
xml基础知识
关键词:xml、DTD约束、Schema约束、dom解析、sax解析、jaxp解析器、dom4j解析器
一、xml的简介
1、eXtensible Markup Language:可扩展标记型语言
①标记型语言:HTML是标记型语言,即使用标签来操作。
②可扩展:
- HTML里面的标签是固定,每个标签都有特定的含义<h1><br/><hr/>
- 标签可以自己定义,可以写中文的标签<person></person>、<猫></猫>
2、xml用途
①HTML是用于显示数据,xml也可以显示数据(不是主要功能)
②xml主要功能,为了储存数据
3、xml是W3C组织发布的技术,目前有两个版本1.0、1.1
目前使用的都是1.0版本(1.1版本不能向下兼容)
二、xml的应用
1、不同的系统之间传输数据
2、用来表示生活中有关系的数据
3、经常用在配置文件,如:现在连接数据库,肯定知道数据库的用户名和密码,数据库名称,如果修改数据的信息,不需要修改源代码,只要修改配置文件就可以了。
三、xml的语法
1、xml的文档声明
①创建一个文件 后缀名是 .xml
②如果写xml,第一步必须要有一个文档声明(写了文档声明之后,表示写xml文件的内容)
<?xml version="1.0" encoding="gbk"?>
- 在“<”和“?”之间、“?”和“>”之间和“xml”之间不能有空格。
- 文档声明必须写在第一行第一列
- 属性:
- version:xml的版本1.0(使用)1.1
- encoding:xml编码gbk utf-8 iso8859-1(不包含中文)
- standalone:是否需要依赖其他文件yes/no
③xml的中文乱码问题解决:保存时候和设置打开时的编码一致,不会出现乱码
2、定义元素(标签)
①标签定义
- 标签定义有开始必须有结束:<person></person>
- 标签没有内容,可以在标签内结束:<aa/>
- 标签可以嵌套,必须要合理嵌套
- 合理嵌套:<aa><bb></bb></aa>
- 不合理嵌套:<aa><bb></aa></bb>,这种方式是错误的
- 一个xml中,只能有一个根标签,其他标签都是这个标签下面的标签
- 在xml中把空格和换行都当成内容来解析,
- 下面这两段代码含义是不一样的
<aa>1111111</aa> <aa> 1111111 </aa>
②xml中标签的命名规则(可以用中文)
-
- xml代码区分大小写,如<p><P>是两个不同的标签
- 不能以数字或“_”(下划线)开头
- 不能以xml(或XML、或Xml等)开头
- 不能包含空格
- 名称中间不能包含冒号(:)。
3、定义属性
①在xml文档中,可以为元素定义属性
<person id1="aa" id2="bb"></person>
②属性定义要求
- 一个标签上可以有多个属性,如:<person id1="aa" id2="bb"></person>
- 属性名称不能相同,如<person id="aa" id="bb"></person>,出现错误
- 属性名称和属性值之间使用=,属性值使用引号包起来(可以是单引号,也可以双引号)
- xml属性的命名规范和元素的命名规范一致
4、注释
写法:<!-- 注释信息 -->
- 注释不能放到第一行,第一行必须放文档说明
- 注释不能出现在标记中,如非法写法: <greeting <!--Begin greet-->></greeting>
- 字符串“--”不能出现在注释中,如非法写法: <!--This is a Example--Hello World-->
- 在xml中,不允许注释以“--->”结尾。
- 注释不嵌套
5、特殊字符
利用转义字符
| 特殊符号 | 预定义实体 | 特殊符号 | 预定义实体 |
| & | & | " | " |
| < | < | ' | &apos |
| > | > |
6、CDATA区
可以解决多个字符都需要转义的操作 if (a<b && b<c && d>f){}
把这些内容放到CDATA区里面,不需要转义了
写法: <![CDATA[ 内容 ]]>
如: <![CDATA[ <b>if (a<b && b<c && d>f){} </b> ]]>
把特殊字符当做文本内容,而不是标签
7、PI指令(处理指令)(了解)
可以在xml中设置样式
写法: <?xml-stylesheet type="text/css" href="css的路径"?>
设置样式,只能对英文标签名称起作用,对于中文的标签名称不起作用的。
8、xml语法总结:
- 所有xml元素都必须有关闭标签
- xml 标签对大小写敏感
- xml 必须正确嵌套顺序
- xml文档必须有根元素(只有一个)
- xml 的属性值需加引号
- 特殊字符必须转义 ----CDATA
- xml 中的空格、回车换行会解析时被保留
四、xml的约束
约束的作用:
如现在定义一个person的xml文件,只想要这个文件里面保存人的信息,比如name age等,但是如果在xml文件中写一个标签<猫>,发现可以正常显示,因为符合语法规范。但是猫肯定不是人的信息,xml的标签是自定义的,需要技术来规定xml中只能出现的元素,这个时候需要约束。
xml的约束的技术:DTD约束 和Schema约束。
1、DTD的快速入门
创建一个文件,后缀名为“.dtd”
步骤:
(1) 看xml中有几个元素,有几个元素,在dtd文件中写几个<!ELEMENT>
(2) 判断元素是简单元素还是复杂元素
-复杂元素:有子元素的元素
<!ELEMENT 元素名称 (子元素)>
-简单元素:没有子元素
<!ELEMENT 元素名称 (#PCDATA)>
(3)需要在xml文件中引入dtd文件三种引入方式:
①引入外部的dtd文件
<!DOCTYPE 根元素名称 SYSTEM “dtd文件的路径”>
②使用内部的dtd文件
<!DOCTYPE 书架 [ <!ELEMENT 书架 (书+)> <!ELEMENT 书 (书名,作者,售价)> <!ELEMENT 书名 (#PCDATA)> <!ELEMENT 作者 (#PCDATA)> <!ELEMENT 售价 (#PCDATA)> ]>
③使用外部的dtd文件(网络上的dtd文件)
<!DOCTYPE 根元素名称 PUBLIC "DTD名称" “DTD文件的URL”>
在框架struts2使用配置文件 使用外部的dtd文件
示例:
<?xml version="1.0" encoding="utf-8"?> <!DOCTYPE 书架 SYSTEM "book.dtd"> <书架> <书> <书名>Java就业培训教程</书名> <作者>张孝祥</作者> <售价>58.00元</售价> <!--如果添加dtd中无添加的元素,就会报错,即为约束--> </书> <书> <书名>EJB3.0入门经典</书名> <作者>黎活明</作者> <售价>39.00元</售价> </书> </书架>
book.dtd :
<!ELEMENT 书架 (书+)> <!ELEMENT 书 (书名,作者,售价)> <!ELEMENT 书名 (#PCDATA)> <!ELEMENT 作者 (#PCDATA)> <!ELEMENT 售价 (#PCDATA)>
2、使用dtd定义元素
语法: <!ELEMENT 元素名 约束>
-简单元素:没有子元素
<!ELEMENT 元素名称 (#PCDATA)>
-
- (#PCDATA):约束元素为字符串类型
- EMPTY:约束元素为空
- ANY:任意
-复杂元素:有子元素的元素
<!ELEMENT 元素名称 (子元素)>
表示子元素出现的次数
-
- +:表示一次或者多次
- ?:表示零次或者一次
- *:表示零次或者多次
子元素直接使用逗号“,”进行隔开,表示元素出现的顺序
子元素直接使用“|”隔开,表示元素只能出现其中的任意一个
括号“()”,用于给元素进行分组
示例:
<!ELEMENT person (name+,age?,sex*,school)>
3、使用dtd定义属性
①语法: <!ATTLIST 元素名称 属性名称 属性类型 属性的约束 >
②属性类型:
-CDATA:字符串
<!ATTLIST birthday ID1 CDATA #REQUIRED >
-枚举:表示只能在一定范围内出现值,但是只能每次出现其中的一个
如:红绿灯效果、(aa|bb|cc)
<!ATTLIST age ID2 (AA|BB|CC) #REQUIRED >
-ID:值只能是字母或下划线开头
<!ATTLIST name ID3 ID #REQUIRED>
③属性的约束
-#REQUIRED:属性必须存在
-#IMPLIED:属性可有可无
-#FIXED:表示一个固定值 ,如#FIXED "AAA"
属性的值必须是设置的这个固定值
<!ATTLIST sex ID4 CDATA #FIXED "AAA">
-直接值
不写属性,使用直接值
写了属性,使用设置那个值
<!ATTLIST school ID5 CDATA “WWW”>
4、实体的定义
语法: <!ENTITY 实体名称 “实体的值”>
<!ENTITY TEST "HAHAHA">
使用实体 &实体名称; 比如: &TEST;
注意:定义实体需要写在内部dtd里面,如果写在外部的dtd里面,在某些浏览器下,内容无法显示。
五、xml解析的简介
1、xml是标记型文档
2、js使用dom解析标记型文档?
根据html的层级结构,在内存中分配一个树形结构,把html的标签,树形结构,把html的标签,属性和文本都封装成对象
document对象、element对象、属性对象、文本对象、Node节点对象
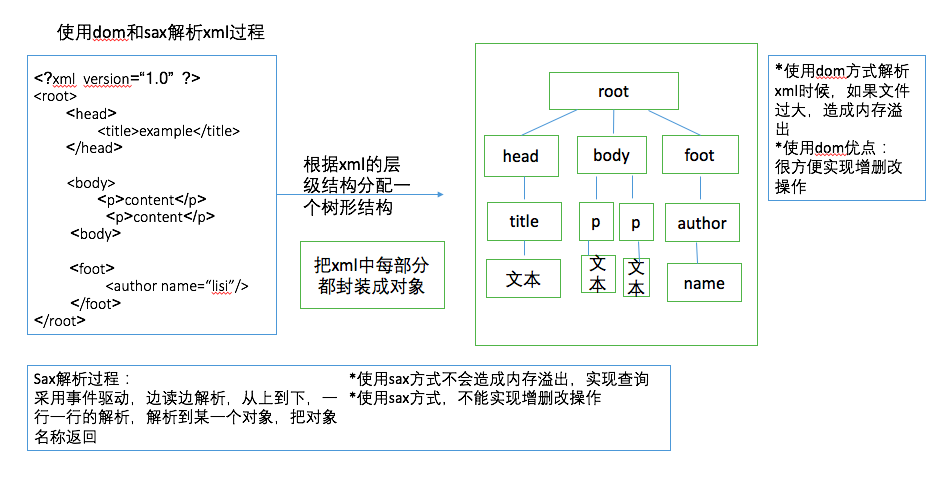
3、xml的解析方式(技术):dom和sax
①dom解析和sax解析区别:
dom方式解析:根据xml的层级结构在内存中分配一个树形结构,把xml的标签,属性和文本都封装成对象
缺点:如果文件过大,造成内存溢出
优点:很方便实现增删改操作
sax方式解析:采用事件驱动,边读边解析,
从上到下,一行一行的解析,解析到某一个对象,把对象名称返回
缺点:不能实现增删改操作
优点:如果文件过大不会造成内存溢出,实现查询操作
②xml解析器:不同的公司和组织提供了针对dom和sax方式的解析器,通过api方式提供
- sun公司提供了针对dom和sax解析器 jaxp
- dom4j组织,针对dom和sax解析器 dom4j(实际开发中使用)
- jdom组织,针对dom和sax解析器 jdom
4、jaxp的api的查看
jaxp是javase中的一部分,jaxp解析器在jdk的javax.xml.parsers包里面
四个类:分别是针对dom和sax解析使用的类
①dom:
DocumentBuilder:解析器类
-抽象类,不能new
此类的实例可以从DocumentBuilderFactory.newDocumentBuilder() 方法获取
-一个方法,可以解析xml parse(“xml”路径) 返回是Document整个文档
-返回的document是一个接口,父节点是Node,如果在document里面找不到想要的方法,到Node里面去找
-在document里面方法
getElementsByTagName(String tagname)
--这个方法可以得到标签
--返回集合NodeList
createElement(String tagName)
--创建标签
createTextNode(String data)
--创建文本
appendChild(Node newChild)
--把文本添加到标签下面
removeChild(Node oldChild)
--删除节点
getParentNode()
--获取父节点
getTextContent()
--得到标签里面的内容
DocumentBuilderFactory:解析器工厂
②sax:
SAXParser: 解析器类
SAXParserFactory:解析器工厂
5、使用jaxp实现增删改查操作
①、使用jaxp实现查询操作
查询xml中所有的name元素的值
步骤:
1、创建解析器工厂
DocumentBuilderFactory.newInstance();
2、根据解析器工厂创建解析器
builderFactory.newDocumentBuilder();
3、解析xml返回document
Document document = builder.parse(uri);
4、得到所有的name元素
使用document.getElementsByTagName("name");
5、返回集合,遍历集合,得到每一个name元素
-遍历 getLength() item()
-得到元素里面值 使用getTextContent()
查询xml中第一个name元素的值
步骤:
1、创建解析器工厂
2、根据解析器工厂创建解析器
3、解析xml返回document
4、得到所有的name元素
5、使用返回集合,里面方法item,下标获取具体的元素
Nodelist.item(下标):集合下标从0开始
6、得到具体的值,使用getTextContent方法
②使用jaxp添加节点
在第一个p1下面(末尾)添加<sex>nv</sex>
步骤:
1、创建解析器工厂
2、根据解析器工厂创建解析器
3、解析xml返回document
4、得到第一个p1(得到所有p1,使用item方法下标得到)
5、创建sex标签createElementNode
6、串及文本createTextNode
7、把文本添加到sex下面appendChild
8、把sex添加到第一个p1下面
9、回写xml
③使用jaxp修改节点
修改第一p1下面的sex内容是男
步骤:
1、创建解析器工厂
2、根据解析器工厂创建解析器
3、解析xml返回document
4、得到sex item方法
5、修改sex里面的值setTextContent方法
6、回写xml
④使用jaxp删除节点
删除<sex>男</sex>节点
步骤:
1、创建解析器工厂
2、根据解析器工厂创建解析器
3、解析xml返回document
4、获取sex元素
5、获取sex的父节点,使用getParentNode方法
6、删除,使用父节点删除removeChild方法
7、回写xml
⑤使用jaxp遍历节点
遍历节点,把xml中的所有元素名称打印出来
步骤:
1、创建解析器工厂
2、根据解析器工厂创建解析器
3、解析xml返回document
===使用递归实现======
4、得到根节点
5、得到根节点子节点
6、得到根节点子节点的子节点
遍历方法:
private static void list1(Node node) { //判断元素类型时候才打印 if (node.getNodeType() == Node.ELEMENT_NODE){ System.out.println(node.getNodeName()); } //得到一层子节点 NodeList list = node.getChildNodes(); //遍历list for(int i=0; i<list.getLength();i++){ //继续得到node1的子节点 Node node1 = list.item(i); list1(node1); } }
实例:
xml文档:
<?xml version="1.0" encoding="UTF-8" standalone="no"?><person> <p1> <name>zhangsan</name> <age>20</age> <sex>女</sex> </p1> <p1> <name>lisi</name> <age>30</age> </p1> </person>}
1 package jaxptest; 2 import org.w3c.dom.*; 3 import javax.xml.parsers.DocumentBuilder; 4 import javax.xml.parsers.DocumentBuilderFactory; 5 import javax.xml.transform.Transformer; 6 import javax.xml.transform.TransformerFactory; 7 import javax.xml.transform.dom.DOMSource; 8 import javax.xml.transform.stream.StreamResult; 9 10 public class TestJaxp { 11 public static void main(String[] args) throws Exception{ 12 String uri = "src/person.xml"; 13 // selectAll(uri); 14 // selectSin(uri); 15 // addSex(uri); 16 // modifySex(uri); 17 // delSex(uri); 18 listElement(uri); 19 } 20 //解析dom方法解析xml文档方法 21 private static Document jaxpParseXml(String uri) throws Exception { 22 //创建解析器工厂 23 DocumentBuilderFactory builderFactory = DocumentBuilderFactory.newInstance(); 24 //创建解析器 25 DocumentBuilder builder = builderFactory.newDocumentBuilder(); 26 //解析xml返回document 27 Document document = builder.parse(uri); 28 return document; 29 } 30 //回写xml方法 31 private static void writeBack(Document document,String uri) throws Exception{ 32 TransformerFactory transformerFactory = TransformerFactory.newInstance(); 33 Transformer transformer = transformerFactory.newTransformer(); 34 transformer.transform(new DOMSource(document),new StreamResult(uri)); 35 } 36 //查询所有name元素的值 37 public static void selectAll(String uri) throws Exception { 38 //查询所有name元素的值 39 /* 40 * 1、创建解析器工厂 41 * 2、根据解析器工厂创建解析器 42 * 3、解析xml返回document 43 * 4、得到所有的name元素 44 * 5、返回集合,遍历集合,得到每一个name元素 45 * */ 46 Document document = jaxpParseXml(uri); 47 //得到name元素 48 NodeList list = document.getElementsByTagName("name"); 49 //遍历集合 50 for(int i=0;i<list.getLength();i++) { 51 Node name1 = list.item(i); 52 //得到name1元素里面的值 53 String s = name1.getTextContent(); 54 System.out.println(s); 55 } 56 } 57 //查询xml中第一个name元素的值 58 public static void selectSin(String uri) throws Exception{ 59 /* 60 * 1、创建解析器工厂 61 * 2、根据解析器工厂创建解析器 62 * 3、解析xml返回document 63 * 4、得到所有的name元素 64 * 5、使用返回集合,里面方法item,下标获取具体的元素 65 * 6、得到具体的值,使用getTextContent方法 66 * */ 67 Document document = jaxpParseXml(uri); 68 NodeList list = document.getElementsByTagName("name"); 69 Node name1 = list.item(0); 70 String s1 = name1.getTextContent(); 71 System.out.println(s1); 72 } 73 //在第一个p1下面(末尾)添加<sex>nv</sex> 74 public static void addSex(String uri) throws Exception { 75 /* 76 * 1、创建解析器工厂 77 * 2、根据解析器工厂创建解析器 78 * 3、解析xml返回document 79 * 4、得到第一个p1(得到所有p1,使用item方法下标得到) 80 * 5、创建sex标签createElementNode 81 * 6、串及文本createTextNode 82 * 7、把文本添加到sex下面appendChild 83 * 8、把sex添加到第一个p1下面 84 * 9、回写xml 85 * */ 86 Document document = jaxpParseXml(uri); 87 NodeList list = document.getElementsByTagName("p1"); 88 Node p1 = list.item(0); 89 Element sex1 = document.createElement("sex"); 90 Text text = document.createTextNode("女"); 91 sex1.appendChild(text); 92 p1.appendChild(sex1); 93 writeBack(document,uri); 94 } 95 //修改第一p1下面的sex内容是男 96 public static void modifySex(String uri) throws Exception{ 97 /* 98 * 1、创建解析器工厂 99 * 2、根据解析器工厂创建解析器 100 * 3、解析xml返回document 101 * 4、得到sex item方法 102 * 5、修改sex里面的值setTextContent方法 103 * 6、回写xml 104 * */ 105 Document document = jaxpParseXml(uri); 106 Node sex1 = document.getElementsByTagName("sex").item(0); 107 sex1.setTextContent("男"); 108 writeBack(document,uri); 109 } 110 //删除<sex>男</sex>节点 111 public static void delSex(String uri) throws Exception{ 112 /* 113 * 1、创建解析器工厂 114 * 2、根据解析器工厂创建解析器 115 * 3、解析xml返回document 116 * 4、获取sex元素 117 * 5、获取sex的父节点,使用getParentNode方法 118 * 6、删除,使用父节点删除removeChild方法 119 * 7、回写xml 120 * */ 121 Document document = jaxpParseXml(uri); 122 Node sex1 = document.getElementsByTagName("sex").item(0); 123 Node p1 = sex1.getParentNode(); 124 p1.removeChild(sex1); 125 writeBack(document,uri); 126 } 127 //遍历节点,把xml中的所有元素名称打印出来 128 public static void listElement(String uri) throws Exception { 129 /* 130 * 1、创建解析器工厂 131 * 2、根据解析器工厂创建解析器 132 * 3、解析xml返回document 133 * ===使用递归实现====== 134 * 4、得到根节点 135 * 5、得到根节点子节点 136 * 6、得到根节点子节点的子节点 137 * */ 138 Document document = jaxpParseXml(uri); 139 //编写一个方法实现遍历操作 140 list1(document); 141 } 142 private static void list1(Node node) { 143 //判断元素类型时候才打印 144 if (node.getNodeType() == Node.ELEMENT_NODE){ 145 System.out.println(node.getNodeName()); 146 } 147 //得到一层子节点 148 NodeList list = node.getChildNodes(); 149 //遍历list 150 for(int i=0; i<list.getLength();i++){ 151 //继续得到node1的子节点 152 Node node1 = list.item(i); 153 list1(node1); 154 } 155 }
六、Schema约束
(一)schema介绍
dtd语法:<!ELEMENT 元素名称 约束>
schema符号xml的语法,xml语句
一个xml中可以有多个schema,多个schema使用名称空间区分(类似于Java包名)
dtd里面有PCDATA类型,但是在schema里面可以支持更多的数据类型
比如年龄只能是整数,在schema中可以直接定义一个整数类型
schema语法更加复杂,schema目前不能替代dtd
(二)schema的快速入门
创建一个schema文件,后缀名是“.xsd”
根节点<schema>
1、在schema文件中
属性 xmlns="http://www.w3.org/2001/XMLSchema"
-表示当前xml是一个约束文件
targetNamespace="http://www.itcast.cn/201711111"
-使用schema约束文件,直接通过这个地址引入约束文件
elementFormDefault="qualified"
2、步骤:
①看xml中有多少个元素
<element>
②看简单元素和复杂元素
如复杂元素:
<complexType> <sequence> 子元素 </sequence> </complexType>
③简单元素,写在复杂元素的子元素位置
<element name="person"> <complexType> <sequence> <element name="name" type="string"></element> <element name="age" type="int"></element> </sequence> </complexType> </element>
④在被约束文件里面引入约束文件
<person xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="http://www.itcast.cn/201711111" xsi:schemaLocation="http://www.itcast.cn/201711111 1.xsd">
- xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" --表示xml是一个被约束文件
- xmlns="http://www.itcast.cn/201711111" --是约束文档中targetNamespace
- xsi:schemaLocation="http://www.itcast.cn/201711111 1.xsd" --targetNamespace 空格 约束文档的地址
3、XMLSchema复杂元素指示器
-
- <sequence>:表示元素的出现的顺序
- <all>:元素只能出现一次
- <choice>:元素只能出现其中的一个
- maxOccurs="unbounded" :表示元素的出现的次数,如:<element name="name" type="string" maxOccurs="unbounded"></element>
- <any></any>:表示任意元素
可以约束属性
写在复杂元素里面
写在</complexType>之前
--
<attribute name="id1" type="int" use="required"></attribute>
-name :属性名称
-type:属性类型int string
-use:属性是否必须出现 required
4、复杂的schema约束
<company xmlns = "http://www.example.org/company"
xmlns:dept = "http://www.example.org/department"
xmlns:xsi = "http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation = "http://www.example.org/company company.xsd http://www.example.org/department denpartment.xsd">
*引入多个schema文件,可以给每个起一个别名
如:
<employee age="30">
<!-- 部门名称 -->
<dept:name>100</dept:name>
*想要引入部门的约束文件里的那么,使用部门的别名 detp:元素名称
<!-- 员工名称 -->
<name>张三</name>
</employee>
示例:
xml文档
<?xml version="1.0" encoding="UTF-8" ?> <person xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="http://www.itcast.cn/201711111" xsi:schemaLocation="http://www.itcast.cn/201711111 1.xsd"> <name>zhangsan</name> <age>20</age> </person>
xsd文档
<?xml version="1.0" encoding="UTF-8" ?> <schema xmlns="http://www.w3.org/2001/XMLSchema" targetNamespace="http://www.itcast.cn/201711111" elementFormDefault="qualified"> <element name="person"> <complexType> <sequence> <element name="name" type="string"></element> <element name="age" type="int"></element> </sequence> </complexType> </element> </schema>
七、sax解析
1、sax解析
解析xml有两种技术 dom和sax
dom方式解析:
根据xml的层级结构在内存中分配一个树形结构,
把xml的标签,属性和文本都封装成对象
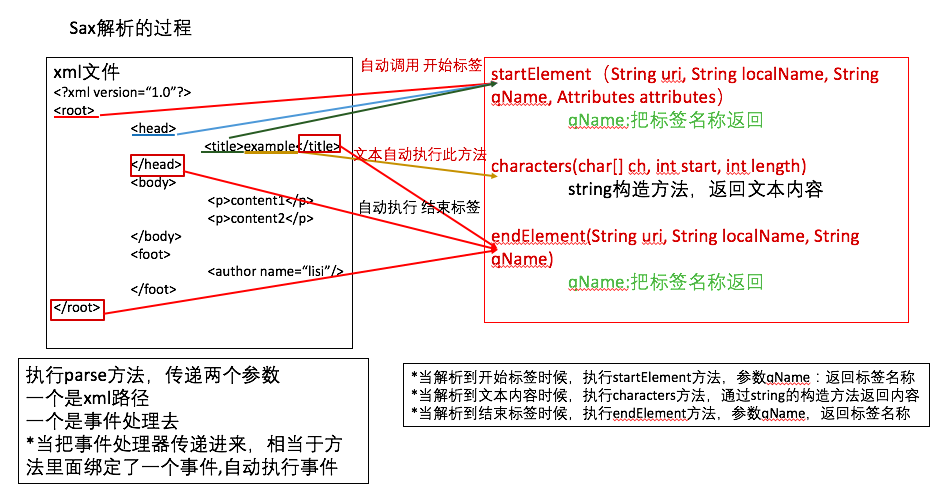
sax方式解析:
采用事件驱动,边读边解析,
在java.xml.parsers包里面
-SAXParser
此类的实例可以从SAXParserFactory.newSAXParser()方法获得
-parse(File f,DefaultHandler dh)
第一个参数:xml的路径
第二个参数:事件处理器
-SAXParserFactory
实例newInstance()方法得到
sax执行过程:
2、使用jaxp的sax方式解析xml
sax方式不能实现增删改操作,只能做查询操作
打印出整个文档
-执行parse方法,第一个参数xml路径,第二个参数是事件处理器
-创建一个类,继承事件处理器的类,重写里面的三个方法
获取到所有的name元素的值
-定义一个成员变量flag=false
-判断开始方法是否是name元素,如果是name元素,把flag值设置成true
-如果flag值是true,在characters方法里面打印内容
-当执行到结束方法时候,把flag值设置成false
获取第一个name元素的值
-定义一个成员变量idx=1
-在结束方法时候,idx++
-想要打印出第一个name元素的值,在characters方法里面判断
实例:
1 import org.xml.sax.Attributes; 2 import org.xml.sax.SAXException; 3 import org.xml.sax.helpers.DefaultHandler; 4 import javax.xml.parsers.SAXParser; 5 import javax.xml.parsers.SAXParserFactory; 6 7 public class TestSax { 8 public static void main(String[] args) throws Exception { 9 /* 10 * 1、创建解析工厂 11 * 2、创建解析器 12 * 3、执行parse方法 13 * 4、自己创建一个类,继承DefaultHandler 14 * 5、重写里面的三个方法 15 * */ 16 SAXParserFactory saxParserFactory = SAXParserFactory.newInstance(); 17 SAXParser saxParser = saxParserFactory.newSAXParser(); 18 saxParser.parse("src/p1.xml",new MyDefault2()); 19 saxParser.parse("src/p1.xml",new MyDefault1()); 20 } 21 } 22 //实现获取第一个name元素 23 class MyDefault2 extends DefaultHandler { 24 boolean flag = false; 25 int index = 1; 26 @Override 27 public void startElement(String uri, String localName, String qName,
Attributes attributes) throws SAXException { 28 //判断qName是否是name元素 29 if ("name".equals(qName)) { 30 flag = true ; 31 } 32 } 33 @Override 34 public void characters(char[] ch, int start, int length) throws SAXException { 35 //当flag值是true时候,表示解析到name元素 36 if (flag == true && index == 1){ 37 System.out.println(new String(ch,start,length)); 38 } 39 } 40 @Override 41 public void endElement(String uri, String localName, String qName) throws SAXException { 42 //把flag设置成false,表示name元素结束 43 if ("name".equals(qName)) { 44 flag = false; 45 } 46 index++; 47 } 48 }
//获取所有name元素 49 class MyDefault1 extends DefaultHandler { 50 @Override 51 public void startElement(String uri, String localName, String qName, 52 Attributes attributes) throws SAXException { 53 System.out.print("<"+qName+">"); 54 } 55 @Override 56 public void characters(char[] ch, int start, int length) throws SAXException { 57 System.out.print(new String(ch,start,length)); 58 } 59 @Override 60 public void endElement(String uri, String localName, String qName) throws SAXException { 61 System.out.print("</"+ qName+">"); 62 } 63 }
xml文件:
<?xml version="1.0" encoding="UTF-8" ?> <person> <p1> <name>zhangsan</name> <age>20</age> </p1> <p1> <name>lisi</name> <age>25</age> </p1> </person>
八、使用dom4j解析xml
1、dom4j
dom4j使用一个组织,针对xml解析,提供解析器dom4j,非javase的一部分,需导入jar包
得到document
SAXReader reader = new SAXReader();
Document document = reader.read(url);
document的父接口是Node
如果在document里面找不到想要的方法,到Node里面去找
document里面的方法getRootElement():获取根节点返回的是Element
Element也是一个接口,父接口是Node
-Element和Node里面方法
getParent():获取父节点
addElement:添加标签
2、使用dom4j对xml进行增删改查操作
①查询所有name元素里面的值
步骤:
1、创建解析器
2、得到document
3、得到根节点 getRootElement()
4、得到所有的p1标签
-element(qname)
-表示获取标签下面的第一个子标签
-qname:标签名称
-elements(qname)
-获取标签下面是这个名称的所有子标签(一层)
-qname:标签名称
-elements()
-获取标签下面的所有一层子标签
5、得到name
6、得到name里面的值
②使用dom4j对xml进行增删改查操作示例以及方法的封装
xml文档:
<?xml version="1.0" encoding="UTF-8"?> <person> <p1 id1="aaa"> <name>zhangsan</name> <age>30</age> <sex>女</sex> </p1> <p1> <name>lisi</name> <age>25</age> </p1> </person>
java文档:
1 package testDom4j; 2 3 import dom4jutils.Dom4jUtils; 4 import org.dom4j.Document; 5 import org.dom4j.DocumentHelper; 6 import org.dom4j.Element; 7 import org.dom4j.io.OutputFormat; 8 import org.dom4j.io.SAXReader; 9 import org.dom4j.io.XMLWriter; 10 11 import java.io.FileOutputStream; 12 import java.util.List; 13 14 public class TestDom4j { 15 public static void main(String[] args) throws Exception { 16 // selectName(); 17 // selectSin(); 18 // selectSecond(); 19 // addSex(); 20 // addAgeBefore(); 21 // modifyAge(); 22 // deleteSchool(); 23 getValues(); 24 } 25 //查询xml中所有name元素的值 26 public static void selectName() throws Exception{ 27 /* 28 * 1、创建解析器 29 * 2、得到document 30 * 3、得到根节点 getRootElement() 返回Element 31 * 4、得到所有的p1标签 32 * -elements("p1") 返回Element 33 * 5、得到name 34 * -在p1下面执行element("name")的方法返回Element 35 * 6、得到name里面的值 36 * -getText方法得到值 37 * */ 38 //创建解析器 39 SAXReader reader = new SAXReader(); 40 //得到document 41 Document document = reader.read("src/p1.xml"); 42 //得到根节点 43 Element root = document.getRootElement(); 44 //得到p1 45 List<Element> list = root.elements("p1"); 46 //遍历list 47 for(Element element : list) { 48 //element是每一个p1 49 //得到p1下面的name元素 50 Element name1 = element.element("name") ; 51 //得到name里面的值 52 String s = name1.getText(); 53 System.out.println(s); 54 } 55 } 56 57 //获取得到第一个name元素的值 58 public static void selectSin() throws Exception { 59 /* 60 * 1、创建解析器 61 * 2、得到document 62 * 3、得到根节点 63 * 4、得到第一个p1标签 64 * 5、得到p1下面的name元素 65 * 6、得到name里面的值 66 * */ 67 Document document = Dom4jUtils.getDocument(Dom4jUtils.PATH); 68 Element root = document.getRootElement(); 69 Element p1 = root.element("p1"); 70 Element name1 = p1.element("name"); 71 System.out.println(name1.getText()); 72 } 73 //获取得到第二个name元素的值 74 public static void selectSecond() throws Exception { 75 /* 76 * 1、创建解析器 77 * 2、得到document 78 * 3、得到根节点 79 * 4、得到所有的p1 80 * 5、遍历得到第二p1 81 * 6、得到第二个p1下面的name 82 * 7、得到name的值 83 * */ 84 Document document = Dom4jUtils.getDocument(Dom4jUtils.PATH); 85 Element root = document.getRootElement(); 86 List<Element> list = root.elements("p1"); 87 Element p2 = list.get(1); 88 Element name2 = p2.element("name"); 89 System.out.println(name2.getText()); 90 } 91 92 //在第一个p1标签末尾添加一个元素<sex>女</sex> 93 public static void addSex() throws Exception { 94 /* 95 * 1、创建解析器 96 * 2、得到document 97 * 3、得到根节点 98 * 4、获取第一个p1 99 * 5、在p1下面添加元素 100 * 6、在添加完成之后的元素下面添加文本 101 * 7、回写xml 102 * */ 103 Document document = Dom4jUtils.getDocument(Dom4jUtils.PATH); 104 Element root = document.getRootElement(); 105 //得到第一个p1元素 106 Element p1 = root.element("p1"); 107 //在p1下面直接添加元素 108 Element sex1 = p1.addElement("sex"); 109 //在sex下面添加文本 110 sex1.setText("女"); 111 //回写xml 112 OutputFormat format = OutputFormat.createPrettyPrint(); 113 XMLWriter xmlWriter = new XMLWriter(new FileOutputStream("src/p1.xml"),format); 114 xmlWriter.write(document); 115 xmlWriter.close(); 116 } 117 118 //在特定位置添加元素,在第一个p1下面的age标签之前添加<school>ecit</school> 119 public static void addAgeBefore() throws Exception { 120 /* 121 * 1、创建解析器 122 * 2、得到document 123 * 3、得到根节点 124 * 4、获取第一个p1 125 * 5、在p1下面所有的元素 126 * 6、在指定位置添加元素 127 * 7、回写xml 128 * */ 129 //获得document 130 Document document = Dom4jUtils.getDocument(Dom4jUtils.PATH); 131 Element root = document.getRootElement(); 132 Element p1 = root.element("p1") ; 133 //获取p1下所有元素的集合 134 List<Element> list = p1.elements(); 135 //创建元素 136 Element school = DocumentHelper.createElement("school"); 137 school.setText("ecit"); 138 //在指定位置添加元素 139 list.add(1,school); 140 //回写xml 141 Dom4jUtils.xmlWriters(Dom4jUtils.PATH,document); 142 } 143 //修改节点的操作,修改第一个p1下面的age元素值为30 144 public static void modifyAge() throws Exception { 145 /* 146 * 1、得到document 147 * 2、得到根节点 148 * 3、获取第一个p1 149 * 4、得到p1下面的age 150 * 5、修改为30 151 * 6、回写xml 152 * */ 153 Document document = Dom4jUtils.getDocument(Dom4jUtils.PATH); 154 Element root = document.getRootElement(); 155 Element p1 = root.element("p1"); 156 Element age = p1.element("age"); 157 //使用setText()方法修改文本内容 158 age.setText("30"); 159 Dom4jUtils.xmlWriters(Dom4jUtils.PATH,document); 160 } 161 //使用dom4j实现删除节点的操作,删除第一个p1下面的<school>ecit<school>元素 162 public static void deleteSchool() throws Exception{ 163 /* 164 * 1、得到document 165 * 2、得到根节点 166 * 3、获取第一个p1 167 * 4、得到第一个p1下面的school 168 * 5、删除(使用p1删除school) 169 * -得到school的父节点 170 * -第一种直接得到p1 171 * -使用方法getParent方法 172 * -在p1上面执行remove方法删除节点 173 * 6、回写xml 174 * */ 175 Document document = Dom4jUtils.getDocument(Dom4jUtils.PATH); 176 Element root = document.getRootElement(); 177 Element p1 = root.element("p1"); 178 Element sch = p1.element("school"); 179 //通过父节点删除 180 p1.remove(sch); 181 Dom4jUtils.xmlWriters(Dom4jUtils.PATH,document); 182 } 183 //使用dom4j获取属性的操作,获取第一个p1的属性id1的值 184 public static void getValues() throws Exception { 185 /* 186 * 1、得到document 187 * 2、得到根节点 188 * 3、获取第一个p1 189 * 4、得到第一个p1的值 190 * */ 191 Document document = Dom4jUtils.getDocument(Dom4jUtils.PATH); 192 Element root = document.getRootElement(); 193 Element p1 = root.element("p1"); 194 String value = p1.attributeValue("id1"); 195 System.out.println(value); 196 } 197 }
1 package dom4jutils; 2 3 import org.dom4j.Document; 4 import org.dom4j.DocumentException; 5 import org.dom4j.io.OutputFormat; 6 import org.dom4j.io.SAXReader; 7 import org.dom4j.io.XMLWriter; 8 9 import java.io.FileOutputStream; 10 import java.io.IOException; 11 12 public class Dom4jUtils { 13 public static final String PATH="src/p1.xml"; 14 //返回document 15 public static Document getDocument(String path) { 16 try { 17 //创建解析器 18 SAXReader reader = new SAXReader(); 19 //得到document 20 Document document = reader.read(path); 21 return document; 22 } catch (DocumentException e) { 23 e.printStackTrace(); 24 } 25 return null; 26 } 27 //回写xml 28 public static void xmlWriters(String path,Document document) { 29 try { 30 OutputFormat format = OutputFormat.createPrettyPrint(); 31 XMLWriter xmlWriter = new XMLWriter(new FileOutputStream(path),format); 32 xmlWriter.write(document); 33 xmlWriter.close(); 34 } catch (IOException e) { 35 e.printStackTrace(); 36 } 37 } 38 }
3、使用dom4j支持xpath的操作
可以直接获取到某个元素
第一种形式
/AAA/DDD/BBB:表示一层一层的,AAA下面DDD下面的BBB
第二种形式
//BBB:表示和这个名称相同,只要是名称是BBB,都得到
第三种形式
/* :所有元素
第四种形式
** BBB[1] :表示第一个BBB元素
** BBB[last()] :表示最后一个BBB元素
第五种形式
** //BBB[@id]:表示只要BBB元素上面有id属性,都得到
第六种形式
** //BBB[@id='b1'] :表示元素名称是BBB,在BBB上面有id属性,并且id的属性值是b1
①具体操作:
默认情况下,dom4j不支持xpath,需导入jaxen-1.1-beta-6.jar
在dom4j里面提供了两个方法,用来支持xpath
-selectNodes("xpath表达式") ,获取多个节点
-selectionSingleNode(“xpath”表达式),获取一个节点
*使用xpath实现:查询xml中所有name元素的值
-所有name元素的xpath表示://name
-使用selectionNodes(“//name”);
代码和步骤:
/* * 1、得到document * 2、直接使用selectNodes("//name")方法的到所有的name元素 * */ //得到document Document document = Dom4jUtils.getDocument(Dom4jUtils.PATH); //使用selectNodes("//name")方法得到所有的name元素 List<Node> list = document.selectNodes("//name"); for (Node node : list){ //node是每一个name元素 String s = node.getText(); System.out.println(s); }
*使用xpath实现:获取第一个p1下面的name的值
-//p1[@id1='aaa']/name
-使用到selectSingleNode(“//p1[@id1='aaa']/name”)
九、实现简单的学生管理系统
1、xml文档,用于储存信息:
<?xml version="1.0" encoding="UTF-8"?> <student> <stu> <id>100</id> <name>zhangsan</name> <age>20</age> </stu> <stu> <id>101</id> <name>zhangsan</name> <age>30</age> </stu> </student>
2、构建service jar包用于查询、添加、删除方法的存储
1 package service; 2 3 import org.dom4j.Document; 4 import org.dom4j.Element; 5 import org.dom4j.Node; 6 import vo.Student; 7 import java.util.List; 8 9 public class StuService { 10 11 //查询 根据id查询学生信息 12 public static Student getStu(String id) throws Exception { 13 /* 14 * 1、创建解析器 15 * 2、得到document 16 * 3、获取所有的id 17 * 18 * 4、返回list集合,遍历list集合 19 * 5、得到每一个id的节点 20 * 6、id节点的值 21 * 7、判断id的值和传递的id值是否相同 22 * 8、如果相同,先获取到id的父节点stu 23 * 9、通过stu获取到name age值 24 * */ 25 Document document = StudentUtils.getDocument(StudentUtils.PATH); 26 List<Node> list = document.selectNodes("//id"); 27 Student student = new Student(); 28 for (Node node : list) { 29 String idv = node.getText(); 30 if (idv.equals(id)) { 31 Element stu = node.getParent(); 32 String namev = stu.element("name").getText(); 33 String agev = stu.element("age").getText(); 34 student.setId(idv); 35 student.setName(namev); 36 student.setAge(agev); 37 } 38 } 39 return student; 40 } 41 //增加 42 public static void addStu(Student student) throws Exception { 43 /* 44 * 1、创建解析器 45 * 2、得到document 46 * 3、获得根节点 47 * 4、在根节点上面创建stu标签 48 * 5、在stu标签上面依次添加id、name、age 49 * 6、在id name age上面依次添加值 50 * */ 51 Document document = StudentUtils.getDocument(StudentUtils.PATH); 52 Element root = document.getRootElement(); 53 Element stu = root.addElement("stu"); 54 Element id1 = stu.addElement("id"); 55 Element name1 = stu.addElement("name"); 56 Element age1 = stu.addElement("age"); 57 id1.setText(student.getId()); 58 name1.setText(student.getName()); 59 age1.setText(student.getAge()); 60 StudentUtils.xmlWriters(StudentUtils.PATH,document); 61 } 62 //删除,根据学生的id删除 63 public static void delStu(String id) throws Exception{ 64 /* 65 * 1、创建解析器 66 * 2、得到document 67 * 3、获取所有的id 68 * 使用xpath //id 返回list集合 69 * 4、遍历list集合 70 * 5、判断集合里面的id和传递的id是否相同 71 * 6、如果相同,把id所在的stu删除 72 * */ 73 Document document = StudentUtils.getDocument(StudentUtils.PATH); 74 List<Node> list = document.selectNodes("//id"); 75 for (Node node : list) { 76 String idv = node.getText(); 77 if (idv.equals(id)) { 78 Element stu = node.getParent(); 79 Element student = stu.getParent(); 80 student.remove(stu); 81 } 82 } 83 StudentUtils.xmlWriters(StudentUtils.PATH,document); 84 } 85 }
StuService操作类:
1 package service; 2 import org.dom4j.Document; 3 import org.dom4j.DocumentException; 4 import org.dom4j.io.OutputFormat; 5 import org.dom4j.io.SAXReader; 6 import org.dom4j.io.XMLWriter; 7 import java.io.FileOutputStream; 8 import java.io.IOException; 9 10 public class StudentUtils { 11 public static final String PATH="src/student.xml"; 12 //返回document 13 public static Document getDocument(String path) { 14 try { 15 //创建解析器 16 SAXReader reader = new SAXReader(); 17 //得到document 18 Document document = reader.read(path); 19 return document; 20 } catch (DocumentException e) { 21 e.printStackTrace(); 22 } 23 return null; 24 } 25 //回写xml 26 public static void xmlWriters(String path,Document document) { 27 try { 28 OutputFormat format = OutputFormat.createPrettyPrint(); 29 XMLWriter xmlWriter = new XMLWriter(new FileOutputStream(path),format); 30 xmlWriter.write(document); 31 xmlWriter.close(); 32 } catch (IOException e) { 33 e.printStackTrace(); 34 } 35 } 36 }
3、构建对象的封装包,用于对象设置与获取。
1 package vo; 2 3 public class Student { 4 private String id; 5 private String name; 6 private String age; 7 public String getId() {return id; } 8 public String getName() {return name; } 9 public String getAge() { return age;} 10 public void setId(String id) {this.id = id;} 11 public void setName(String name) { this.name = name;} 12 public void setAge(String age) { this.age = age;} 13 14 @Override 15 public String toString() { 16 return "Student{" + 17 "id='" + id + '\'' + 18 ", name='" + name + '\'' + 19 ", age='" + age + '\'' + 20 '}'; 21 } 22 }
4、构建测试包
1 package test; 2 3 import service.StuService; 4 import vo.Student; 5 6 public class TestStu { 7 public static void main(String[] args) throws Exception{ 8 testSelect(); 9 // testAdd(); 10 // testDel(); 11 } 12 //测试查询方法 13 public static void testSelect() throws Exception { 14 Student stu = StuService.getStu("100"); 15 System.out.println(stu.toString()); 16 } 17 //测试添加方法 18 public static void testAdd() throws Exception { 19 Student stu = new Student(); 20 stu.setId("103"); 21 stu.setName("wanwu"); 22 stu.setAge("25"); 23 StuService.addStu(stu); 24 } 25 //测试添加方法 26 public static void testDel() throws Exception{ 27 StuService.delStu("103"); 28 } 29 }

