
MIT-6.824 lab1-MapReduce
概述
本lab将用go完成一个MapReduce框架,完成后将大大加深对MapReduce的理解。
Part I: Map/Reduce input and output
这部分需要我们实现common_map.go中的doMap()和common_reduce.go中的doReduce()两个函数。
可以先从测试用例下手:
func TestSequentialSingle(t *testing.T) {
mr := Sequential("test", makeInputs(1), 1, MapFunc, ReduceFunc)
mr.Wait()
check(t, mr.files)
checkWorker(t, mr.stats)
cleanup(mr)
}
从Sequential()开始调用链如下:
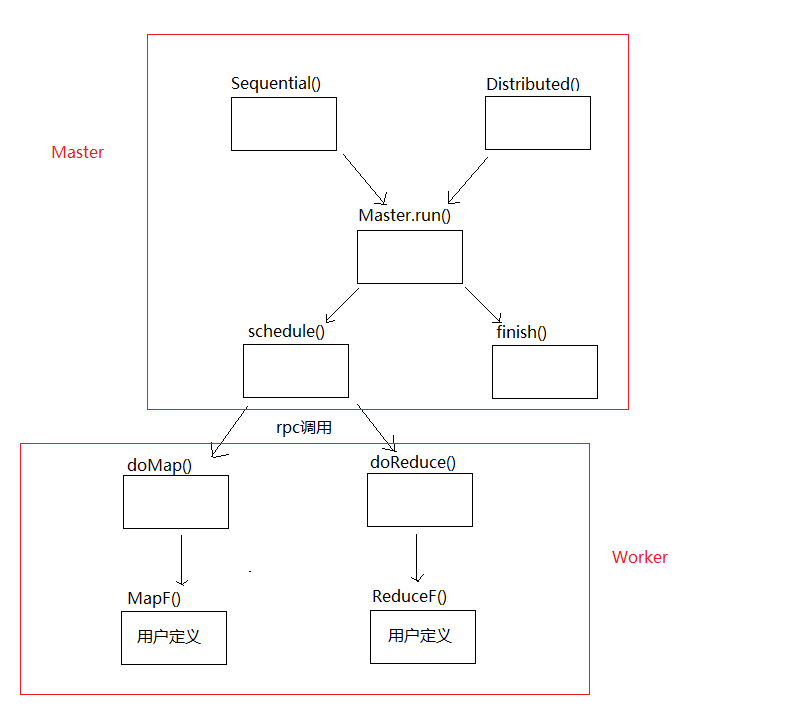
现在要做的是完成doMap()和doReduce()。
doMap():
func doMap(
jobName string, // the name of the MapReduce job
mapTask int, // which map task this is
inFile string,
nReduce int, // the number of reduce task that will be run ("R" in the paper)
mapF func(filename string, contents string) []KeyValue,
) {
//打开inFile文件,读取全部内容
//调用mapF,将内容转换为键值对
//根据reduceName()返回的文件名,打开nReduce个中间文件,然后将键值对以json的格式保存到中间文件
inputContent, err := ioutil.ReadFile(inFile)
if err != nil {
panic(err)
}
keyValues := mapF(inFile, string(inputContent))
var intermediateFileEncoders []*json.Encoder
for reduceTaskNumber := 0; reduceTaskNumber < nReduce; reduceTaskNumber++ {
intermediateFile, err := os.Create(reduceName(jobName, mapTask, reduceTaskNumber))
if err != nil {
panic(err)
}
defer intermediateFile.Close()
enc := json.NewEncoder(intermediateFile)
intermediateFileEncoders = append(intermediateFileEncoders, enc)
}
for _, kv := range keyValues {
err := intermediateFileEncoders[ihash(kv.Key) % nReduce].Encode(kv)
if err != nil {
panic(err)
}
}
}
总结来说就是:
- 读取输入文件内容
- 将内容交个用户定义的Map函数执行,生成键值对
- 保存键值对
doReduce:
func doReduce(
jobName string, // the name of the whole MapReduce job
reduceTask int, // which reduce task this is
outFile string, // write the output here
nMap int, // the number of map tasks that were run ("M" in the paper)
reduceF func(key string, values []string) string,
) {
//读取当前reduceTaskNumber对应的中间文件中的键值对,将相同的key的value进行并合
//调用reduceF
//将reduceF的结果以json形式保存到mergeName()返回的文件中
kvs := make(map[string][]string)
for mapTaskNumber := 0; mapTaskNumber < nMap; mapTaskNumber++ {
midDatafileName := reduceName(jobName, mapTaskNumber, reduceTask)
file, err := os.Open(midDatafileName)
if err != nil {
panic(err)
}
defer file.Close()
dec := json.NewDecoder(file)
for {
var kv KeyValue
err = dec.Decode(&kv)
if err != nil {
break
}
values, ok := kvs[kv.Key]
if ok {
kvs[kv.Key] = append(values, kv.Value)
} else {
kvs[kv.Key] = []string{kv.Value}
}
}
}
outputFile, err := os.Create(outFile)
if err != nil {
panic(err)
}
defer outputFile.Close()
enc := json.NewEncoder(outputFile)
for key, values := range kvs {
enc.Encode(KeyValue{key, reduceF(key, values)})
}
}
总结:
- 读取中间数据
- 执行reduceF
- 保存结果
文件转换的过程大致如下:
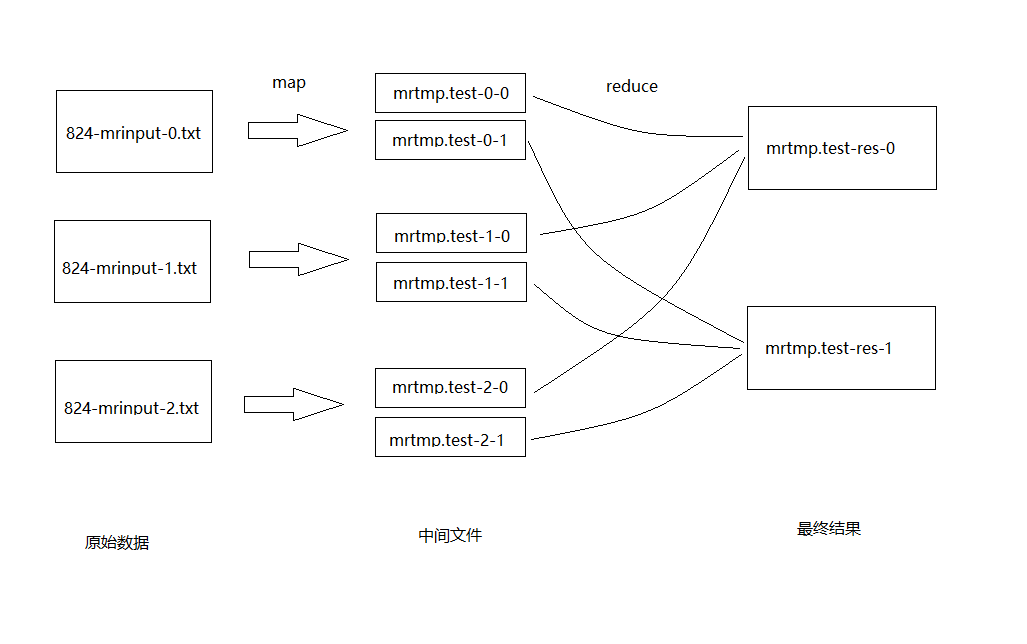
Part II: Single-worker word count
这部分将用一个简单的实例展示如何使用MR框架。需要我们实现main/wc.go中的mapF()和reduceF()来统计单词的词频。
mapF:
func mapF(filename string, contents string) []mapreduce.KeyValue {
// Your code here (Part II).
words := strings.FieldsFunc(contents, func(r rune) bool {
return !unicode.IsLetter(r)
})
var kvs []mapreduce.KeyValue
for _, word := range words {
kvs = append(kvs, mapreduce.KeyValue{word, "1"})
}
return kvs
}
将文本内容分割成单词,每个单词对应一个<word, "1">键值对。
reduceF:
func reduceF(key string, values []string) string {
// Your code here (Part II).
return strconv.Itoa(len(values))
}
value中有多少个"1",就说明这个word出现了几次。
Part III: Distributing MapReduce tasks
目前实现的版本都是执行完一个map然后在执行下一个map,也就是说没有并行,这恰恰是MapReduce最大的买点。这部分需要实现schedule(),该函数将任务分配给Worker去执行。当然这里并没有真正的多机部署,而是使用多线程进行模拟。
master和worker的关系大致如下:
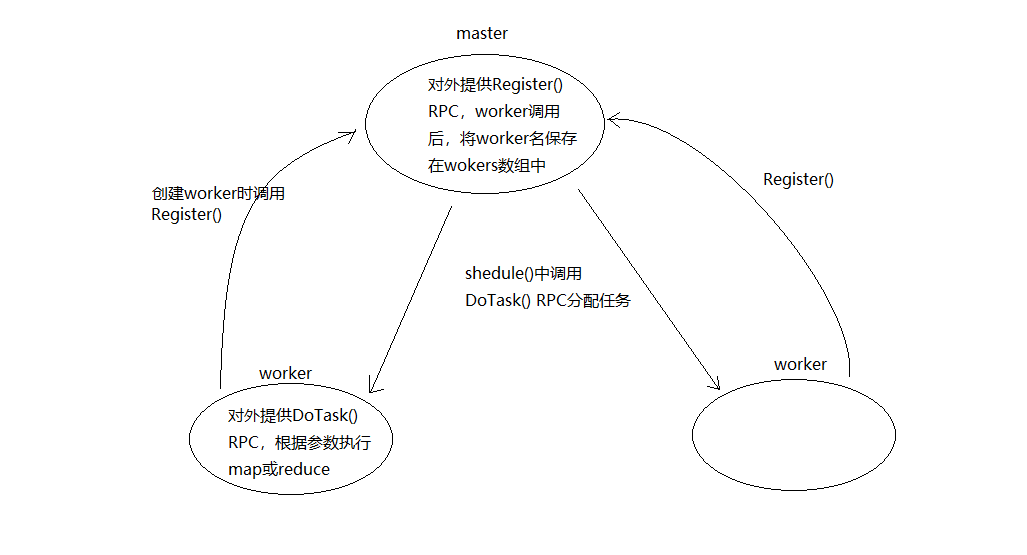
在创建worker对象的时候会调用Register() RPC,master收到RPC后,将该worker的id保存在数组中,执行shedule()是可以根据该id,通过DoTask() RPC调用该worker的DoTask()执行map或reduce任务。
schedule.go
func schedule(jobName string, mapFiles []string, nReduce int, phase jobPhase, registerChan chan string) {
var ntasks int
var n_other int // number of inputs (for reduce) or outputs (for map)
switch phase {
case mapPhase:
ntasks = len(mapFiles)
n_other = nReduce
case reducePhase:
ntasks = nReduce
n_other = len(mapFiles)
}
fmt.Printf("Schedule: %v %v tasks (%d I/Os)\n", ntasks, phase, n_other)
//总共有ntasks个任务,registerChan中保存着空闲的workers
taskChan := make(chan int)
var wg sync.WaitGroup
go func() {
for taskNumber := 0; taskNumber < ntasks; taskNumber++ {
taskChan <- taskNumber
fmt.Printf("taskChan <- %d in %s\n", taskNumber, phase)
wg.Add(1)
}
wg.Wait() //ntasks个任务执行完毕后才能通过
close(taskChan)
}()
for task := range taskChan { //所有任务都处理完后跳出循环
worker := <- registerChan //消费worker
fmt.Printf("given task %d to %s in %s\n", task, worker, phase)
var arg DoTaskArgs
arg.JobName = jobName
arg.Phase = phase
arg.TaskNumber = task
arg.NumOtherPhase = n_other
if phase == mapPhase {
arg.File = mapFiles[task]
}
go func(worker string, arg DoTaskArgs) {
if call(worker, "Worker.DoTask", arg, nil) {
//执行成功后,worker需要执行其它任务
//注意:需要先掉wg.Done(),然后调register<-worker,否则会出现死锁
//fmt.Printf("worker %s run task %d success in phase %s\n", worker, task, phase)
wg.Done()
registerChan <- worker //回收worker
} else {
//如果失败了,该任务需要被重新执行
//注意:这里不能用taskChan <- task,因为task这个变量在别的地方可能会被修改。比如task 0执行失败了,我们这里希望
//将task 0重新加入到taskChan中,但是因为执行for循环的那个goroutine,可能已经修改task这个变量为1了,我们错误地
//把task 1重新执行了一遍,并且task 0没有得到执行。
taskChan <- arg.TaskNumber
}
}(worker, arg)
}
fmt.Printf("Schedule: %v done\n", phase)
}
这里用到了两个channel,分别是registerChan和taskChan。
registerChan中保存了可用的worker id。
生产:
- worker调用Register()进行注册,往里添加
- worker成功执行DoTask()后,该worker需要重新加入registerChan
消费:
- schedule()拿到一个任务后,消费registerChan
taskChan中保存了任务号。任务执行失败需要重新加入taskChan。
Part IV: Handling worker failures
之前的代码已经体现了,对于失败的任务重新执行。
Part V: Inverted index generation
这是MapReduce的一个应用,生成倒排索引,比如想查某个单词出现在哪些文本中,就可以建立倒排索引来解决。
func mapF(document string, value string) (res []mapreduce.KeyValue) {
// Your code here (Part V).
words := strings.FieldsFunc(value, func(r rune) bool {
return !unicode.IsLetter(r)
})
var kvs []mapreduce.KeyValue
for _, word := range words {
kvs = append(kvs, mapreduce.KeyValue{word, document})
}
return kvs
}
func reduceF(key string, values []string) string {
// Your code here (Part V).
values = removeDuplicationAndSort(values)
return strconv.Itoa(len(values)) + " " + strings.Join(values, ",")
}
func removeDuplicationAndSort(values []string) []string {
kvs := make(map[string]struct{})
for _, value := range values {
_, ok := kvs[value]
if !ok {
kvs[value] = struct{}{}
}
}
var ret []string
for k := range kvs {
ret = append(ret, k)
}
sort.Strings(ret)
return ret
}
mapF()生成<word, document>的键值对,reduceF()处理word对应的所有document,去重并且排序,然后拼接到一起。
具体代码在:https://github.com/gatsbyd/mit_6.824_2018
如有错误,欢迎指正:
15313676365

