

一致性哈希组(Consistent Hashing) 算法及源码(二)一致性哈希组(Consistent Hashing)算法介绍
写在前面
一致性哈希组(Consistent Hashing) 算法及源码共分为三篇文章
(一)通过取模算法实现数据负载均衡
(二)一致性哈希组(Consistent Hashing)算法介绍
(三)一致性哈希组基于net core 的具体实现(附源码)
文章中涉及的具体架构设计及代码实现均由我们一位架构师完成,我有幸参与了其中一部分的开发和测试工作。
因架构师比较忙所以由我代为整理发布出来,希望和大家一起交流学习,逐渐完善。
结合上一篇文章中的疑问来简单介绍下如何通过一致性哈希组算法来实现负载均衡。(关于一致性Hash组算法原理网上已有好多文章进行过详细解释,如需要请百度进一步学习)。
取模算法是按照Hash后的结果对总节点数进行的取模,取模后的余数对应一个真实DB节点,一致性哈希组要有一个环的概念。
哈希函数
自定义一个Hash函数将每条数据输入的key转成一个int值。
哈希环
最小值:0
最大值:Hash函数返回的最大值作为Hash环的最大值。以保证每条记录Hash后的值都能够均匀落到这个环上。
暂时先将Int.MaxValue作为Hash环的最大值。
顺序:按照顺时针方向增长
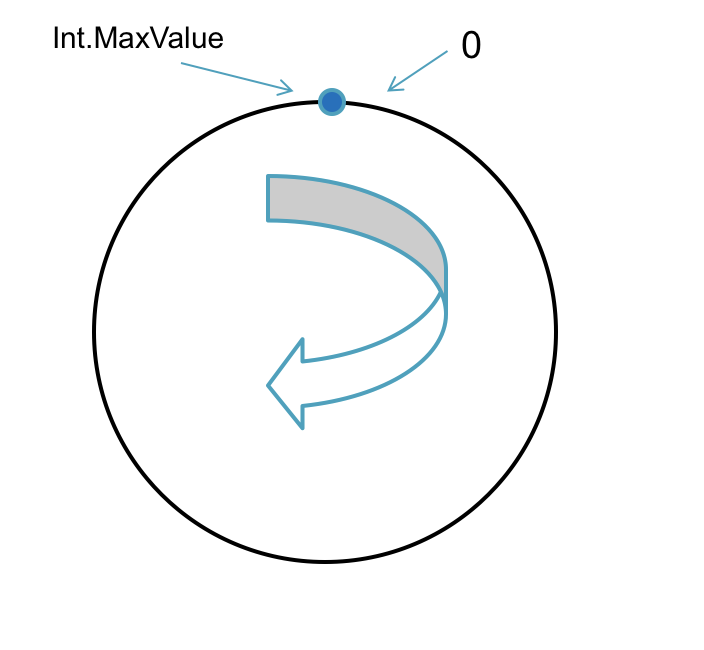
服务器节点需要均匀分布到Hash环上
假如我们有N台服务器,需要将这N台服务器均匀的分配到Hash环上。
每个服务器节点对应Hash环上的一个值。
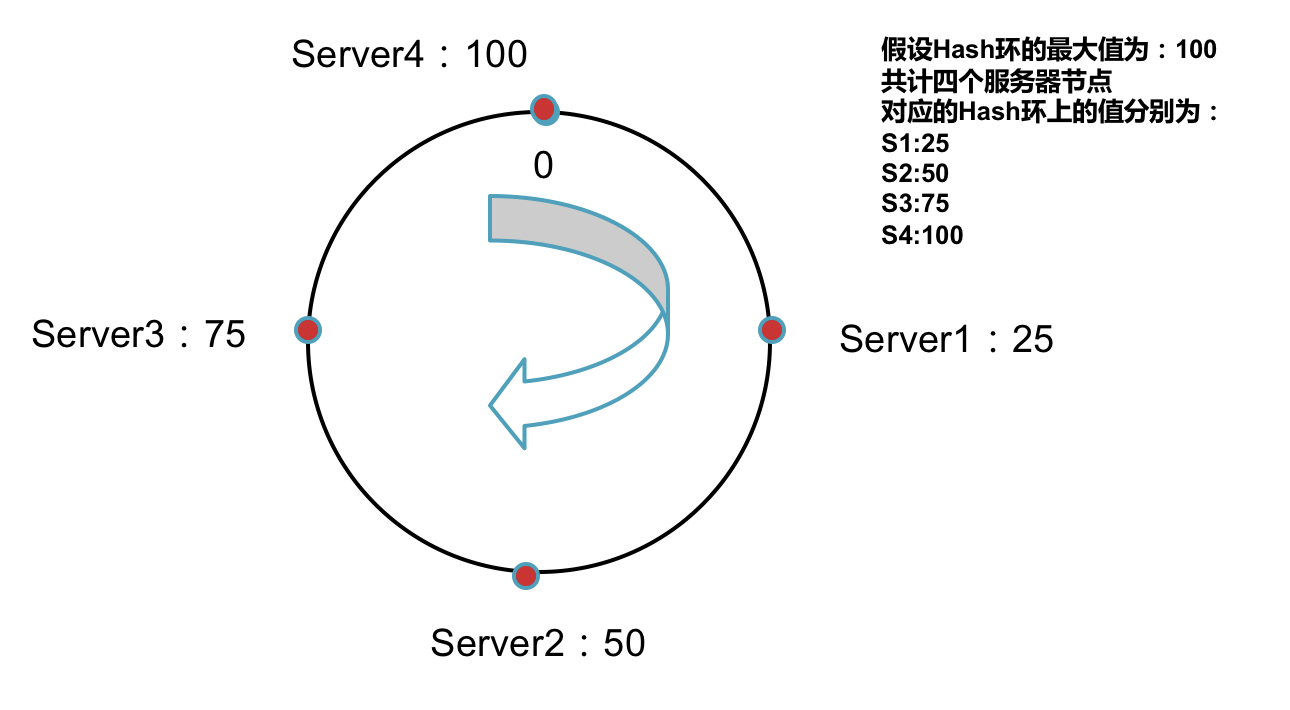
数据需要保存到距离自己最近的一个服务器节点上:
1,将数据通过Key值进行Hash计算。
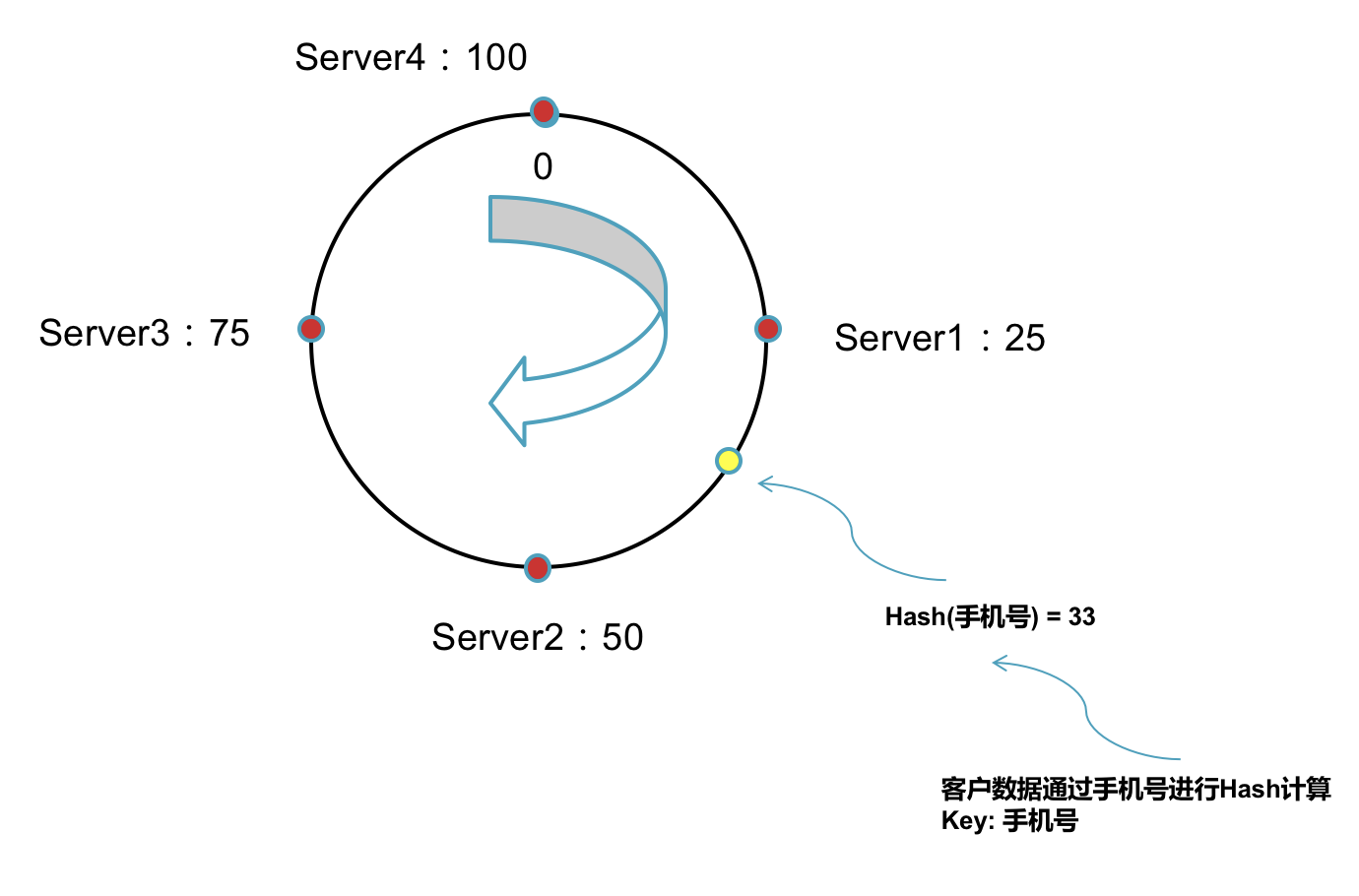
2,将Hash后的值在环上顺时针(逆时针也可以,只需保证全局一致)方向找到距离自己最近的一个服务器节点。
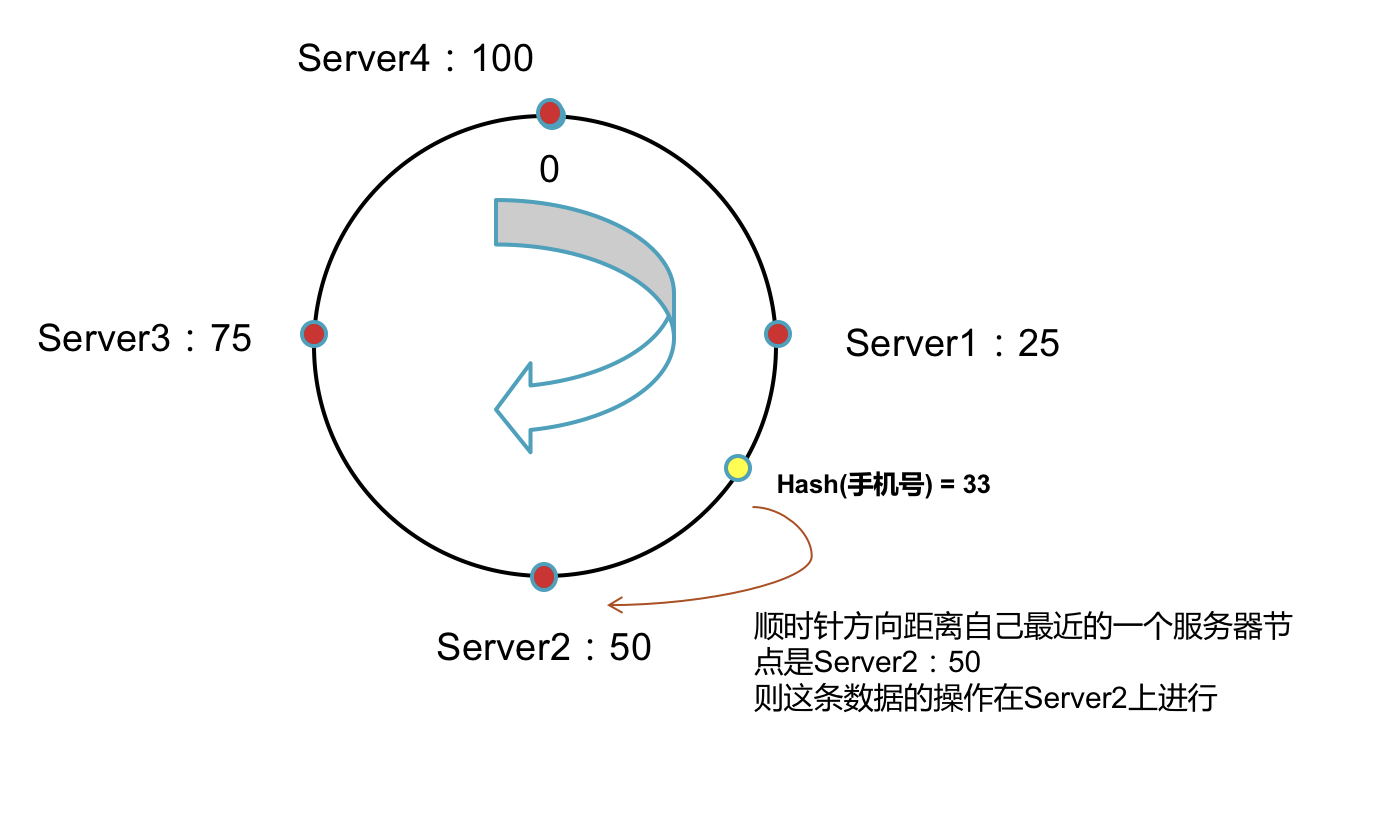
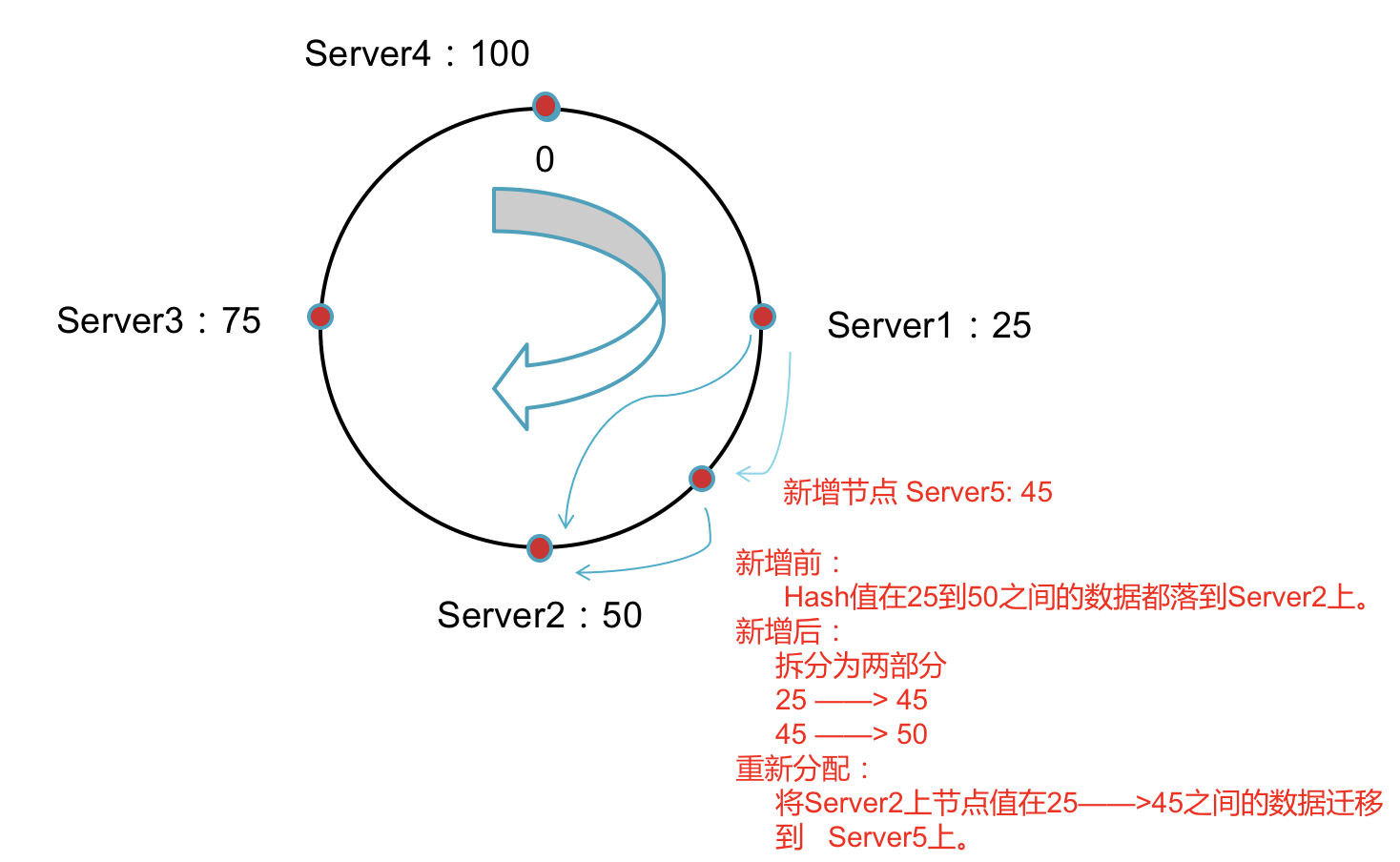
增加服务器节点后如何移动数据
新增节点后只需要将新节点的下一个节点上的数据重新进行分配,其他节点不受影响。
这样就解决了上篇文章中的问题: 1,在增减节点时如何保证对现有数据做最小的移动呢?
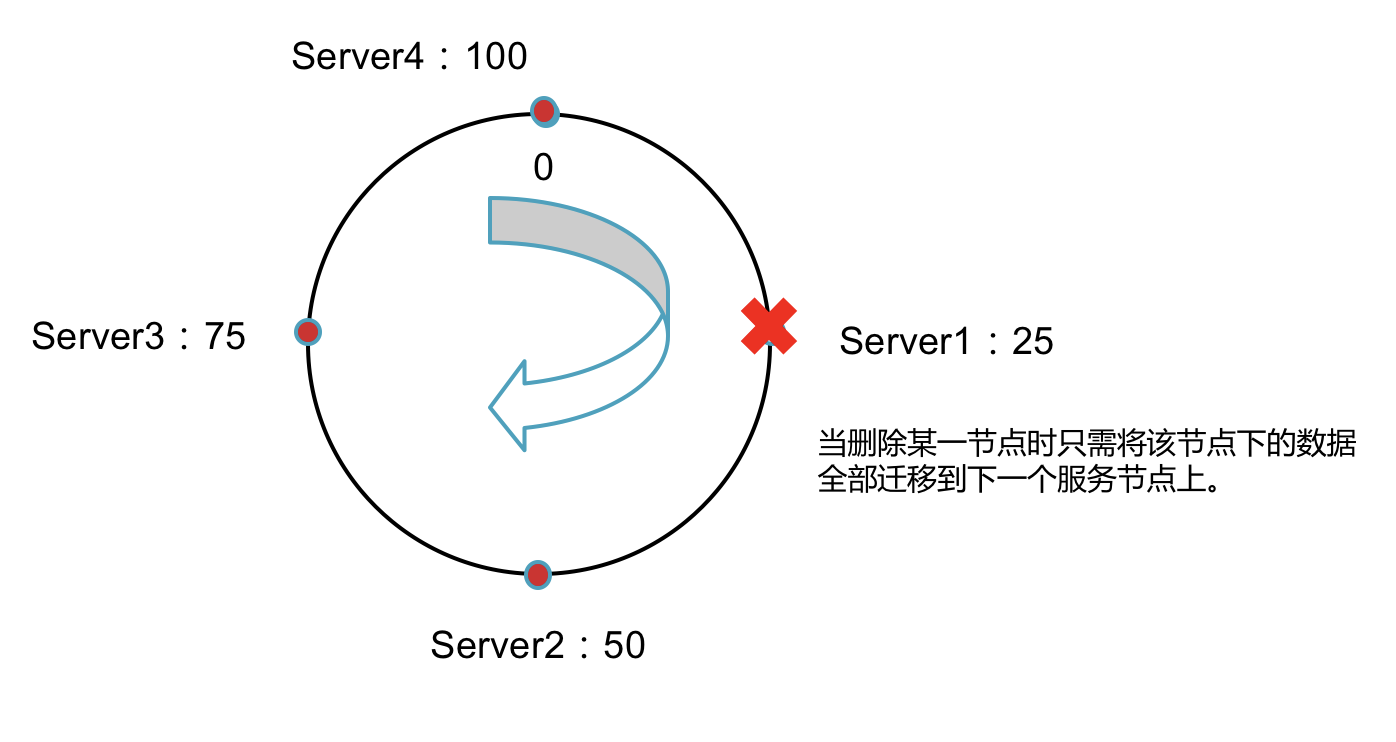
删除服务器节点后如何移动数据
删除服务节点后只需要将该节点中的数据全部移到距离最近的下一个节点上。
所以当某一个节点down掉之后不会存在新增数据时无法保存的现象,在down掉这段时间新增的数据依然会保存到下一个节点上。
这就解决了上篇文章中的问题 2,当其中某个节点down掉之后保存在该节点上的数据全部不能使用。
数据倾斜的产生
以上已经完整的介绍了一个Hash 环的算法逻辑,但是按照上面算法依然会存在落到每个服务器节点上的数据量不均匀,从而导致数据倾斜。
例如:Hash函数计算出来的结果跨度较小,没有均匀分布到Hash环上。
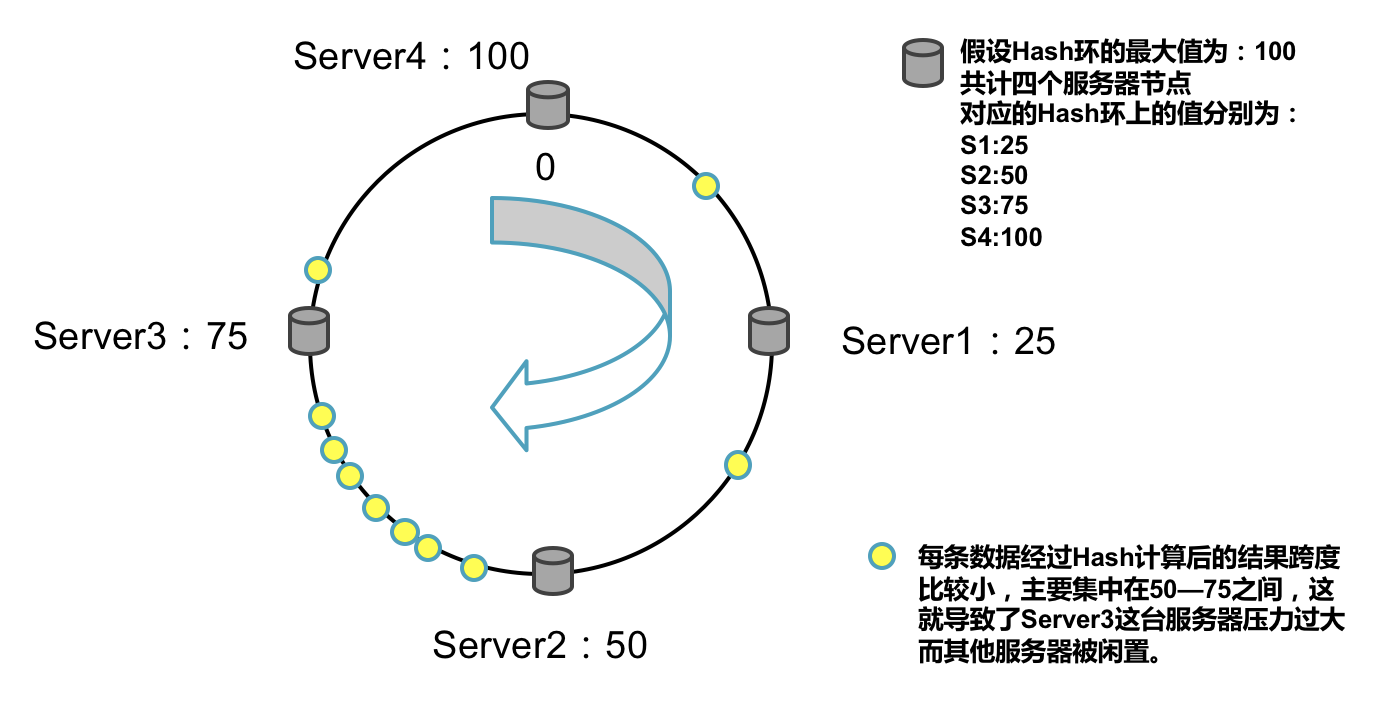
如何解决数据倾斜的问题呢?如果服务器节点足够多的话就能解决这个问题,但实际上服务器节点数量会受到各种原因的影响不会很多,所以我们接下来就要引入虚拟节点的概念。
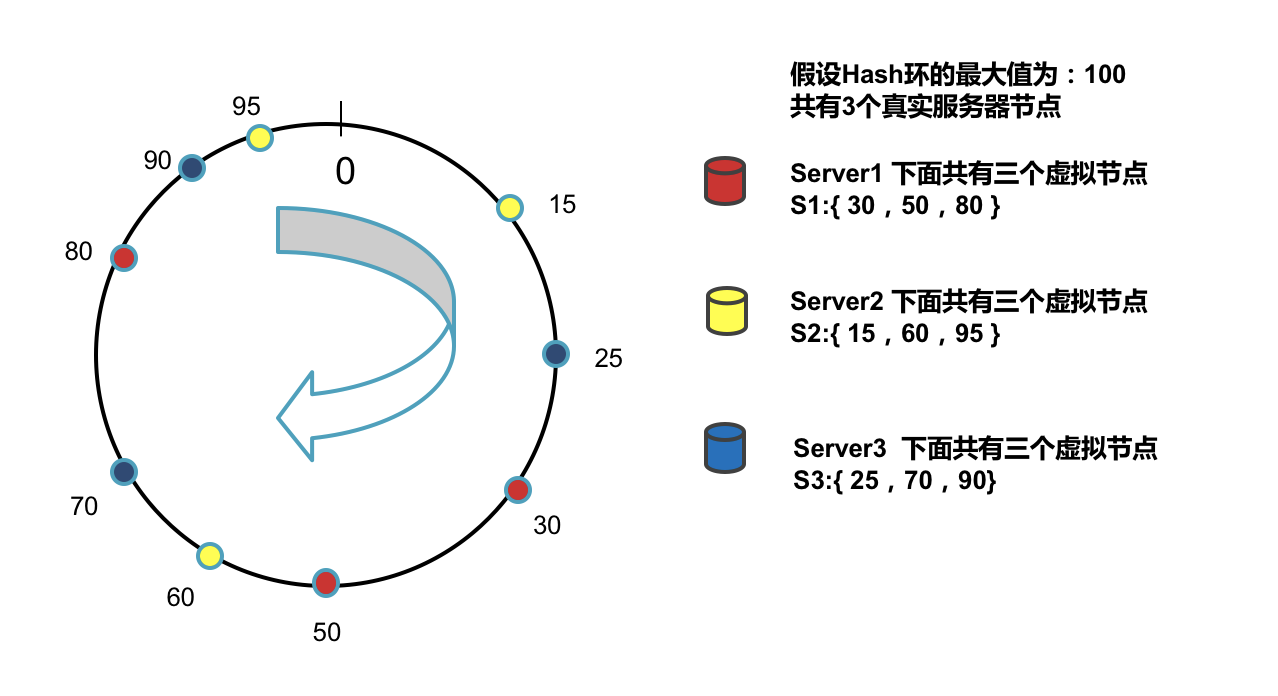
虚拟节点
顾名思义虚拟节点不是真实存在的,我们通过大量的虚拟节点尽量来均匀的拆分我们的Hash环。
1,每一个真实服务器节点都看作是一个HashRealNode。
2,每个HashRealNode下面有多个虚拟节点HashNode,虚拟节点在Hash环上是乱序排列的。
3,数据在存取时通过虚拟节点来找到所属的真实节点。
数据迁移服务:
通过虚拟节点虽然可以很好的解决数据倾斜问题但同时也会带来大量的数据迁移工作.
例如当我们追加或者删除服务节点时会影响到下面关联的N个虚拟节点,所以我们也需要写了一个数据迁移服务,专门针对这种情况。
源代码实现:
已通过net core 实现了以上所有设计,关于代码的具体架构及源代码下载地址请参考下篇文章:(三)一致性哈希组基于net core 的具体实现(附源码)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号