutes=30)) #当前时间+30分 # # c_time = datetime.datetime.now() # print(c_time.replace(minute=3,hour=2)) #时间替换
#_*_coding:utf-8_*_ __author__ = 'Alex Li' import time # print(time.clock()) #返回处理器时间,3.3开始已废弃 , 改成了time.process_time()测量处理器运算时间,不包括sleep时间,不稳定,mac上测不出来 # print(time.altzone) #返回与utc时间的时间差,以秒计算\ # print(time.asctime()) #返回时间格式"Fri Aug 19 11:14:16 2016", # print(time.localtime()) #返回本地时间 的struct time对象格式 # print(time.gmtime(time.time()-800000)) #返回utc时间的struc时间对象格式 # print(time.asctime(time.localtime())) #返回时间格式"Fri Aug 19 11:14:16 2016", #print(time.ctime()) #返回Fri Aug 19 12:38:29 2016 格式, 同上 # 日期字符串 转成 时间戳 # string_2_struct = time.strptime("2016/05/22","%Y/%m/%d") #将 日期字符串 转成 struct时间对象格式 # print(string_2_struct) # # # struct_2_stamp = time.mktime(string_2_struct) #将struct时间对象转成时间戳 # print(struct_2_stamp) #将时间戳转为字符串格式 # print(time.gmtime(time.time()-86640)) #将utc时间戳转换成struct_time格式 # print(time.strftime("%Y-%m-%d %H:%M:%S",time.gmtime()) ) #将utc struct_time格式转成指定的字符串格式 #时间加减 import datetime # print(datetime.datetime.now()) #返回 2016-08-19 12:47:03.941925 #print(datetime.date.fromtimestamp(time.time()) ) # 时间戳直接转成日期格式 2016-08-19 # print(datetime.datetime.now() ) # print(datetime.datetime.now() + datetime.timedelta(3)) #当前时间+3天 # print(datetime.datetime.now() + datetime.timedelta(-3)) #当前时间-3天 # print(datetime.datetime.now() + datetime.timedelta(hours=3)) #当前时间+3小时 # print(datetime.datetime.now() + datetime.timedelta(minutes=30)) #当前时间+30分 # # c_time = datetime.datetime.now() # print(c_time.replace(minute=3,hour=2)) #时间替
-
random
随机数
mport random print random.random() print random.randint(1,2) print random.randrange(1,10)
生成随机验证码
import random
checkcode = ''
for i in range(4):
current = random.randrange(0,4)
if current != i:
temp = chr(random.randint(65,90))
else:
temp = random.randint(0,9)
checkcode += str(temp)
print checkcode
-
os
提供对操作系统进行调用的接口
os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径
os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd
os.curdir 返回当前目录: ('.')
os.pardir 获取当前目录的父目录字符串名:('..')
os.makedirs('dirname1/dirname2') 可生成多层递归目录
os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推
os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirname
os.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname
os.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
os.remove() 删除一个文件
os.rename("oldname","newname") 重命名文件/目录
os.stat('path/filename') 获取文件/目录信息
os.sep 输出操作系统特定的路径分隔符,win下为"\\",Linux下为"/"
os.linesep 输出当前平台使用的行终止符,win下为"\t\n",Linux下为"\n"
os.pathsep 输出用于分割文件路径的字符串
os.name 输出字符串指示当前使用平台。win->'nt'; Linux->'posix'
os.system("bash command") 运行shell命令,直接显示
os.environ 获取系统环境变量
os.path.abspath(path) 返回path规范化的绝对路径
os.path.split(path) 将path分割成目录和文件名二元组返回
os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素
os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素
os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False
os.path.isabs(path) 如果path是绝对路径,返回True
os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False
os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False
os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
os.path.getatime(path) 返回path所指向的文件或者目录的最后存取时间
os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
-
sys
用于提供对解释器相关的操作
sys.argv 命令行参数List,第一个元素是程序本身路径
sys.exit(n) 退出程序,正常退出时exit(0)
sys.version 获取Python解释程序的版本信息
sys.maxint 最大的Int值
sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
sys.platform 返回操作系统平台名称
sys.stdout.write('please:')
val = sys.stdin.readline()[:-1]
-
shutil
高级的 文件、文件夹、压缩包 处理模块
shutil.copyfileobj(fsrc, fdst[, length])
将文件内容拷贝到另一个文件中,可以部分内容
shutil.copyfile(src, dst)
拷贝文件
shutil.copymode(src, dst)
仅拷贝权限。内容、组、用户均不变
shutil.copystat(src, dst)
拷贝状态的信息,包括:mode bits, atime, mtime, flags
shutil.copy(src, dst)
拷贝文件和权限
shutil.copy2(src, dst)
拷贝文件和状态信息
shutil.ignore_patterns(*patterns)
shutil.copytree(src, dst, symlinks=False, ignore=None)
递归的去拷贝文件
例如:copytree(source, destination, ignore=ignore_patterns('*.pyc', 'tmp*'))
shutil.rmtree(path[, ignore_errors[, onerror]])
递归的去删除文件
shutil.move(src, dst)
递归的去移动文件
-
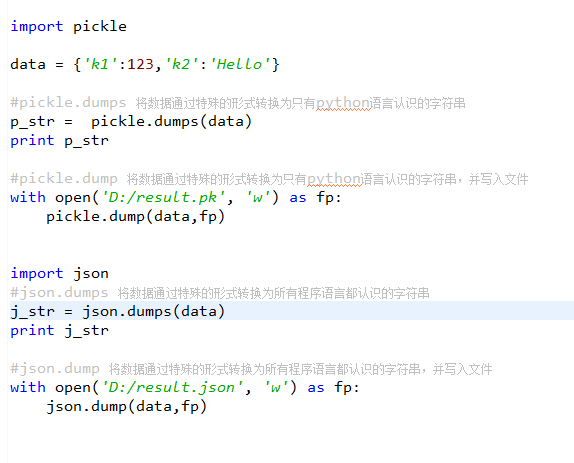
json & picle
用于序列化的两个模块
- json,用于字符串 和 python数据类型间进行转换
- pickle,用于python特有的类型 和 python的数据类型间进行转换
Json模块提供了四个功能:dumps、dump、loads、load
pickle模块提供了四个功能:dumps、dump、loads、load
-
shelve
shelve模块是一个简单的k,v将内存数据通过文件持久化的模块,可以持久化任何pickle可支持的python数据格式
import shelve
d = shelve.open('shelve_test') #打开一个文件
class Test(object):
def __init__(self,n):
self.n = n
t = Test(123)
t2 = Test(123334)
name = ["alex","rain","test"]
d["test"] = name #持久化列表
d["t1"] = t #持久化类
d["t2"] = t2
d.close()
-
xml处理
-
yaml处理
-
configparser
-
hashlib
用于加密相关的操作,代替了md5模块和sha模块,主要提供 SHA1, SHA224, SHA256, SHA384, SHA512 ,MD5 算法
import hashlib
# ######## md5 ########
hash = hashlib.md5()
hash.update('admin')
print hash.hexdigest()
# ######## sha1 ########
hash = hashlib.sha1()
hash.update('admin')
print hash.hexdigest()
# ######## sha256 ########
hash = hashlib.sha256()
hash.update('admin')
print hash.hexdigest()
# ######## sha384 ########
hash = hashlib.sha384()
hash.update('admin')
print hash.hexdigest()
# ######## sha512 ########
hash = hashlib.sha512()
hash.update('admin')
print hash.hexdigest()
以上加密算法虽然依然非常厉害,但时候存在缺陷,即:通过撞库可以反解。所以,有必要对加密算法中添加自定义key再来做加密。
import hashlib
# ######## md5 ########
hash = hashlib.md5('898oaFs09f')
hash.update('admin')
print hash.hexdigest()
还不够吊?python 还有一个 hmac 模块,它内部对我们创建 key 和 内容 再进行处理然后再加密
import hmac
h = hmac.new('wueiqi')
h.update('hellowo')
print h.hexdigest()
不能再牛逼了!!!

-
subprocess
-
logging模块
-
re正则表达式
python中re模块提供了正则表达式相关操作
字符:
. 匹配除换行符以外的任意字符
\w 匹配字母或数字或下划线或汉字
\s 匹配任意的空白符
\d 匹配数字
\b 匹配单词的开始或结束
^ 匹配字符串的开始
$ 匹配字符串的结束
次数:
* 重复零次或更多次
+ 重复一次或更多次
? 重复零次或一次
{n} 重复n次
{n,} 重复n次或更多次
{n,m} 重复n到m次
match
# match,从起始位置开始匹配,匹配成功返回一个对象,未匹配成功返回None
match(pattern, string, flags=0)
# pattern: 正则模型
# string : 要匹配的字符串
# falgs : 匹配模式
X VERBOSE Ignore whitespace and comments for nicer looking RE's.
I IGNORECASE Perform case-insensitive matching.
M MULTILINE "^" matches the beginning of lines (after a newline)
as well as the string.
"$" matches the end of lines (before a newline) as well
as the end of the string.
S DOTALL "." matches any character at all, including the newline.
A ASCII For string patterns, make \w, \W, \b, \B, \d, \D
match the corresponding ASCII character categories
(rather than the whole Unicode categories, which is the
default).
For bytes patterns, this flag is the only available
behaviour and needn't be specified.
L LOCALE Make \w, \W, \b, \B, dependent on the current locale.
U UNICODE For compatibility only. Ignored for string patterns (it
is the default), and forbidden for bytes patterns.
# 无分组
r = re.match("h\w+", origin)
print(r.group()) # 获取匹配到的所有结果
print(r.groups()) # 获取模型中匹配到的分组结果
print(r.groupdict()) # 获取模型中匹配到的分组结果
# 有分组
# 为何要有分组?提取匹配成功的指定内容(先匹配成功全部正则,再匹配成功的局部内容提取出来)
r = re.match("h(\w+).*(?P<name>\d)$", origin)
print(r.group()) # 获取匹配到的所有结果
print(r.groups()) # 获取模型中匹配到的分组结果
print(r.groupdict()) # 获取模型中匹配到的分组中所有执行了key的组
Demo
search
# search,浏览整个字符串去匹配第一个,未匹配成功返回None # search(pattern, string, flags=0)
# 无分组
r = re.search("a\w+", origin)
print(r.group()) # 获取匹配到的所有结果
print(r.groups()) # 获取模型中匹配到的分组结果
print(r.groupdict()) # 获取模型中匹配到的分组结果
# 有分组
r = re.search("a(\w+).*(?P<name>\d)$", origin)
print(r.group()) # 获取匹配到的所有结果
print(r.groups()) # 获取模型中匹配到的分组结果
print(r.groupdict()) # 获取模型中匹配到的分组中所有执行了key的组
demo
findall
# findall,获取非重复的匹配列表;如果有一个组则以列表形式返回,且每一个匹配均是字符串;如果模型中有多个组,则以列表形式返回,且每一个匹配均是元祖; # 空的匹配也会包含在结果中 #findall(pattern, string, flags=0)
# 无分组
r = re.findall("a\w+",origin)
print(r)
# 有分组
origin = "hello alex bcd abcd lge acd 19"
r = re.findall("a((\w*)c)(d)", origin)
print(r)
Demo
sub
# sub,替换匹配成功的指定位置字符串 sub(pattern, repl, string, count=0, flags=0) # pattern: 正则模型 # repl : 要替换的字符串或可执行对象 # string : 要匹配的字符串 # count : 指定匹配个数 # flags : 匹配模式
# 与分组无关
origin = "hello alex bcd alex lge alex acd 19"
r = re.sub("a\w+", "999", origin, 2)
print(r)
split
# split,根据正则匹配分割字符串 split(pattern, string, maxsplit=0, flags=0) # pattern: 正则模型 # string : 要匹配的字符串 # maxsplit:指定分割个数 # flags : 匹配模式
# 无分组
origin = "hello alex bcd alex lge alex acd 19"
r = re.split("alex", origin, 1)
print(r)
# 有分组
origin = "hello alex bcd alex lge alex acd 19"
r1 = re.split("(alex)", origin, 1)
print(r1)
r2 = re.split("(al(ex))", origin, 1)
print(r2)
IP:
^(25[0-5]|2[0-4]\d|[0-1]?\d?\d)(\.(25[0-5]|2[0-4]\d|[0-1]?\d?\d)){3}$
手机号:
^1[3|4|5|8][0-9]\d{8}$
邮箱:
[a-zA-Z0-9_-]+@[a-zA-Z0-9_-]+(\.[a-zA-Z0-9_-]+)+
常用正则表达式

