在Spark程序中使用压缩
当大片连续区域进行数据存储并且存储区域中数据重复性高的状况下,数据适合进行压缩。数组或者对象序列化后的数据块可以考虑压缩。所以序列化后的数据可以压缩,使数据紧缩,减少空间开销。
1. Spark对压缩方式的选择
压缩采用了两种算法:Snappy和LZF,底层分别采用了两个第三方库实现,同时可以自定义其他压缩库对Spark进行扩展。Snappy提供了更高的压缩速度,LZF提供了更高的压缩比,用户可以根据具体需求选择压缩方式。
压缩格式及解编码器如下。
·LZF:org.apache.spark.io.LZFCompressionCodec。
·Snappy:org.apache.spark.io.SnappyCompressionCodec。
压缩算法的对比,如图4-9所示。
(1)Ning-Compress
Ning-compress是一个对数据进行LZF格式压缩和解压缩的库,这个库是TatuSaloranta(tatu.saloranta@iki .fi)书写的。用户可以在Github地址:https://github.com/ning/compress下载,进行学习和研究。
(2)snappy-java
Snappy算法的前身是Zippy,被Google用于MapReduce、BigTable等许多内部项目。snappy-java由谷歌开发,是以C++开发的Snappy压缩解压缩库的Java分支。Github地址为:https://github.com/xerial /snappy-java。
Snappy的目标是在合理的压缩量情况下,提供高压缩速度的库。因此Snappy的压缩比和LZF差不多,并不是很高。根据数据集的不同,压缩比能达到20%~100%。有兴趣的读者可以看一个压缩算法Benchmark,它对基于JVM运行语言的压缩库进行对比。这个Benchmark对snappy-java和其他压缩工具LZO-java/LZF/Qui ckLZ/Gzip/Bzip2进行了比较。地址为Github:https://github.com/ning/jvm-compressor-benchmark/wiki。这个Benchmark是由Tatu Saloranta@cotowncoder开发的。Snappy通常在达到相当压缩的情况下,要比同类的LZO、LZF、FastLZ和Qui ckLZ等快速的压缩算法快。它对纯文本的压缩比大概是1.5~1.7x,对HTML网页是2~4x,对图片等二进制数据基本没有压缩,为1x。Snappy分别对64位和32位处理器进行了优化,不论是32位处理,还是64位处理器,都能达到很高的效率。据官方介绍,Snappy经过PB级别的大数据的考验,稳定性方面没有问题,Google的map reduce、rpc等很多框架都用到了Snappy压缩算法。
压缩是在时间和空间上的一种权衡。更长的压缩和解压缩时间会节省更多的空间。而空间占用少意味着可以缓存更多的数据,节省I/O时间和网络传输时间。不同的压缩算法是在不同情境的一种权衡,而且对不同数据类型文件进行压缩又会产生差异。可以参考图4-9,对不同算法的使用进行权衡。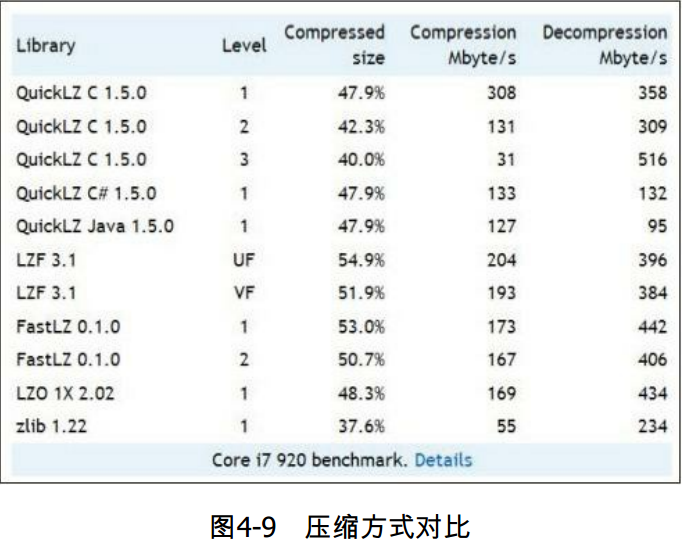
2. 在Spark程序中使用压缩
用户可以通过下面两种方式配置压缩。
(1)在Spark-env.sh文件中配置
用户可以在启动前配置文件spark-env.sh设定压缩配置的参数。
export SPARK_JAVA_OPTS="-Dspark.broadcast.compress"
(2)在应用程序中配置
sc是SparkContext对象,conf是SparkConf对象。
val conf=sc.getConf
1)获取压缩的配置。
conf.getBoolean("spark.broadcast.compress",true)
2)压缩的配置。
conf.set("spark.broadcast.compress",true)
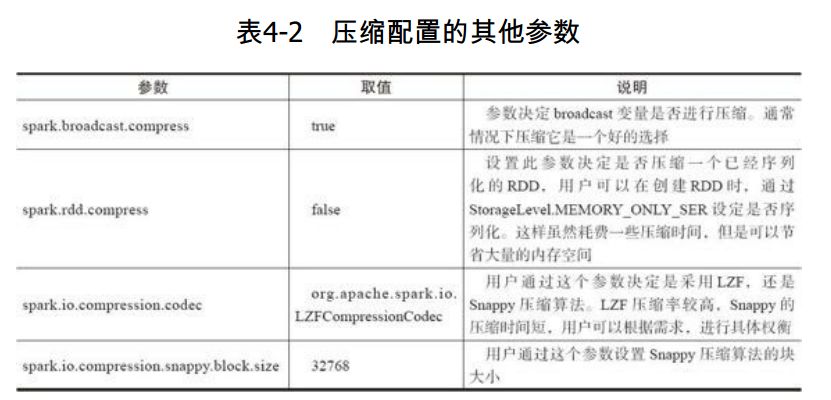
其他参数如表4-2所示:
在分布式计算中,序列化和压缩是两个重要的手段。Spark通过序列化将链式分布的数据转化为连续分布的数据,这样就能够进行分布式的进程间数据通信,或者在内存进行数据压缩等操作,提升Spark的应用性能。通过压缩,能够减少数据的内存占用,以及IO和网络数据传输开销。
