并发编程-多进程
一.进程
新进程的创建都是由一个已经存在的进程执行了一个用于创建进程的系统调用而创建的。
1.在UNIX中:fork会创建一个与父进程一摸一样的副本
2.在Windows:系统调用CreateProcess创建进程
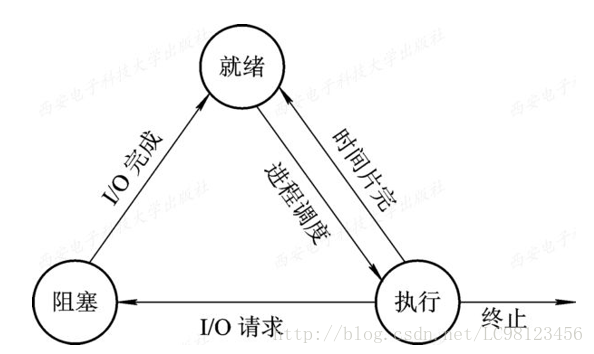
进程的状态
程序遇到IO操作(Input、output),会阻塞,IO完成会进入就绪状态,此时等待cpu执行。正在执行的程序时间片完(cpu切到其他程序执行),会进入就绪状态。
1.进程创建方式
在windows环境下,开启进程必须在 if __name__ == "__main__"下


from multiprocessing import Process import time def task(name): print(f"{name} is running") time.sleep(3) print(f"{name} is gone") if __name__ == '__main__': p = Process(target=task,args=("alex",)) # 指定 这个线程去哪个函数里面去执行代码 p.start() #只是向操作系统发出一个开辟子进程的信号(由cpu执行进程中额任务),然后就执行下一行了 print("__main__") #操作系统在接受到信号之后,会在内存中开辟一个进程空间(新建一个子进程py文件),然后将主进程所有数据copy到子进程(相当于在子进程py文件中import主进程的所有内容,那么if __name__ == "__main__"下面的不会导过来),然后调用线程执行。 #开辟子进程的开销很大(时间很长),所以永远会执行主进程的代码。
from multiprocessing import Process import time class MyProcess(Process): def run(self): print(f"{self.name} is running") time.sleep(3) print(f"{self.name} is end") if __name__ == '__main__': p = MyProcess() p.start() # 会自动执行run方法(run方法相当于上面的task函数) print("__main__") #Process类中有name属性,默认为类名加上-1(MyProcess-1),每次新建一个子进程就MyProcess-2、MyProcess-3...
二.进程pid
在pycharm中,父进程为pycharm,子进程为pycharm调用的python解释器。
import os import time print(f"子进程:{os.getpid()}") #运行此py文件的python解释器的pid print(f"父进程":{os.getppid()}) #当前pycharm的pid
from multiprocessing import Process import time import os def task(name): print(f'子进程:{os.getpid()}') print(f'主进程:{os.getppid()}') if __name__ == '__main__': p = Process(target=task,args=('常鑫',)) # 创建一个进程对象 p.start() # print('==主开始') print(f'====主{os.getpid()}')
在cmd中,父进程为cmd,子进程为cmd调用的python解释器
import os import time print(f'子进程:{os.getpid()}') print(f'主(父)进程:{os.getppid()}') time.sleep(50)
三.进程之间的空间隔离
进程之间相互隔离,是不能互相修改数据的
from multiprocessing import Process import time name = '太白' def task(): global name name = '刚子sb' print(f'子进程{name}') if __name__ == '__main__': p = Process(target=task) # 创建一个进程对象 p.start() time.sleep(3) print(f'主:{name}') #打印结果 #子进程刚子sb #主:太白
四.join
join就是阻塞,只有join执行完,才会执行join下面的主进程代码
from multiprocessing import Process import time def task1(name): print(f"{name} is running") time.sleep(1) print(f"{name} is gone") def task2(name): print(f"{name} is running") time.sleep(2) print(f"{name} is gone") def task3(name): print(f"{name} is running") time.sleep(3) print(f"{name} is gone") if __name__ == '__main__': start_time = time.time() p1 = Process(target=task1,args=("alex",)) p2 = Process(target=task2,args=('egon',)) p3 = Process(target=task3,args=('meet',)) p1.start() p2.start() p3.start() p1.join() p2.join() p3.join() print(time.time() - start_time) 打印结果 alex is running egon is running meet is running alex is gone egon is gone meet is gone 3.101801872253418 #我们看到,只执行了3s左右,因为p1.start(),p2.start(),p3.start()三个相当于并发执行,p1.join()执行的过程中p2,p3也会执行,其实就是并发。
from multiprocessing import Process import time def task1(name): print(f"{name} is running") time.sleep(1) print(f"{name} is gone") def task2(name): print(f"{name} is running") time.sleep(2) print(f"{name} is gone") def task3(name): print(f"{name} is running") time.sleep(3) print(f"{name} is gone") if __name__ == '__main__': start_time = time.time() p1 = Process(target=task1,args=("alex",)) p2 = Process(target=task2,args=('egon',)) p3 = Process(target=task3,args=('meet',)) p1.start() p2.start() p3.start() p1.join() print("p1") p2.join() print("p2") p3.join() print("p3") print(time.time() - start_time) 打印结果: alex is running egon is running meet is running alex is gone p1 #1s执行打印p1 egon is gone p2 #第2s执行打印p2,因为p2已经执行了1s meet is gone p3 3.1154708862304688
from multiprocessing import Process import time,random def task(): print("task begin") time.sleep(random.randint(1,2)) print("task end") if __name__ == '__main__': start_time = time.time() for i in range(3): p = Process(target=task) p.start() p.join() print("__main__") print(time.time() - start_time) # 上述例子为串行,每start()一次,就join一次,我们都知道,有join会等到join完成后再执行下面的代码。正确例子如下: from multiprocessing import Process import time,random def task(): print("task begin") time.sleep(random.randint(1,2)) print("task end") if __name__ == '__main__': start_time = time.time() lst = [] for i in range(3): p = Process(target=task) lst.append(p) p.start() for j in lst: j.join() print("__main__") print(time.time() - start_time)
五.进程的其他参数
from multiprocessing import Process import time def task(name): print(f'{name} is running') time.sleep(2) print(f'{name} is gone') if __name__ == '__main__': # 在windows环境下, 开启进程必须在 __name__ == '__main__' 下面 # p = Process(target=task,args=('常鑫',)) # 创建一个进程对象 p = Process(target=task,args=('常鑫',),name='alex') # 创建一个进程对象 p.start() time.sleep(1) p.terminate() # 杀死子进程(可以理解为发送信号,需要时间) *** p.join() # *** time.sleep(0.5) print(p.is_alive()) # 查看进程是否存活*** print(p.name) # 默认属性 p.name = 'sb' print(p.name) print('==主开始')
六.僵尸进程和孤儿进程
基于UNIX环境(linux,macOs)
一.僵尸进程(有害)
1.定义:一个进程使用fork创建子进程,如果子进程退出,而父进程没有调用wait或waitpid获取子进程的状态信息,那么子进程的进程描述符仍然存在系统中,这种进程称之为僵尸进程。
2.主进程和子进程的运行是异步状态。主进程时刻检测子进程的运行状态,当子进程结束之后,一段时间之后,将子进程进行回收。
3.为什么主进程不在子进程结束后马上对其进行回收?
主进程和子进程是异步关系,主进程无法马上捕获子进程什么时候结束。
如果子进程结束之后马上释放资源,主进程就没有办法监测子进程的状态。
4.UNIX针对保证父进程能获取子进程的状态信息提供一个机制
所有的子进程结束之后,会立刻释放内存的大部分数据,但是保留一些内容:进程号,结束时间,运行状态,等待主进程监测,回收
5.所有的子进程结束之后,在被主进程回收之前,都会进入僵尸进程状态。
6.危害:如果父进程不对僵尸进程进行回收(wait/waitpid),会产生大量的僵尸进程,占用pid号。
7.僵尸进程解决:
1.杀死父进程,将所有的僵尸进程变成孤儿进程,从而被init进程回收。
2.使用join,join会调用父进程的wait方法,回收僵尸进程。
二.孤儿进程(无害)
1.定义:一个父进程退出(cmd执行taskkill命令),它的某些子进程还在运行,那么这些子进程将成为孤儿进程。孤儿进程将被init进程收养,并对其进行状态收集工作。
二.守护进程
p.daemon = True,将子进程p设置为守护进程,只要主进程结束(严格来说应该是主进程中的任务执行完,而非主进程结束),守护进程也跟着结束
p.daemon = True,必须在p.start()之前设置,因为一旦开启子进程,再设置也没用
from multiprocessing import Process import time def task(name): print(f'{name} is running') time.sleep(2) print(f'{name} is gone') if __name__ == '__main__': p = Process(target=task,args=('常鑫',)) # 创建一个进程对象 p.daemon = True # 将p子进程设置成守护进程,只要主进程结束,守护进程马上结束(print('===主')一打印完,主进程中没有要执行的任务了,守护进程就死掉) p.start() time.sleep(1) print('===主')
from multiprocessing import Process from threading import Thread import time def foo(): print(123) time.sleep(2) print("end123") def bar(): print(456) time.sleep(3) print("end456") if __name__ == '__main__': p1=Process(target=foo) p2=Process(target=bar) p1.daemon=True p1.start() p2.start() print("main-------") #打印完这句代码守护进程也跟着完了,不是等到整个流程结束守护进程才完 ''' main------- 456 end456 '''
三.进程同步(锁)
强调:必须是lock.acquire()一次,然后 lock.release()释放一次,才能继续lock.acquire(),不能连续的lock.acquire()
互斥锁vs join的区别一:
大前提:二者的原理都是一样,都是将并发变成串行,从而保证有序
区别:join是按照人为指定的顺序执行,而互斥锁是所以进程平等地竞争,谁先抢到谁执行
# 三个同事 同时用一个打印机打印内容. # 三个进程模拟三个同事, 输出平台模拟打印机. # # 版本一: from multiprocessing import Process import time import random import os def task1(): print(f'{os.getpid()}开始打印了') time.sleep(random.randint(1,3)) print(f'{os.getpid()}打印结束了') def task2(): print(f'{os.getpid()}开始打印了') time.sleep(random.randint(1,3)) print(f'{os.getpid()}打印结束了') def task3(): print(f'{os.getpid()}开始打印了') time.sleep(random.randint(1,3)) print(f'{os.getpid()}打印结束了') if __name__ == '__main__': p1 = Process(target=task1) p2 = Process(target=task2) p3 = Process(target=task3) p1.start() p2.start() p3.start()
from multiprocessing import Process import time import random import os def task1(p): print(f'{p}开始打印了') time.sleep(random.randint(1,3)) print(f'{p}打印结束了') def task2(p): print(f'{p}开始打印了') time.sleep(random.randint(1,3)) print(f'{p}打印结束了') def task3(p): print(f'{p}开始打印了') time.sleep(random.randint(1,3)) print(f'{p}打印结束了') if __name__ == '__main__': p1 = Process(target=task1,args=('p1',)) p2 = Process(target=task2,args=('p2',)) p3 = Process(target=task3,args=('p3',)) p2.start() p2.join() p1.start() p1.join() p3.start() p3.join()
from multiprocessing import Process from multiprocessing import Lock import time import random import os def task1(p,lock): ''' 一把锁不能连续锁两次 lock.acquire() lock.acquire() lock.release() lock.release() ''' lock.acquire() print(f'{p}开始打印了') time.sleep(random.randint(1,3)) print(f'{p}打印结束了') lock.release() def task2(p,lock): lock.acquire() print(f'{p}开始打印了') time.sleep(random.randint(1,3)) print(f'{p}打印结束了') lock.release() def task3(p,lock): lock.acquire() print(f'{p}开始打印了') time.sleep(random.randint(1,3)) print(f'{p}打印结束了') lock.release() if __name__ == '__main__': mutex = Lock() p1 = Process(target=task1,args=('p1',mutex)) p2 = Process(target=task2,args=('p2',mutex)) p3 = Process(target=task3,args=('p3',mutex)) p2.start() p1.start() p3.start()
四.进程间通信
我们知道,进程之间内存隔离,是不能共享内存中的数据的(例:py文件中的数据),但是可以共享磁盘上的文件。
1.基于文件通信

这里利用抢票举例子:在多个进程修改一个数据资源时,要保证顺序,一定要串行。如在抢票过程中,查看票应该并发,抢票(写入文件)应该串行。
文件实现进程间通信缺点:
1.效率低(共享数据基于文件,而文件是硬盘上的数据)
2.需要自己加锁处理。
from multiprocessing import Process from multiprocessing import Lock import json import time import os import random def search(): time.sleep(random.randint(1,3)) # 模拟网络延迟(查询环节) with open('ticket.json',encoding='utf-8') as f1: dic = json.load(f1) print(f'{os.getpid()} 查看了票数,剩余{dic["count"]}') def paid(): with open('ticket.json', encoding='utf-8') as f1: dic = json.load(f1) if dic['count'] > 0: dic['count'] -= 1 time.sleep(random.randint(1,3)) # 模拟网络延迟(购买环节) with open('ticket.json', encoding='utf-8',mode='w') as f1: json.dump(dic,f1) print(f'{os.getpid()} 购买成功') def task(lock): search() lock.acquire() paid() lock.release() if __name__ == '__main__': mutex = Lock() for i in range(6): p = Process(target=task,args=(mutex,)) p.start()
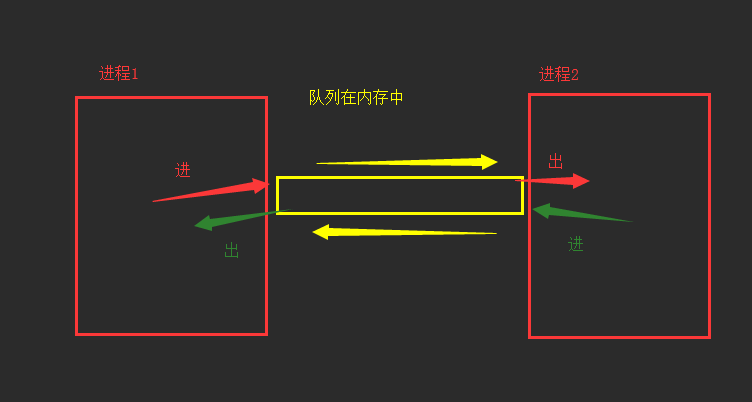
2.基于队列通信
进程之间互相隔离,要实现进程间通信(IPC,此机制帮我们自动处理锁的问题),multiprocessing支持两种形式:队列和管道,这两种消息都是使用消息传递。
队列(管道+锁实现):先进先出
from multiprocessing import Process,Queue
# 进程之间队列通信通过multiprocessing模块下的Queue
参数:
q = Queue(3) # 管道中最多容纳3个元素
q.put(block=False) # 如果管道设置最大容量,超过了且block=False,则报错
q.put(block=True) # 超过最大容量,阻塞
q.get(block=True) # 默认设置,get不到就阻塞
q.get(block=False) # get不到就报错
q.get(timeout=3) #超过3s就报错
生产者消费者模型(基于队列通信):
实现生产者消费者模型三要素 1、生产者 2、消费者 3、队列 什么时候用该模型: 程序中出现明显的两类,一类任务是负责生产,另外一类任务是负责处理生产的数据的 该模型的好处: 1、实现了生产者与消费者解耦和 2、平衡了生产力与消费力,即生产者可以一直不停地生产,消费者可以不停地处理,因为二者不再直接沟通的,而是跟队列沟通
from multiprocessing import Process,Queue import time,random,os def consumer(q): while True: res=q.get() time.sleep(random.randint(1,3)) print('\033[45m%s 吃 %s\033[0m' %(os.getpid(),res)) def producer(q): for i in range(10): time.sleep(random.randint(1,3)) res='包子%s' %i q.put(res) print('\033[44m%s 生产了 %s\033[0m' %(os.getpid(),res)) if __name__ == '__main__': q=Queue() #生产者们:即厨师们 p1=Process(target=producer,args=(q,)) #消费者们:即吃货们 c1=Process(target=consumer,args=(q,)) #开始 p1.start() c1.start() print('主') 生产者消费者模型


